Java常见面试知识点汇总
Posted DreamMakers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java常见面试知识点汇总相关的知识,希望对你有一定的参考价值。
提问:LinkedHashMap与TreeMap的实现原理?两者怎么保证有序性的?两者有什么区别?
LinkedHashMap和TreeMap都是哈希表结构的具体实现。
(a)LinkedHashMap的实现原理
LinkedHashMap类继承自HashMap,哈希表的内部存取基本和HashMap是一样的。
在LinkedHashMap内部,维护了链表的首尾引用,分别为head和tail,并且定义了一个accessOrder变量,用于控制是根据插入顺序排序还是根据读取顺序排序。
当accessOrder为false时,表示根据插入顺序排序;当accessOrder为true时,表示根据获取顺序排序;
如果使用不带accessOrder的构造函数,默认accessOrder=false,即根据元素的插入顺序进行排序。
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
在插入元素时,LinkedHashMap会使用首尾指针去维护新插入的元素,将当前新增节点放到tail节点的后面;
如果在构造对象时传入了accessOrder=true,则表示根据获取顺序排序。此时,如果在调用get()方法前只有插入,那么链表维护的顺序即是元素插入的顺序,也可以理解为就是元素被访问的顺序。如果通过get()方法获取了元素,则在获取该元素后会调用afterNodeAccess()方法,该将该元素顺序调整到链表的尾部,从而实现在遍历链表时是根据访问顺序排序,最后访问的元素永远在链表的尾部。
public V get(Object key)
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
(2)TreeMap的实现原理
TreeMap底层是基于红黑树数据结构实现的,所以时间复杂度在log(n)。
在构造TreeMap对象时,可以传入比较器,也可以不传入。如果不传入,则默认按照键key的自然排序规则(应该是按照ASCII的顺序)进行排序;
如果在构造方法中传入了Comparator对象,则以Comparator对象的方法进行比较;否则,以Comparable的compareTo()方法进行比较,此时要求保存在TreeMap中的类型必须实现了Comparable接口。
TreeMap中不允许插入key为null,否则会报错NullPointerException;(以此对应的,HashMap是可以插入key为null的场景,从而HashSet、LinkedHashSet、LinkedHashMap也都允许,并且HashMap还支持value为null),但是value允许传null;
TreeMap是非线程安全的;
提问:HashTable和ConcurrentHashMap的区别?
HashTable的线程安全是通过在操作方法上添加synchronized关键字实现的,而ConcurrentHashMap的线程安全实现方式在不同的JDK版本中是不同的,在JDK1.7中是通过分段锁实现的,而在JDK1.8中是通过在每个数组元素上加锁的,每个元素可能对应的是一个链表或者是一个红黑树。
它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时map需要被锁定很长的时间。因为ConcurrentHashMap引入了分段锁的概念(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分(这是在JDK1.7中的实现方式,在1.8之后没有采用分段锁),而Hashtable则会锁定整个map。
提问:HashMap在JDK1.8中的实现相比于JDK1.7有哪些优化?
(a)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法。
为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(b)扩容后数据存储位置的计算方式也不一样:
在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
(c)JDK1.7版本中HashMap采用数组+链表实现,JDK1.8版本中通过数组+链表+红黑树实现;
(d) JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
(e)对于待插入的新数据,在JDK1.7中是在扩容后老数据迁移之后再进行新数据的插入,但是在JDK1.8中,是将新数据插入之后再进行扩容,新老数据在扩容后统一迁移处理;
提问:哈希冲突的解决办法有哪些?
解决哈希冲突的三种方法:拉链法、开放地址法、再散列法。
链接地址法的思路是将哈希值相同的元素构成一个单链表,并将单链表的头指针存放在哈希表的第i个单元中。链表法适用于经常进行插入和删除的情况。
开放定址法从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。
在开放定址法中解决冲突的方法有:线行探查法、平方探查法、双散列函数探查法。
再散列法,就是在发生冲突的时候使用其他哈希函数进行计算,直到冲突不在发生。
提问:HashSet能不能保存null值?对于null值怎么处理的hashcode?
HashSet可以保存null值,在HashSet内部是使用HashMap数据结构进行维护的,所有的key==null都指向同一个对象。
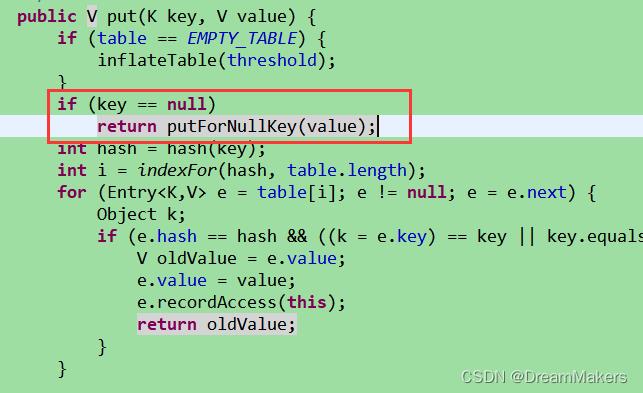
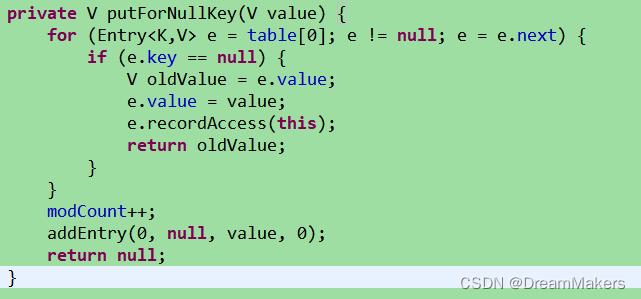
对于key=null的情况,会特殊处理,调用putForNullKey(value)方法。所有key值为null的都保存在bucketIndex为0的位置。如果发现已经有null保存进去了,则不再重复添加null节点。
备注说明
如果想第一时间获取最新最全的面试知识和面试技巧,欢迎扫码关注微信公众号(IT面试直通车),关于互联网编程与面试,这里一定有你想要的。
目前公众号处于初期内容整理建设阶段,计划半年时间将所有相关知识点都整理汇总,添加关注后可以跟随公众号一起逐渐成长,如对相关问题有疑问,可回复进行探讨,谢谢。

前文回顾
以上是关于Java常见面试知识点汇总的主要内容,如果未能解决你的问题,请参考以下文章