优雅设计封装基于Okhttp3的网络框架:多线程下载添加数据库支持(greenDao)及 进度更新
Posted 鸽一门
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优雅设计封装基于Okhttp3的网络框架:多线程下载添加数据库支持(greenDao)及 进度更新相关的知识,希望对你有一定的参考价值。
通过前三篇博文的学习,已经编码实现多线程下载功能的核心代码,通过多个线程之间的管理和调度来处理下载任务,最后再引入队列机制来完善功能。此篇博文主旨需要将下载的进度存储到数据库中,目的是为了可以在恢复时可以取出进程下载进度,从未下载部分开始下载,能更节省流量,提高用户体验。
此篇文章将学习:
- 多线程下载添加数据库支持
- greenDao开源库自动生成数据库相关代码
- 完善网络请求接口中的进度更新功能
(建议阅读此篇文章之前,需理解前两篇文章的讲解,此系列文章是环环相扣,不可缺一,链接如下:)
优雅设计封装基于Okhttp3的网络框架(一):Http网络协议与Okhttp3解析
优雅设计封装基于Okhttp3的网络框架(二):多线程下载功能原理设计 及 简单实现
优雅设计封装基于Okhttp3的网络框架(三):多线程下载功能核心实现 及 线程池、队列机制解析
一. 整体项目回顾
首先在进行功能编码之前,需要将前三篇完成的多线程下载代码核心类逻辑理清除:
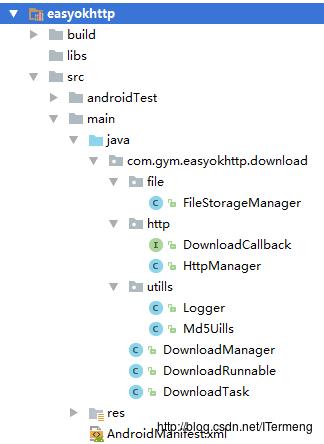
基于插件化思想,将 easyokhttp网络框架作为项目中的一个module来封装,这样不论哪个项目需要网络框架,将此module添加进去即可。
1. 整体代码
目前为止,以上代码是前3篇博文的所有编码内容:
- file
- FileStorageManager: 文件下载管理类
- http
- DownloadCallback:封装网络请求调用接口
- HttpManager:封装基本的网络同步、异步请求
- utils
- Logger:打印日志工具
- Md5Uills: MD5加密工具
- DownloadManager: 多线程下载主要功能封装
- DownloadRunnable:多线程下载功能中的单个线程Runnable
- DownloadTask:多线程下载任务,DownloadManager多线程下载功能使用到队列机制,进行增删任务
2. 多线程下载主要代码
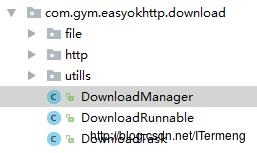
(1)DownloadTask
作用及组成
在上一遍博文教学中,我们在多线程下载功能中加入了队列机制,所以DownloadTask是一个下载任务类,成员变量有请求Url、接口回调callback,还要实现equals()、hashCode()方法,有点类似于一个JavaBean。
使用
既然是因为“队列机制”而衍生出的,主要被应用于DownloadManager类中,维护了一个队列任务集合,在需要增删下载任务时,会进行相应的操作。实现较为简单,查看代码即可理解,以下是代码结构图:
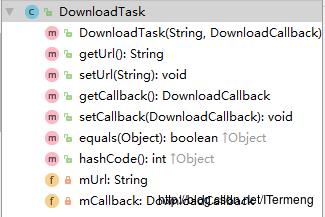
(2)DownloadRunnable
作用
既然是实现多线程下载功能,在DownloadManager类需要对多个线程进行管理,在上篇博文讲解中该管理类已经使用了线程池,所以当接收到文件下载任务时,将它分给多个线程,各自分配不同的下载起始、结束位置进行下载,而这个DownloadRunnable就是多个线程中的单个线程。
组成
DownloadRunnable实现了Runnable 接口,当创建此单个下载线程时,要传入必需的下载URL、下载起始位置、终止位置、接口回调这四个成员变量。最重要的就是run() 方法具体实现:根据指定长度进行下载(这里下载动作还是调用底层封装好的HttpManager中的同步请求方法),根据响应判断是否成功再进行接口回调,若成功将生成对应URL的文件,进行读写数据。
使用
所以,最主要的文件下载、读写操作都是在DownloadRunnable中进行。主要被使用于DownloadManager类中,在接收到文件下载任务时,会进行算法合理分配各个线程下载的文件位置,创建各个线程DownloadRunnable,由线程池对象进行执行execute(...)。
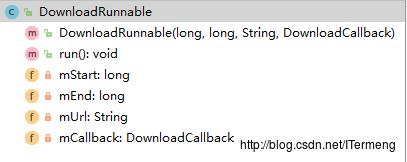
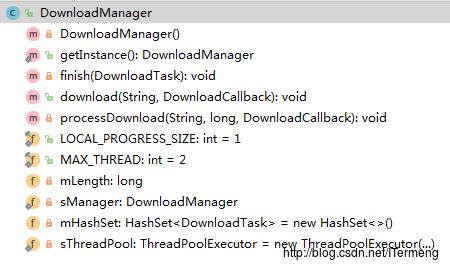
(3)DownloadManager ☆☆☆☆☆
作用及组成
DownloadManager 类主要实现了多线程下载功能,其中的重点方法download 方法即暴露给上层调用,此方法中运用到了以上两个重点类:
涉及DownloadTask: 当上层调用多线程下载类 DownloadManager 中的
download方法时,意味着一个任务,根据“队列机制”,创建新任务添加到此类维护的队列集合中;当下载任务完成时(不论请求成功或失败),从集合中移除。涉及DownloadRunnable:DownloadManager 类的
download方法中主要逻辑为多线程下载文件,所以再分配好每个线程的具体下载任务后,逐个创建多线程中的单个线程—–DownloadRunnable,令线程池对象执行execute(...)。
3. 其余类小结
以上第二点单独介绍的DownloadTask、DownloadRunnable、DownloadManager这三个类是多线程下载功能的主要实现类,需多注意理解构思这封装思想,另外将其他的综合归纳一二。
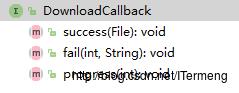
(1)DownloadCallback
http文件夹中的DownloadCallback:基本的网络请求回调接口,其中有3个方法:success、fail、progress,很常见的写法,在此无需赘述。
使用
既然是网络回调接口,所以只要涉及到网络请求的地方都会使用到,最普通的使用场景就是在调用Okhttp提供的原生网络请求后,在后续封装的回调中调用自己封装请求接口中的方法。
例如在Okhttp3提供的回调onResponse(...)方法中进行一系列逻辑判断后,在取决于调用自行封装的success还是fail。至于好处这里无需多言,自行封装后避免了重复冗杂的逻辑判断等等。
(2)HttpManager
http文件夹中的HttpManager:注意该类与DownloadManager的区别:
- 两者的共同点: 都暴露了下载方法供给上层调用。
- 区别: 但是DownloadManager类中的下载是基于多线程的,而HttpManager中封装的方法是基于单线程的,并且只是最基本的网络同步、异步请求。
使用
- 该类提供的基本网络同步、异步请求方法,可直接供给上层调用
- 该类提供的根据下载位置的网络同步请求,在多线程下载中的DownloadRunnable类中有被调用到。

(3)FileStorageManager
作用及组成
file文件夹中的FileStorageManager类:此类主要是一个文件管理类,重点方法getFileByName(...) —— 根据url获取文件,逻辑为首先根据url判断内存中是否有相对应的文件,若无则重新创建。
使用
- 主要被使用于DownloadRunnable类中,该类中的
run()方法在成功下载文件后,根据url获取文件,将下载获取的数据写到此文件中。 - 另外在HttpManage类——封装基本的网络同步、异步请求也有涉及,在成功下载文件后,,根据url获取文件,将下载获取的数据写到此文件中。

二. 添加数据库支持
以上第一大点我详细介绍总结归纳了多线程下载功能涉及到的主要类和其它类的作用、使用位置,因为多线程下载的主要功能已经实现,后面功能的完善、优化等工作是基于此部分上进行修改,所以各位在了解以下内容之前一定要将以上部分学习透彻,再细细参悟这封装思想。
接下来将在多线程下载中再完善一步,即添加数据库支持。
1. greendao
首先采用greendao这样一个开源框架,依赖它可以帮组我们自动创建一系列有关于数据库的相关代码(这里不会去详细讲解此开源库各种使用方法,仅介绍项目有关使用,望读者自行学习)。
(1)添加依赖
根据github上提示,在module中的build.gradle 文件中添加如下依赖即可:
https://github.com/greenrobot/greenDAO
apply plugin: 'org.greenrobot.greendao'
greendao
schemaVersion 1
daoPackage 'com.anye.greendao.gen'
targetGenDir 'src/main/java'
dependencies
......
compile 'org.greenrobot:greendao:3.0.1'
compile 'org.greenrobot:greendao-generator:3.0.0'
在项目文件夹中的build.gradle中添加:
dependencies
...
classpath 'org.greenrobot:greendao-gradle-plugin:3.0.0'
(2)编写自动生成类
在module中的db包中创建一个实体类 DownloadEntity,用于后续自动生成代码(GreenDao 3.0采用注解的方式来定义实体类,通过gradle插件生成相应的代码。),代码如下:
@Entity
public class DownloadEntity
@Id
private Long id;
private Long startPosition;
private Long endPosition;
private Long progressPosition;
private String downloadUrl;
private Integer threadId;
以上代码并不复杂,相当于确定表中数据项,编译项目后,该类中对应的get/set方法都会自动生成,以下数据操作代码类也会自动生成在我们指定的位置中(easyokhttp这个module中的db包中):
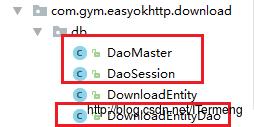
- DaoMaster类和DaoSession类是用于管理项目中的整个数据库,自动生成,不建议修改。
- DownloadEntityDao类是用于管理DownloadEntity这一个实体类,即这张表的创建、删除相关操作。
(3)编写调用帮助类DownloadHelper
其实greendao开源库已经为DownloadEntity实体类对象提供了CRUD相关API使用,为了上层调用和扩展性考虑,最好在此基础上再进行封装,编写一个专门的帮助类DownloadHelper,此类以单例模式对外,暴露需要供上层调用的查找、插入等操作。编写不难,代码如下:
/**
* @function 封装操作DownloadEntity数据增删改查的基本方法
* (greendao已为该实体类提供CRUD方法,此类在此基础上做基本封装)
*
* @author lemon Guo
*/
public class DownloadHelper
private static DownloadHelper sHelper = new DownloadHelper();
public static DownloadHelper getInstance()
return sHelper;
private DownloadHelper()
public void init(Context context)
SQLiteDatabase db = new DaoMaster.DevOpenHelper(context, "download.db", null).getWritableDatabase();
mMaster = new DaoMaster(db);
mSession = mMaster.newSession();
mDao = mSession.getDownloadEntityDao();
private DaoMaster mMaster;
private DaoSession mSession;
private DownloadEntityDao mDao;
public void insert(DownloadEntity entity)
mDao.insertOrReplace(entity);
public List<DownloadEntity> getAll(String url)
return mDao.queryBuilder().where(DownloadEntityDao.Properties.DownloadUrl.eq(url)).orderAsc(DownloadEntityDao.Properties.ThreadId).list();
(4)Application中初始化
注意:在下载帮助类DownloadHelper 中的init方法中封装了初始化download这张表的操作,而对实体类DownloadEntity的数据操作是直接关联到download表中的数据,所以在项目初始化即
Application中显示调用此帮助类的初始化方法。
【项目app文件夹下自定义的OkhttpApllication类】
DownloadHelper.getInstance().init(this);2. 融合数据库操作到多线程下载逻辑(DownloadManage、DownloadRunnable)
以上操作已经完成数据库管理相关代码,下面需要将数据库操作与逻辑融合在一起。
(1)DownloadManage中的download方法逻辑
主要需要修改的还是多线程下载核心管理类——DownloadManage其中的download方法,在第一点已经介绍过,这里再次回顾其方法逻辑:
- 判断此下载任务是否已存在于任务队列(集合)中,若无进行添加。
- 调用HttpManager网络同步请求获取待下载文件总长度。
- 若成功请求,在响应方法
onResponse中分配多个线程各自的下载任务,调用线程池对象进行执行。
- 若成功请求,在响应方法
- 网络请求完成(不论成功或失败),将该任务从任务队列(集合)中移除。
以上逻辑,若要融合数据库操作到多线程下载中,在添加任务队列后就需要查找本地数据库是否已存在相关数据:
- 若数据为空,则后续网络请求逻辑不变,但在分配多线程下载任务时,考虑到下载中断情况,DownloadRunnable执行完时需要将下载的字节位置、url相关信息存储到本地数据库中,每次下载时判断该位置,避免部分数据重复下载,实现断点续传。
- 若数据不为空(完整数据或者部分数据),则无需下载(或从断点处继续下载)。
(2)本地数据库url对应数据 为空 的情况
private List<DownloadEntity> mCache;
public void download(final String url, final DownloadCallback callback)
......//添加任务到队列集合
//在本地数据库中查找与url有关数据(以url作为每个数据的标识)
mCache = DownloadHelper.getInstance().getAll(url);
if (mCache == null || mCache.size() == 0)
HttpManager.getInstance().asyncRequest(url, new Callback()
......
);
private void processDownload(String url, long length, DownloadCallback callback)
// 100 2 50 0-49 50-99
long threadDownloadSize = length / MAX_THREAD;
if (mCache == null && mCache.size() == 0)
mCache = new ArrayList<>();
for (int i = 0; i < MAX_THREAD; i++)
DownloadEntity entity = new DownloadEntity();
long startSize = i * threadDownloadSize;
long endSize = 0;
if (endSize == MAX_THREAD - 1)
endSize = length - 1;
else
endSize = (i + 1) * threadDownloadSize - 1;
//将每个线程下载的具体信息存储到DownloadEntity实体类中,后续在DownloadRunnable进行操作,存储到表中。
entity.setDownload_url(url);
entity.setStart_position(startSize);
entity.setEnd_position(endSize);
entity.setThread_id(i + 1);
sThreadPool.execute(new DownloadRunnable(startSize, endSize, url, callback, entity));
新增代码分析
除了本地数据判断外,这里主要是修改了processDownload方法,在分配给每个线程下载任务时,将相关数据存储到DownloadEntity实体类,然后创建DownloadRunnable时传入该参数。
涉及DownloadRunnable修改
DownloadRunnable类是由线程池对象进行操作执行其run方法,在第一点中已详细介绍其逻辑就是根据创建时传入的URL、文件具体位置进行下载,然后将数据写入到本地文件File中。
但现在多传入的这个参数DownloadEntity,主要是考虑到后续逻辑,即下载过程中可能出现中断的情况,为了避免重复下载,实现断点续传的功能,需要引入这一实体类,在run方法最后(不论下载成功或失败),将读写到File的实际长度等相关信息记录到DownloadEntity实体类,然后写入到本地数据库中。
DownloadRunnable类新增代码
private DownloadEntity mEntity;
public DownloadRunnable(long mStart, long mEnd, String mUrl, DownloadCallback mCallback, DownloadEntity mEntity)
this.mStart = mStart;
this.mEnd = mEnd;
this.mUrl = mUrl;
this.mCallback = mCallback;
this.mEntity = mEntity;
@Override
public void run()
Response response = HttpManager.getInstance().syncRequestByRange(mUrl, mStart, mEnd);
if (response == null && mCallback != null)
mCallback.fail(HttpManager.NETWORK_ERROR_CODE, "网络出问题了");
return;
File file = FileStorageManager.getInstance().getFileByName(mUrl);
//每次下载时去获取本地数据库中相关信息(避免重复下载,实现断点续传)
long finshProgress = mEntity.getProgress_position() == null ? 0 : mEntity.getProgress_position();
long progress = 0;
try
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rwd");
randomAccessFile.seek(mStart);
byte[] buffer = new byte[1024 * 500];
int len;
InputStream inStream = response.body().byteStream();
while ((len = inStream.read(buffer, 0, buffer.length)) != -1)
randomAccessFile.write(buffer, 0, len);
//记录写入文件的长度
progress += len;
mEntity.setProgress_position(progress);
//不论下载成功或失败),将读写到File的实际长度等相关信息记录到DownloadEntity实体类
mEntity.setProgress_position(mEntity.getProgress_position() + finshProgress);
randomAccessFile.close();
mCallback.success(file);
catch (FileNotFoundException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
finally
//同步,即插入数据到数据库中
DownloadHelper.getInstance().insert(mEntity);
(3)本地数据库url对应数据 不为空 的情况
如果从本地数据库中查找的对应数据(集合)不为空,意味着可能存在下载过程中出现中断的情况,此时直接循环数据集合,因为每个对象中都记录着当前下载的位置、url相关信息,遍历所有创建线程调用线程池对象进行下载,上面已实现DownloadRunnable 的run方法中会判断传入参数实体类的相关数据,以其记录位置开始下载,避免某些数据重复下载,实现断点续传功能,
public void download(final String url, final DownloadCallback callback)
......//添加任务到队列集合
mCache = DownloadHelper.getInstance().getAll(url);
if (mCache == null || mCache.size() == 0)
HttpManager.getInstance().asyncRequest(url, new Callback()
......
);
else
// 处理已经下载过的数据,即从断点处继续下载
for (int i = 0; i < mCache.size(); i++)
DownloadEntity entity = mCache.get(i);
if (i == mCache.size() - 1)
mLength = entity.getEnd_position() + 1;
long startSize = entity.getStart_position() + entity.getProgress_position();
long endSize = entity.getEnd_position();
sThreadPool.execute(new DownloadRunnable(startSize, endSize, url, callback, entity));
三. 进度更新
1. 实现思想
进度更新的实现方法有多种,最容易想到的首先是根据线程下载长度来判断,可是这有一个隐形问题,文件下载采用的是多线程下载,还可能存在下载中断的情况,所以以线程下载为准来编写会有些复杂。
这里采取一种简单实现方法,以本地数据库中文件的变化大小来判断,可以避免多线程造成的问题,而我们需要编码的只是不断监控本地文件大小,算出百分比呈现出即可。
2. 代码实现
需要修改的代码还是多线程下载核心管理类—— DownloadManager,注意“监控”必然会是一个耗时的操作,所以创建一个线程ExecutorService来实现,调用该对象的execute方法,创建一个Runnable,其run方法核心逻辑就是一个死循环,每过500毫秒获取本地文件大小,计算百分比,将其结果调用回调DownloadCallback中的progress方法传送出去,这样可以在调用此请求的地方进行UI显示相关操作,若百分比达到100,则跳出死循环。
ExecutorService进行监控的位置就在DownloadManager类中的download方法最后,因为无论是重新下载还是断点续传下载,都会有一个进度上的更新。
private static ExecutorService sLocalProgressPool = Executors.newFixedThreadPool(LOCAL_PROGRESS_SIZE);
public void download(final String url, final DownloadCallback callback)
//添加任务至队列
......
mCache = DownloadHelper.getInstance().getAll(url);
if (mCache == null || mCache.size() == 0)
HttpManager.getInstance().asyncRequest(url, new Callback()
......
);
else
// 处理已经下载过的数据,即从断点处继续下载
......
//进度更新
sLocalProgressPool.execute(new Runnable()
@Override
public void run()
while (true)
try
Thread.sleep(500);
File file = FileStorageManager.getInstance().getFileByName(url);
long fileSize = file.length();
int progress = (int) (fileSize * 100.0 / mLength);
if (progress >= 100)
callback.progress(progress);
return;
callback.progress(progress);
catch (InterruptedException e)
e.printStackTrace();
);
3. 测试
测试代码依旧不变,只是在增加进度更新功能后,在进度回调方法中设置进度条显示即可。
final String url = "http://img1.gtimg.com/20/2000/200037/20003735_980x1200_0.png";
DownloadManager.getInstance().download(url, new DownloadCallback()
@Override
public void success(File file)
final Bitmap bitmap = BitmapFactory.decodeFile(file.getAbsolutePath());
runOnUiThread(new Runnable()
@Override
public void run()
mImageView.setImageBitmap(bitmap);
);
Logger.debug("MainActivity", "success " + file.getAbsoluteFile());
@Override
public void fail(int errorCode, String errorMessage)
Logger.debug("MainActivity", "fail " + errorCode + " " + errorMessage);
@Override
public void progress(int progress)
mProgress.setProgress(progress);
);
四. 总结
1. 本篇总结
此篇文章内容完成了添加数据库支持、进度更新的功能代码编写,内容有些多,若要完全理解需多花时间消化。其中重点在于需要对前三篇博文完成的多线程下载核心类 ——- DownloadManager、Ruunable的逻辑和整体思想熟透于心,这样在后续融合数据库支持时,才会思路清晰,了解在哪里需要添加数据库支持。
在第一大点中讲解了借助greendao开源库实现数据库相关代码自动生成,开发者只需要写好实体类,在编译时借助gradle会生成系列数据库、表创建、删除代码,非常方便,使用也不难,推荐最后在此基础上封装体帮助类,对代码以后扩展和解耦有很大帮助。
在第二大点中正式融合数据库代码操作到多线程下载逻辑中,其中主要修改的是DownloadManager、Ruunable类,增添代码的核心逻辑就是将各个线程已下载的位置长度(存在未下载完成时出现中断的情况)、url信息存储到本地数据库,在每次下载前首先判断本地数据库中存储的下载情况,根据本地数据为空与否,而选择是否重新下载或者断点续传。
在完成以上两大点之后,进度更新的实现就非常简单了,实现思路很多,这里采用比较简单的一种:以本地数据库中文件的变化大小来判断,可以避免多线程造成的问题,而我们需要编码的只是不断监控本地文件大小,算出百分比呈现出即可。
这是前三篇博文对应的源码,关于此篇博文修改后的源码正在整理,稍后贴出,正好读者可以先捋清封装思路,自行思考
2. 下篇预告
此篇内容编写实现其实并不容易,其中的封装思想一定要多加思考揣摩,博主这两天在完成的过程中遇到了些许bug,还有一些编写时遗漏的细节问题,读者可对应代码理解思考。
在下一篇博文中将对代码进行优化,开发一个新功能并不复杂,难的是考虑到代码的扩展性和解耦性,后续需要进行的bug修复、完善功能等方面。主要从代码优化,将从线程优化、单例优化、设计优化这三个方面进行讲解。
若有问题,虚心指教~
以上是关于优雅设计封装基于Okhttp3的网络框架:多线程下载添加数据库支持(greenDao)及 进度更新的主要内容,如果未能解决你的问题,请参考以下文章