Multimodal Unsupervised Image-to-Image Translation多通道无监督图像翻译
Posted 沉迷单车的追风少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Multimodal Unsupervised Image-to-Image Translation多通道无监督图像翻译相关的知识,希望对你有一定的参考价值。
前言:基于GAN的图像翻译方向一直很火爆,上次介绍了一个无法复现的SketchyGAN,非常失望。这次介绍一个来自英伟达研究院无监督GAN的图像翻译工作MUNIT,下一篇介绍同样是无监督图像翻译工作的《Unsupervised Sketch-to-Photo Synthesis》比较二者的异同,思考能给现在的工作带来的启发。
目录
主要贡献
给定源域中的一幅图像,目标是学习目标域中相应图像的条件分布,不需要看到任何对应图像对的例子。假设图像表示可以分解为领域不变的内容代码和捕获领域特定属性的样式代码。为了将一幅图像转换到另一个域,我们将其内容代码与从目标域的样式空间中采样的随机样式代码重新组合。
素描到照片的合成之所以具有挑战性,有两个原因:
1、素描和照片在形状上不一致,业余爱好者常用的素描在空间和几何上的变形较大。因此,将草图转换成照片需要矫正变形。
2、草图是无色的,缺乏视觉细节。在白纸上用黑色笔画草图,主要勾勒物体的边界和特征的内部标记。为了合成一张照片,阴影和彩色纹理必须被正确填充。
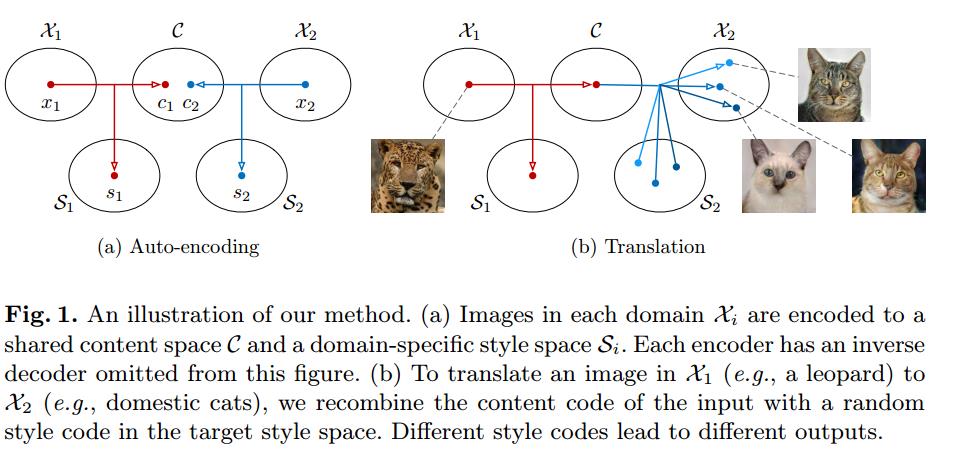
在本文中,我们提出了一个原则性框架的多模态无监督图像到图像翻译问题。如图1 (a)所示,我们的框架做了几个假设。我们首先假设图像的潜在空间可以分解为内容空间和风格空间。我们进一步假设不同域中的图像共享一个共同的内容空间,而不是样式空间。为了将图像转换到目标域,我们将其内容代码与目标样式空间中的随机样式代码重新组合(图1 (b))。内容代码编码翻译过程中应该保留的信息,而样式代码表示输入图像中不包含的其他变体。通过采样不同样式的代码,我们的模型能够产生不同的多模态输出。大量的实验证明了我们的方法在建模多模态输出分布的有效性和它的优越的图像质量比最先进的方法。此外,内容和样式空间的分解允许我们的框架执行示例引导的图像翻译,其中翻译输出的样式由用户在目标域中提供的示例图像控制。
方法详解
部分共享潜在空间假设
假设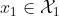 、
、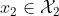 属于两个不同域,从两个边缘分布中抽取样本
属于两个不同域,从两个边缘分布中抽取样本 和
和 ,所以生成的目标是
,所以生成的目标是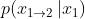 和
和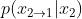 。
。
假设每个图像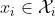 是由两个域共享的内容潜在代码和特定于单个域的风格潜在代码
是由两个域共享的内容潜在代码和特定于单个域的风格潜在代码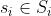 生成的。网络的目标是学习潜在的生成器和编码器函数与神经网络。
生成的。网络的目标是学习潜在的生成器和编码器函数与神经网络。
这个假设与UNIT中提出的共享潜在空间假设密切相关。虽然UNIT假设有一个完全共享的潜在空间,但我们假设只有部分潜在空间(内容)可以跨域共享,而其他部分(风格)是特定于域的,当跨域映射是多对多时,这是一个更合理的假设。
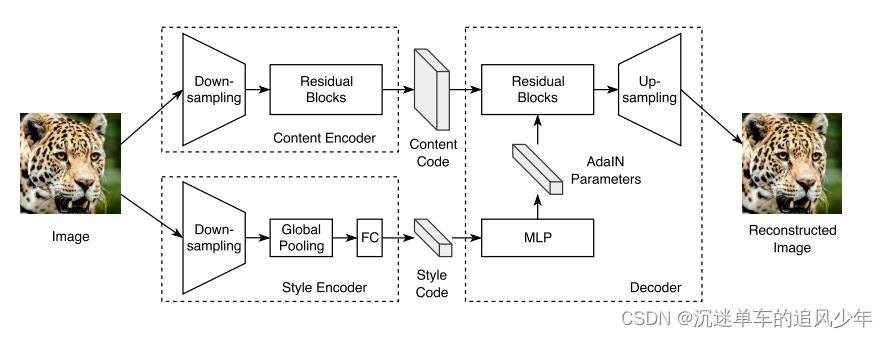
编码器-解码器结构
模型由两个自动编码器组成(分别用红色和蓝色箭头表示),每个域一个。每个自编码器的潜在代码由内容代码c和风格代码s组成。我们用对抗目标(虚线)训练模型,以确保翻译后的图像在目标域中与真实图像不可区分,以及双向重建目标(虚线),重建图像和潜在代码。
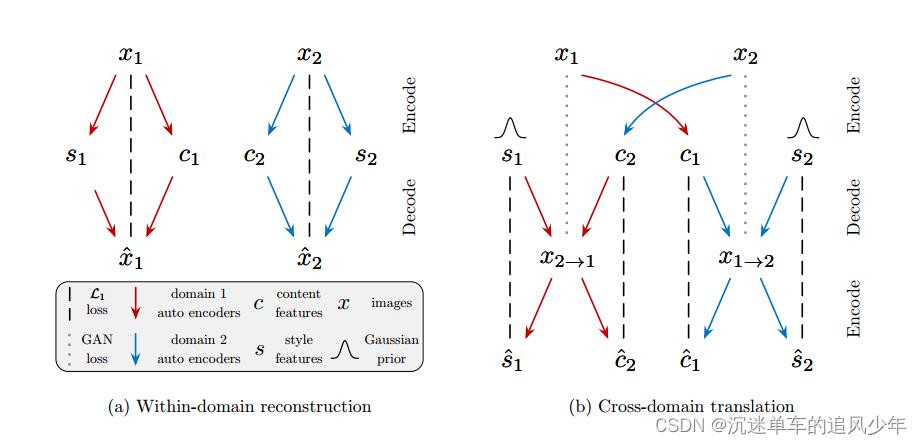
每个自动编码器的潜在代码被分解为一个内容代码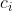 和一个样式代码
和一个样式代码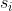 ,图像到图像的转换是通过交换编码器-解码器对来执行的,虽然先验分布是单峰的,但由于解码器的非线性,输出图像分布可以是多峰的。
,图像到图像的转换是通过交换编码器-解码器对来执行的,虽然先验分布是单峰的,但由于解码器的非线性,输出图像分布可以是多峰的。
损失函数包括双向重建损失(确保编码器和解码器是反向的)和对抗性损失(将平移图像的分布与目标域的图像分布匹配)。
双向重建损失函数
为了学习互为倒数的编码器和解码器对,我们使用目标函数来鼓励两者的重构image -> latent -> image和latent -> image -> latent。
图像重建损失函数。给定一个从数据分布中采样的图像,我们应该能够在编码和解码后重建它:
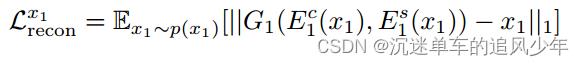
潜在重建损失函数。给定一个从翻译时的潜在分布采样的潜在代码(风格和内容),我们应该能够在解码和编码后重构它。
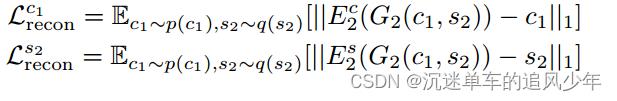
作者使用L1重建损失,因为它可以促进清晰的输出图像。
对抗损失。利用GANs来匹配翻译后的图像和目标数据的分布:
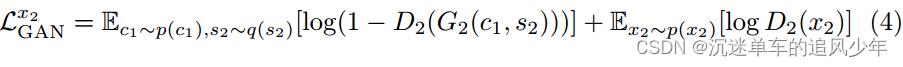
总损失
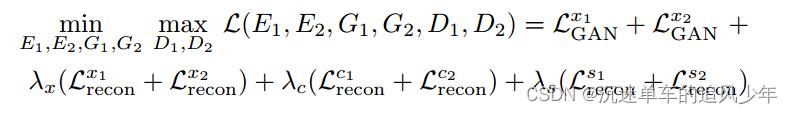
代码复现
不得不说英伟达研究院的论文很良心,都能快速复现,不想上次的sketchy gan,代码有问题发邮件问作者、提issue都不回复……
代码地址:GitHub - NVlabs/MUNIT: Multimodal Unsupervised Image-to-Image Translation
使用地址:imaginaire/projects/munit at master · NVlabs/imaginaire · GitHub
这个代码我复习了,他提供了shoe数据集的预训练模型,虽然在边缘图上的效果很好,但是我换成sketchy datasets的效果很一般,作者提出的是通用框架,不是针对sketch数据做优化,效果一般在情理之中。
我还计算了FID和IS,指标得分比无监督GAN的方法高一些,这就有点尴尬了。
个人感受
很遗憾这篇论文读的比较粗,作者提出的通用框架有点复杂,我在作者能直接使用的基础上就没有深入研究,有时间再回头看看这部分。

参考
以上是关于Multimodal Unsupervised Image-to-Image Translation多通道无监督图像翻译的主要内容,如果未能解决你的问题,请参考以下文章