「WTF系列」深入Java中的位操作
Posted Qiujuer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「WTF系列」深入Java中的位操作相关的知识,希望对你有一定的参考价值。
「WTF系列」深入Java中的位操作
引
学完本章节你将学会位的基础概念与语法,并且还会一些骚操作!!
- 与、或、非、位移
- 原码、反码、补码
- 字节、位、超区间…
开始本章节之前,我们先思考一个问题:
byte a = 33;
byte b = -3;
若我们输出a、b的二进制字符串是多少?
答案是这样的么?
a->// 00100001
b->// 10100001
当然同学们可能会觉得我既然问了就肯定不是这样;是吧~别着急你们试试就知道了。
在Java中输出一个值对应的二进制方法有很多,这里提供一个简单的方法:
int value = 33;
String bs = String.format("%32s", Integer.toBinaryString(value)).replace(" ", "0");
在方法中是int值,int占4字节32位,所以是:“%32s” 若是byte将32改成8即可;当然对于byte你还需要加上**“&0xFF”**来做高位清零操作。
String bs = String.format("%8s", Integer.toBinaryString(value&0xFF)).replace(" ", "0");
基本原则
在Java中是采用的有符号的运算方式,故:高位为符号位,其余位存储数据信息。
简单来说:
+1 ->// 00000001
-1 ->// 10000001
默认例子中的值都按byte来算,占8位,减少大家的记忆负担。
因为byte占8位,所以有效数据存储7位,最高位为符号位。int值则是31位存储数据。
- 0 代表正数
- 1 代表负数
上述的-1的表示方法其实并不是机器码,而是人脑的理解方式。
我们认为+1与-1的差异就是高位不同而已,这是我们基于自然规律来看的;而机器真正存储的值其实是:11111111;这里其实就给大家提到了最初的问题。
二进制的计算规则是:逢2进1
这个很好理解,因为表示的数字就是:0、1两个数字,想要表示更大的值就只能往前递增进步。
在平时生活中是逢10进1;因为咱们有10个数字:9、8、7、6、5、4、3、2、1、0;所以11就是:当为0|9增加为10的时候就进一格所以变成:1|0,个位再把剩余的1补上就是:1|1;所以就是11。
那么:
1就是:0|0|0|0|0|0|0|1
2就是:0|0|0|0|0|0|1|0
3就是:0|0|0|0|0|0|1|1
4就是:0|0|0|0|0|1|0|0
运算法则

设
byte a = (byte) 0b01011000; // 88
byte b = (byte) 0b10101000; // -88
int n = 1;
按位与 a & b
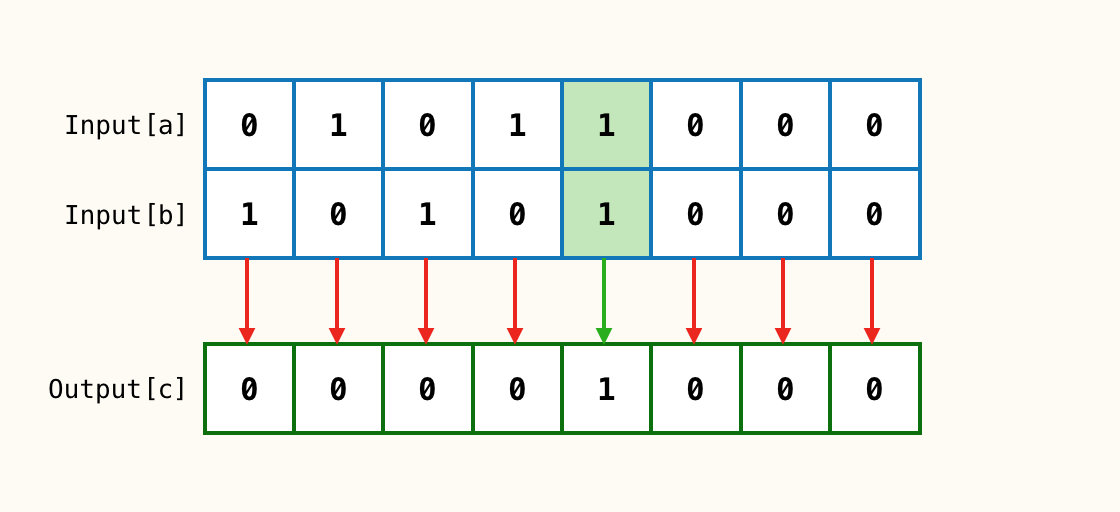
输入2个参数
a、b对应位都为1时,c对应位为1;反之为0。
按位或 a | b**
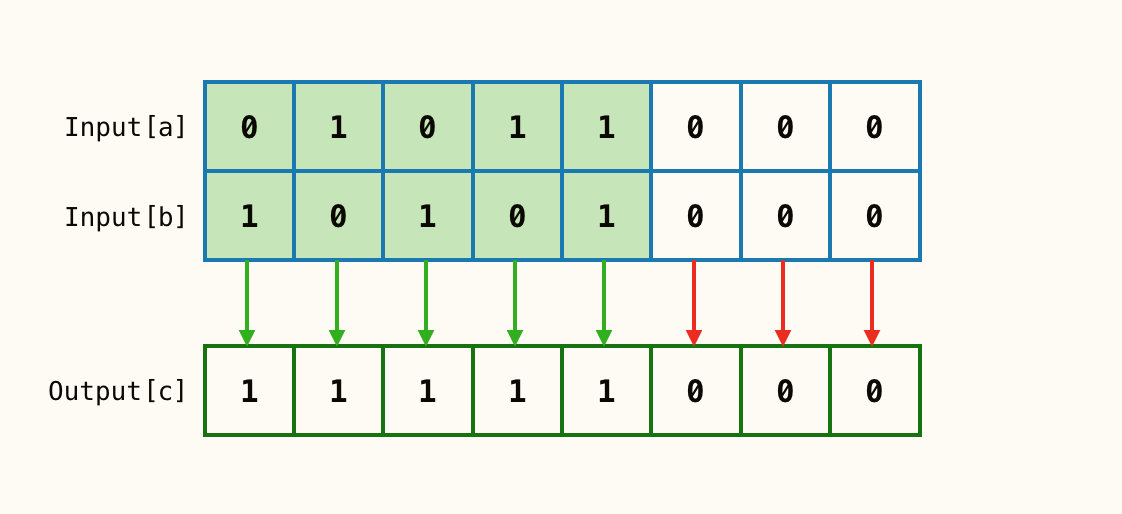
输入2个参数
a、b对应位只要有一个为1,c对应位就为1;反之为0。
按位异或 a^b
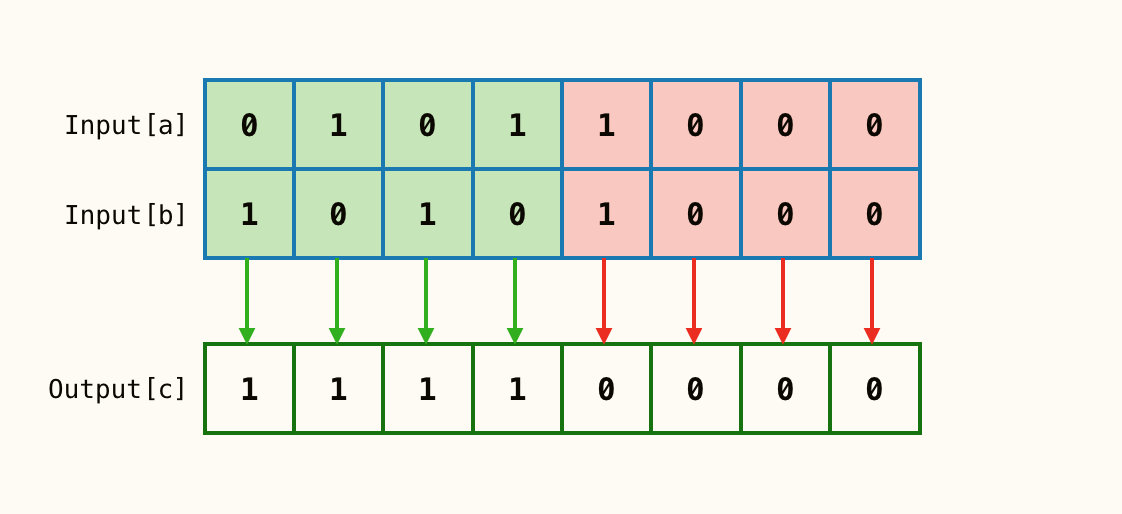
输入2个参数
a、b对应位只要不同,则c对应位就为1;反之为0。
按位取反(非)
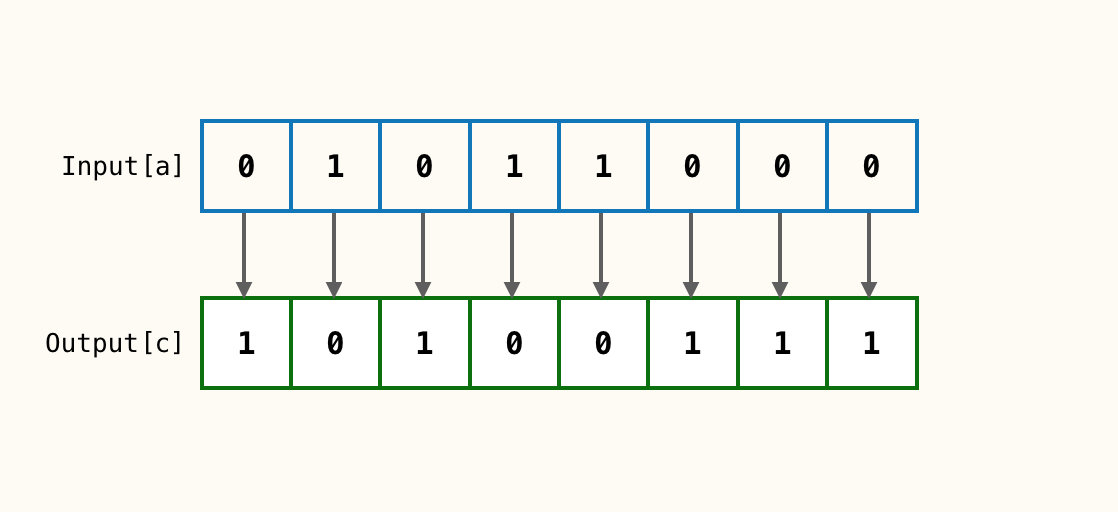
输入1个参数
c对应位与输入参数a完全相反;a对应位为1,则c对应位就为0;a对应位为0,则c对应位就为1。
左移
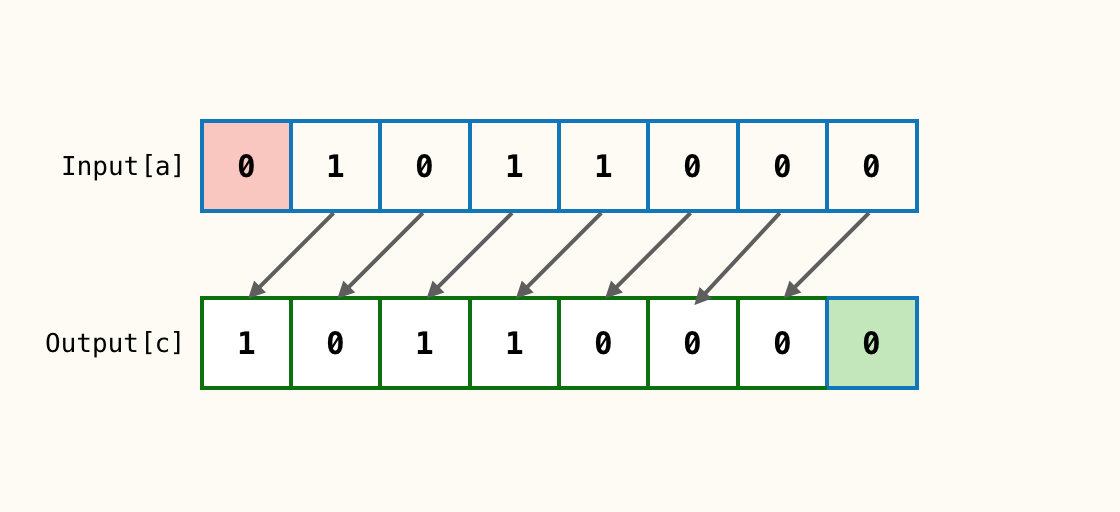
输入1个参数a;n = 1
a对应位全部左移动n位得到c;a最左边的n个位全部丢弃(红色框),c最右边n个位补充0(绿色框)。
右移(带符号)
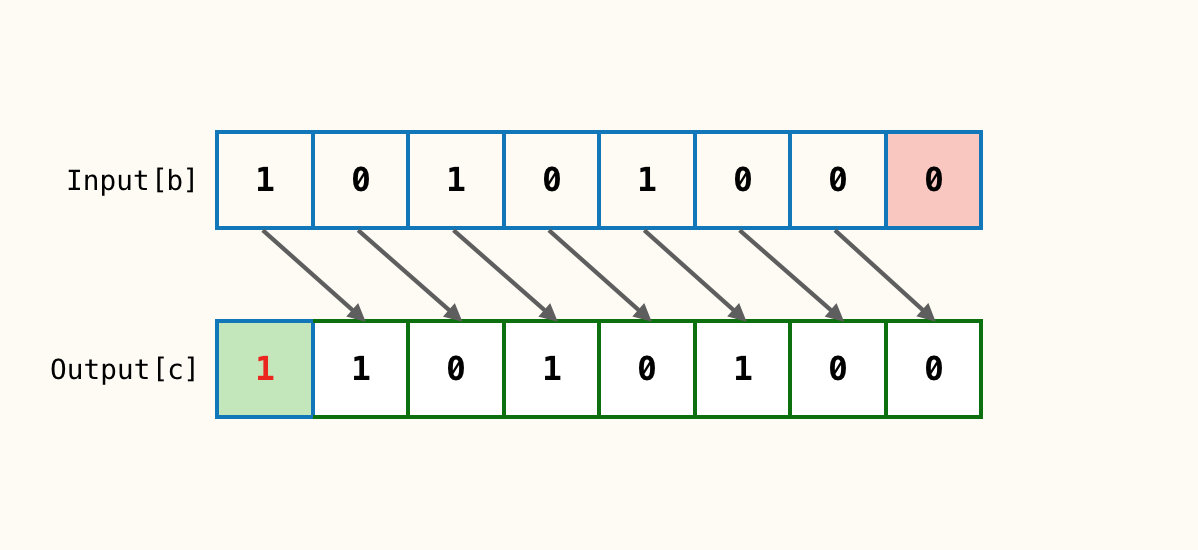
输入1个参数b;n = 1
这里将参数换为b是因为b为负数,第一个位为1
b对应位全部右移动n位得到c;b最右边n个位全部丢掉(红色框),c最左边n个位补充1(绿色框)。
这里需要注意的是其左边补充的值取决于b的最高位也就是符号位:符号位是1则补充1,符号位是0则补充0。
右移(无符号)
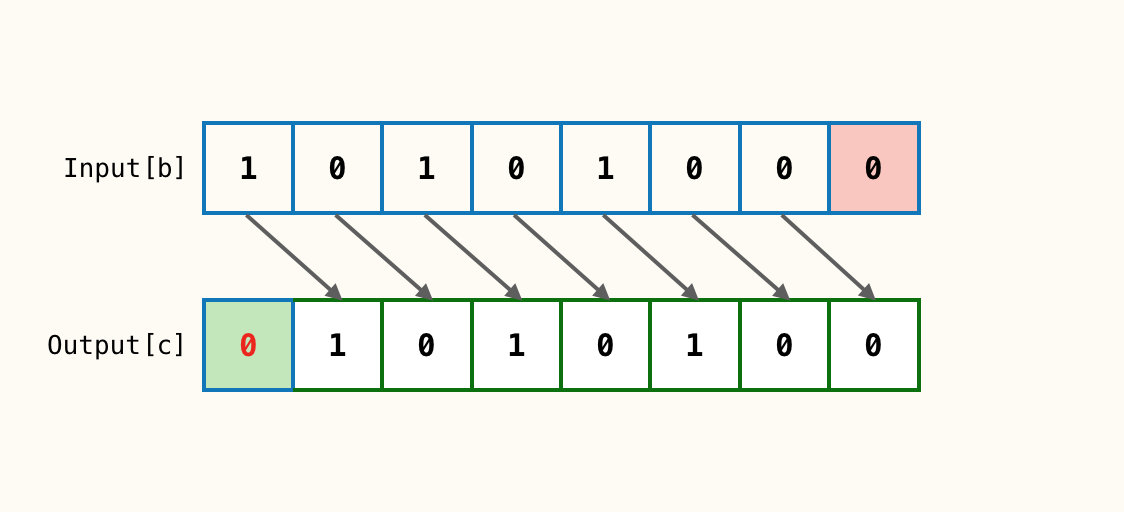
输入1个参数b;n = 1
这里将参数换为b是因为b为负数,第一个位为1
b对应位全部右移动n位得到c;b最右边n个位全部丢掉(红色框),c最左边n个位补充0(绿色框)。
这里需要注意的是其左边补充的值永远为0,不管其最高位(符号位)的值。
进制表示规范
这个小节是插曲,部分同学可能注意到上面写的进制定义是:0b01011000,部分同学 可能疑惑为什么不是 0x 之类的。
前缀
- 十进制:直接写数字即可
- 二进制:0b或0B开头;如:0b01011000 代表十进制 88
- 八进制:0 开头;如:0130 代表十进制 88 (1x64+3x8)
- 十六进制:0x或0X开头;如:0x58 代表 88 (5x16+8)
后缀
- 0x?? 若小于127 则按byte算,大于则按int类型算
- 0xFF默认为int类型
- 若声明为long添加后缀:L或l:如:0xFFL 或 0xFFl
- 带小数的值默认为double类型;如:0.1
- 若声明为float添加后缀:f 或 F:如:0.1F
- 若声明为double添加后缀:d或D:如:1D
范围
- 二进制:1、0
- 八进制:0~7
- 十进制:0~9
- 十六进制:0~9 + A~F
类型转换
在上述运算法则中:两个不同长度的数据进行位运算时,系统会将二者按右端对齐左端补齐,然后进行位运算。
设
- a 为 int 占32位
- b 为 byte 占8位
执行: a&b 、a|b 、a^b….等操作时:
- 若b为正数,则左边补齐24个0
- 若b为负数,则左边补齐24个1
若b = 0b01011000 补齐后:0b 00000000 00000000 00000000 01011000
若b = (byte) 0b10101000 补齐后:0b 11111111 11111111 11111111 10101000
为什么 b = 0b10101000 需要加上 (byte) 强转?
因为默认的0b10101000会被理解为:0b 00000000 00000000 00000000 10101000,这个值是一个超byte范围的int值(正数):168。
当强转 byte 后高位丢弃,保留低8位,对于byte来说低8中的高位就是符号位;所以运算后就是:-88(byte)。
原码、反码、补码
相信看了上面那么多的各种规定后,大家有一定的疑问,为什么正数与负数与大家所想的不大一样呢?
我相信大家觉得正数负数就是这样的:
// 错误的理解
// 0b01011000 -> 88 : (64+16+8)
// 0b11011000 -> -88 : -(64+16+8)
大家可能会想,正数与负数不就应该只是差符号位的变化么?
// 正确的理解
// 0b01011000 -> 88 : (64+16+8)
// 0b10101000 -> -88 : -(64+16+8)
0b10101000 : -(64+16+8) ??WTF?? 除了符号位能懂以外请你告诉我是怎么得出 64、16、8的?
在这里我们先设两个基本的概念:
- 原码:人所能直接理解的编码
- 机器码:计算机能直接理解的编码
允许我先说一个小故事:对于在坐的各位来说计算1-1是非常简单的,但是对于计算机来说就是计算:00000001 与 10000001 (暂且按8位,原码)。

计算机需要识别出橙色部分的符号位,然后提取出粉色部分的数据进行计算;这里有两个问题:
- 识别橙色符号位是困难的
- 若橙色部分是负数则需要增加减法计算模块
但对于计算机来说做加法就够了,将1-1换算为:1+(-1);OK这一步就是将所有的减法都换算为加法进行计算,减少了减法硬件模块的设计,提升了计算机的硬件利用率。
但是这里就有一个问题了,既然是将-1当作了一个值来进行运算,那么必然这个值需要方便做加法才行;按上图来说我们必不可免的需要去做一次符号位的判断,然后再做数据位的减法操作,简单来说还是在做减法。
所以若计算机的机器码直接采用原码则会导致硬件资源的设计问题。
有没有一种办法将符号位直接存储到整个结构中,让计算机在计算过程中不去管所谓的符号位与数据位?有的!就是反码。
反码
- 正数的反码是其本身
- 负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。可以简单理解为 "~a | 10000000"
[+1] = [00000001]原 = [00000001]反
[-1] = [10000001]原 = [11111110]反

如上图,咱们将 -1 的原码转化为了反码;此时我们使用 反[+1] + 反[-1] 进行一次运算:
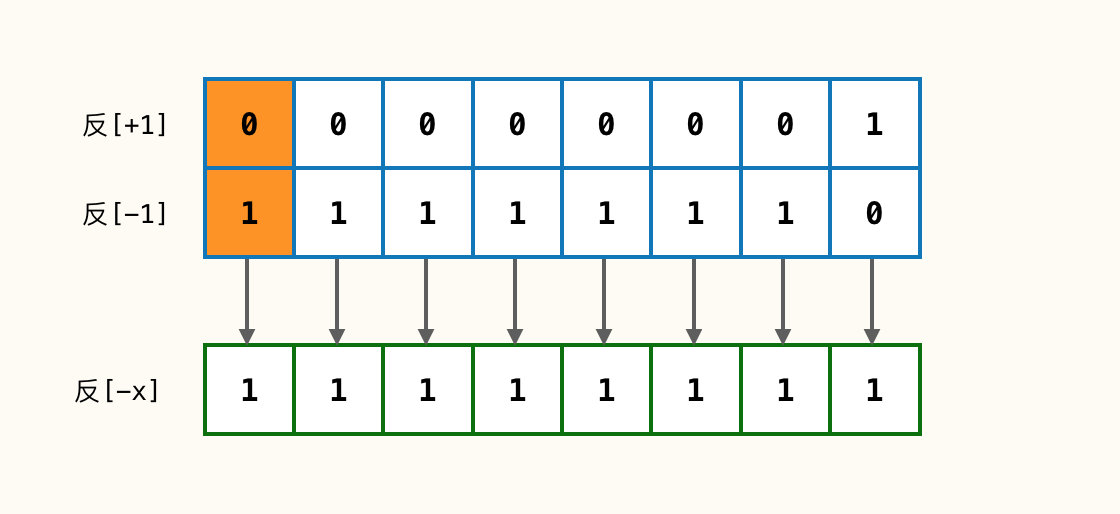
此时咱们可以得到一个值x,这个值可以确定的是符号位为1,为负数,后面数据位全部为1;因为此时是反码状态,所以要想我们能直接读取数据是不是应该转化为原码状态啊。
// 反码转原码流程就是倒过来,符号位不变,其余位为取反即可。
1 - 1 = 1 + (-1) = [00000001]原 + [10000001]原= [00000001]反 + [11111110]反 = [11111111]反 = [10000000]原 = -0
可以看出我们已经解决好了运算的问题了,计算机只需要按照反码的方式去计算即可,只需要做加法,不需要做减法就可以运算减法流程。计算完成后对于人脑来说需要将反码转化为原码就是可读的数据了。
但上述也暴露一个问题:-0 的问题;对于0的表示将会出现两种情况:
- [11111111]反 = [10000000]原 = -0
- [01111111]反 = [00000000]原 = +0
也就是出现两种为0的表示值,-0与+0;但对于我们来说0就是0,不需要做区分。所以又引入了补码。
补码
- 正数与反码规则一样无需变化:补码=反码=原码
- 负数在反码基础上保证符号位不变,从右端+1
[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补
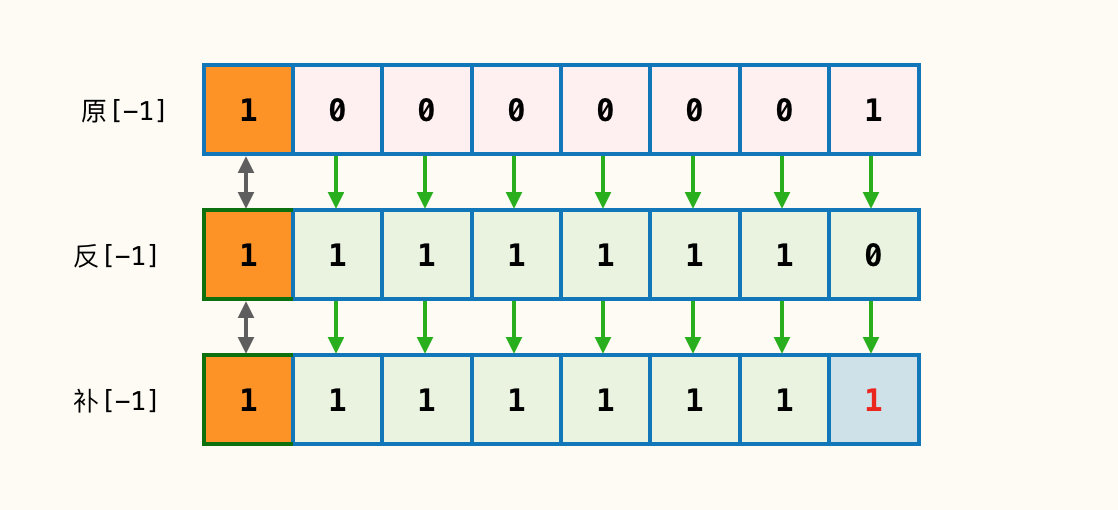
此时若计算机使用补码直接进行计算会怎样?
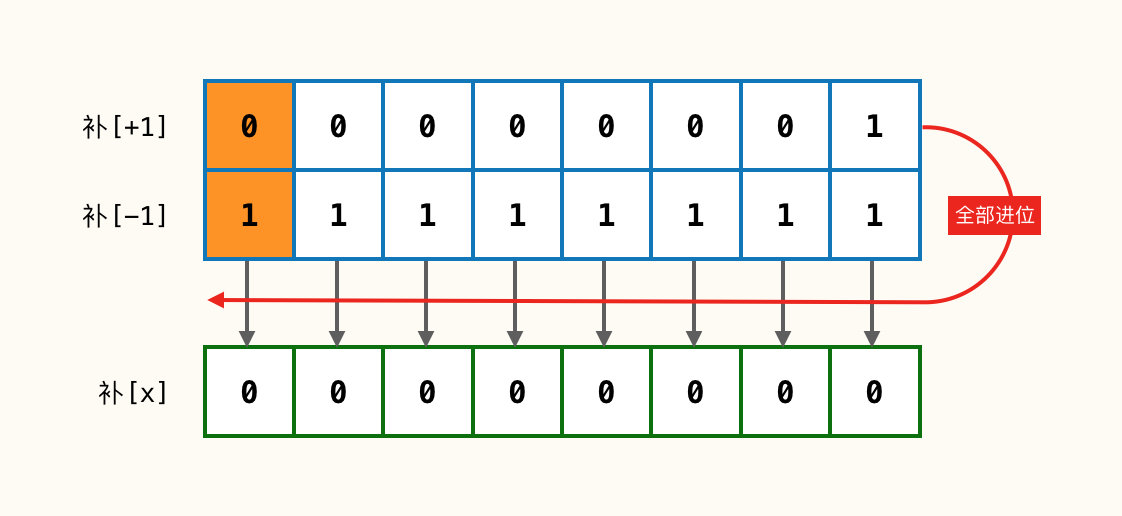
当我们使用补码计算时,因为末尾的两位均为1,1+1 = 2;对于二进制来说满2进1,所以往前进位1,进位后又遇到 1+1 = 2的情形,所以依次进位,当前位置0。
最终计算后就是:1 00000000 ,一共9位,因为当前只有8位,所以自然就只剩下:00000000 。
请注意:在当前运算过程中符号位并无差别也直接当作普通值进行步进运算!
如此我们就完成了整个流程的运算,但你还需注意的是,当前运算后的值是补码,也就是机器直接操作的编码;如果要还原为我们可读的值需要反向转化为原码。由最初定义可知,正数:原码=补码;上述补码为正数,所以原码也是:00000000。整个流程如下:
// 补码计算流程
1 - 1 = 1 + (-1)
= [00000001]原 + [10000001]原
= [00000001]反 + [11111110]反
= [00000001]补 + [11111111]补
= [00000000]补
= [00000000]原
= 0
补码->原码
正数的补码就是原码
负数:
- 直接倒叙流程,保证符号位不变右端减1,再保证符号位不变其余位取反即可
- 再走一遍补码流程;补码的补码就是原码(先取反再+1即可)【敲黑板】
思考[10000000]代表什么?
若是某个计算完成后的补码值为:10000000 那么他对应的值是什么呢?
// 按方案1来看:
[10000000]补 = [11111111]反 = [10000000]原
// 按方案2来看:
[10000000]补 = [11111111]补反 = [10000000]补补 = [10000000]原
可见方案1、方案2都是一样的,补码的补码就是原码。
[10000000]原 = 是等于0呢?还是-0呢?还是-128呢?
因为我们已经规定了:[00000000]原 = 0;为了充分利用位的存储区间,所以将:[10000000]原 = -128
一般情况下不会对[10000000]补码求原码,因为也没啥意义~
思考(127、-127)原码、反码、补码是多少?
对于正数:
127 = [01111111]原 = [01111111]反 = [01111111]补
对于负数:
-127 = [11111111]原 = [10000000]反 = [10000001]补
对于计算机来说,其存储的值都是补码,所以也就造成了一开始我们提到的问题:为什么88与-88的二进制并不只是符号位不同?
再次强调:计算机存储的是补码,为了方便运算;我们想要理解其表示的值需要转化为原码。
溢出问题
因为计算机计算过程中不再区别符号位,直接将符号位也纳入运算流程中;所以也就可以解释2个基础问题:(溢出)
- 两个正数相加为负数
- 两个负数相加为正数
大家可以分析一下:
- 88+100
- (-66) + (-88)
上述计算在byte变量范围下进行计算,尝试分析一下补码的计算流程。
存储区间
默认的对于采用补码的计算机系统而言,其存储值的有效范围是:-2^(n-1) ~ 2^(n-1) -1 ;n代表当前的位数。
- byte,1字节,8位:-2^7 ~ 2^7 -1 = -128~127
- short,2字节,16位:-2^15 ~ 2^15 -1 = -32768 ~ 32767
- int,4字节,32位:2^31 ~ 2^31 -1
- …
若,我想在byte中存储超过127的值会怎样?
设:
- int i = 200
- 对应补码为: 0000 0000 0000 0000 0000 0000 1100 1000
- 因200未超256(2^8)所以依然只会使用到8个位
int i = 200; // 0000 0000 0000 0000 0000 0000 1100 1000 (200)
byte b = (byte) 200; // 1100 1000
当我们将200强转为byte时高位丢弃仅剩下低8位:1100 1000
如果我们对byte进行输出会怎样?
System.out.println(b); // "-56"
首先其直接调用的是:public void println(int x) 方法,OK,既然是int输出为啥不是200?而是-56?
就算有这样的方法:public void println(byte x) 方法,会输出200么?也不会!!
首先对于byte b来说:1100 1000 这是一个负数的补码,其原码流程是:
[1100 1000]补 = [1011 0111] = [1011 1000]原 = -(32+16+8) = -56
这里有一个有趣的事情,int转byte时是直接丢掉高位的所有数据:24个0;但byte转int时,补充高24位时是根据当前的符号位来补充的,若当前符号位是1则添1,若符号位是0则添0;对于byte来说第一位就是符号位,当前的1100 1000符号位是**“1”**所以添加的就是24位1。
int c = b; // b -> 1100 1000
// c -> 1111 1111 1111 1111 1111 1111 1100 1000
若直接打印的是byte值,就是-56;上面我们分析1100 1000的原码时就已经证明了。那么打印c是不是呢?
对于范围较少的类型转换位大类型时不会丢失数据,原来是什么就是什么。
OK,就算不是上面那句话,我们来看看:
[1111 1111 1111 1111 1111 1111 1100 1000]补
= [1000 0000 0000 0000 0000 0000 0011 0111]
= [1000 0000 0000 0000 0000 0000 0011 1000]原
= -(32+16+8) = -56
若我们转换为int时想要还原最初的200这个值该如何办?
分析上面的补码,可以看出其与最初的补码差异仅仅在于左边24位的不同:
[1111 1111 1111 1111 1111 1111 1100 1000]补 = -56
[0000 0000 0000 0000 0000 0000 1100 1000]补 = 200
那么我们只需要将前面的24位重置为0即可,这里就有一个与操作的简单用法:
/**
*
* 1111 1111 1111 1111 1111 1111 1100 1000 (the int)
* &
* 0000 0000 0000 0000 0000 0000 1111 1111 (the 0xFF)
* =======================================
* 0000 0000 0000 0000 0000 0000 1100 1000 (200)
*/
System.out.println(b & 0xFF); // "200"
在这里我们做了一次特殊的:b & 0xFF 操作,b 转换为int之后的值与 0xFF 进行按位与操作。
0xFF = 255 其int原码为:0000 0000 0000 0000 0000 0000 1111 1111,恰好最后8位为1,其余24位为0;所以可以用来做高位擦除操作。
这样的用法可用以存储超范围的数据,比如对于文件的大小来说永远都是 >= 0,不可能会使用到 < 0 的值,所以对于原始的我们可以根据这个,使用较少的byte表示更多的区间,简单来说就是无符号。将符号位也用以存储数据。
int i = 0xFF60; // 65376
System.out.println(i);
// 00000000000000001111111101100000
System.out.println(String.format("%32s", Integer.toBinaryString(i)).replace(" ", "0"));
byte b1 = (byte) i;
byte b2 = (byte) (i >> 8);
// 01100000
System.out.println(String.format("%8s", Integer.toBinaryString(b1 & 0xFF)).replace(" ", "0"));
// 11111111
System.out.println(String.format("%8s", Integer.toBinaryString(b2 & 0xFF)).replace(" ", "0"));
int ret = (b1 & 0xFF) | (b2 & 0xFF) << 8;
System.out.println(String.format("%32s", Integer.toBinaryString(ret)).replace(" ", "0"));
// 65376
System.out.println(ret);
若没有做 & 0xFF 操作,其值应是:
/*
* 0000 0000 0000 0000 0000 0000 0110 0000 (b1)
* |
* 1111 1111 1111 1111 1111 1111 0000 0000 (b2<<8)
* =======================================
* 1111 1111 1111 1111 1111 1111 0110 0000 (-160)
*/
System.out.println(b1 | b2 << 8); // "-160"
65376 本质来说超过了short的存储范围:-32768~32767 ,但其在int中依然只需占2个字节16位:65376<65536。所以我们只需要使用2个byte即可存储,而不需要int的4个byte来存储。
在Socket传输中使用这样的方式能有效降低传输的字节冗余。
案例-多Flag存储在一个byte中
有这样一个情形:一个四边形,四条边可以是虚线也可以是实线,四条边相互独立;定义为 a\\b\\c\\d 四边;此时我们需要在画布上画出这个四边形;但是因为4边相互独立,所以我们常见的就是定义4个bool值:
boolean a = true;
boolean b = false;
boolean c = false;
boolean d = true;
void changeA(boolean fullLine)
a = fullLine;
简单来说我们定义这样的方式其一比较麻烦,其二总占用的内存空间至少是4个byte,也有可能是16byte(按int存的情况)。
但是我们表示的内容无非就是2种:实线、虚线
所以我们可以这样做:
static byte a = 0b00000001;
static byte b = 0b00000010;
static byte c = 0b00000100;
static byte d = 0b00001000;
byte x = 0b00000000;
定义a、b、c、d为static,并且使用最后的4位即可。
若我们想要改变a边的实虚:
void changeA(boolean fullLine)
if (fullLine)
x = (byte) (x | a);
else
x = (byte) (x & ~a);
通过该方法,若a边为实线,则将a flag的值填入x中,反之擦除掉x中的a边信息;同时保证其他信息不变。
若要拿,也就是判断a是否为实线该如何办?
boolean isFullLine()
// return (x & a) != 0;
return (x & a) == a;
2种写法都是OK的,不过需要注意若对应的a使用了符号位则需要使用0xFF先清理自动补充的符号位。因为与、或、非等操作默认会将参数转化为int类型进行;所以会出现自动补充符号位的情况。
这样的操作方案在android或Socket传输中都是非常常见的,比如Socket NIO中的SelectorKey中的ops变量就是这样的机制;这能有效减少存储多个参数的情况;并且位操作并不会带来多少计算负担。
以上就是关于Java 位操作的常见疑问与原理的讲解,其实还有一些深入的东西,比如:同余、负数取模、小数、规律运算等;这些因为使用较少并且篇幅有限就等下期再给大家一一介绍了。
我是QIUJUER,关于我
以上是关于「WTF系列」深入Java中的位操作的主要内容,如果未能解决你的问题,请参考以下文章