消息队列学习 -- Kafka概念了解
Posted 躬匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息队列学习 -- Kafka概念了解相关的知识,希望对你有一定的参考价值。
前面我们依次学习了RabbitMQ、ActiveMQ中间件,今天我们接着来学习一下Kafka。
一、概述
Kafka是一种分布式的基于发布/订阅的消息系统,具有以下特点
- 同时为发布/订阅提供高吐量。kafka的设计目标是以O(1)的时间复杂度提供消息的持久化
- 消息持久化。支持将消息持久化到磁盘。
- 分布式。支持服务器间的消息分区以及分布式消费,同时保证每个分区内的消息顺序传输。其内部的Producer、Broker、Consumer都是分布式架构,这更易于水平扩展
- 消息的消费采用pull模式。生产者向Kafka push消息数据,消费者从Kafka pull消息数据,一推一拉。
- 支持offline、online场景。同时支持离线数据处理和实时数据处理
二、基础概念
在开始进一步学习之前,我们先来了解一些基本的概念(很多概念在消息队列中是通用的)
Broker(代理):Kafka集群中的一台或多台服务器,Broker无状态,支持水平扩展,集群中的服务器越多,吞吐量越大
Topic:发布到Kafka的每条消息都有一个类别
Partition:物理上的topic分区,一个topic可以分为多个Partition,每个Partition都是一个有序的队列
Producer:消息的生产者,可以理解为客户端
Consumer:消息的消费者,可以为消费者指定消费者组。如果不指定,则属于默认的消费者组。另外,消息被处理的状态是在Consumer端维护的,而不是服务器端,Broker无状态,由Consumer自己保存offset。
Consumer Group:消费者组,每个消费者都属于一个特定的的消费者组,一个Topic可以被多个消费者组消费。
三、架构
说了那么多,我们有必要从宏观上了解一下Kakfa的架构了。
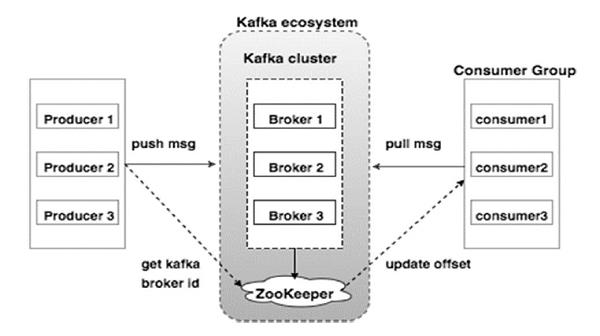
图1
下表描述了上图中显示的每个组件。
| S.No | 组件和说明 |
|---|---|
| 1 | Broker(代理) Kafka集群通常由多个Broker组成以保证高可用并提高吞吐量。 Broker是无状态的,更易于水平扩展,他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。Kafka经纪人领导选举可以由ZooKeeper完成。 |
| 2 | ZooKeeper ZooKeeper用于管理和协调Broker。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后产品和消费者采取决定并开始与某些其他代理协调他们的任务。 |
| 3 | Producers(生产者) 生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。 |
| 4 | Consumers(消费者) 因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。 |
四、应用场景
文章刚开始时,我们说到了Kafka支持offline、online场景,下面我们就来一起看一下这两种场景以及其他的应用场景。
说明一下,前两种应用场景都是基于Kafka高吞吐量的优势。
1、用户行为数据采集(online)
用户行为数据采集就是指从前端收集所需要的完整的用户行为信息,用于数据分析和其他业务。
Kafka最早的一个使用场景就是用户重建用户行为跟踪的流水线,通过Kafka把用户的网页浏览行为(消息)发布到中心主题中,通常每种行为类型都有一个主题。这些消息后续就可以被实时处理、实时监控或者加载到Hadoop集群或者离线数据仓库中。
每个用户浏览网页是都生成了很多活动信息,因此数据量会非常大,而Kafka的高吞吐量以及消息Pull模式比较适合这种场景。
2、日志收集(offline)
在公司内,应该都有一个统一的日志平台来管理项目中产生的日志文件。
基于Kafka的高吞吐量,可以将日志统一输出到Kafka,再由Kafka通过统一接口服务的形式开放给各种消费者。
目前很多公司做统一日志平台的方案就是收集重要系统日志到Kafka中,然后再导入ES、HDFS、Storm等具体日志数据的消费者去,用于实时监控、实时搜索分析、离线统计、大数据分析、数据挖掘。
五、其他
这里列出我的两个疑问点:
- Kafka是否保证消息的可靠投递呢?
- 发布-订阅消息模式下,如何保证消息的可靠投递,比如一个主题被多个消费者订阅,是需要每个订阅者都向Broker发送ack消息吗?
参考:
以上是关于消息队列学习 -- Kafka概念了解的主要内容,如果未能解决你的问题,请参考以下文章