MySQL从入门到精通高级篇MySQL的SQL语句执行流程
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL从入门到精通高级篇MySQL的SQL语句执行流程相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 5. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
全网同名【码农飞哥】欢迎关注,个人VX: wei158556
文章目录
1. 简介
今天正式进入核心知识点的学习,本文主要介绍mysql中SQL的执行流程。熟悉SQL的执行流程对后期数据库的优化至关重要。话不多说直接进入今天的学习。
2. 环境
| 环境 | 版本 |
|---|---|
| Red Hat | 4.8.5-39 |
| MySQL | 5.7 |
SQL执行流程
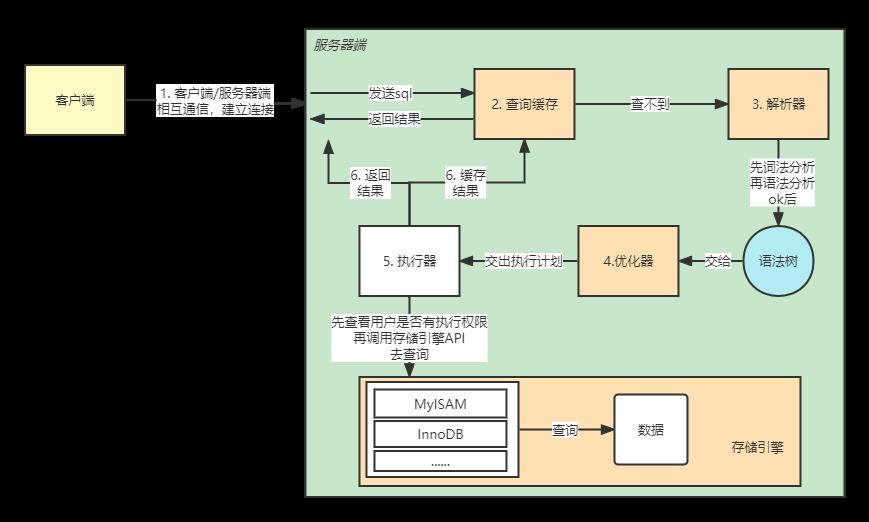
SQL语句在MySQL中的执行流程,大体可以分为:

客户端将一条SQL语句传给MySQL服务器之后,如果打开了查询缓存的设置,则首先查询缓存,如果没有打开查看缓存或者缓存没命中的话则接着通过解析器解析该SQL语句,解析完成之后就是优化器对SQL语句进行优化,优化完成之后就是执行器执行该SQL语句,并将执行结果返回给客户端。
详细执行流程
SQL语句的详细执行流程如下图所示:
1. 查询缓存
(开启查询缓存设置的情况,MySQL5.7默认是不开启的,MySQL8.0):
Server如果在查询缓存中发现了这条SQL语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高(命中率不高),所以在MySQL8.0之后就抛弃了这个功能。另外,MySQL5.7 默认是不开启查询缓存的。
MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句,之前执行过的语句及结果可能会以key-value对的形式,被直接缓存到内存中。key是查询的语句,value是查询的结果,如果你的查询能够直接在这个缓存中找到key,那么这个value就会被直接返回给客户端。如果查询语句不在查询缓存中,就会继续后面的执行阶段,执行完成后,执行结果会被存入查询缓存中。所以,如果查询命令缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率很高。
但是。。。。。。。。。。
大多数情况下,查询缓存就是一个鸡肋,主要有如下几个原因:
- 查询命中率不高,
在MySQL中的查询缓存,不是缓存查询计划,而是查询对应的结果,只有相同的查询操作才会命令查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会被命中,因此MySQL的查询缓存命中率不高。
如果查询请求中包含某些系统函数、用户自定义函数和函数,比如NOW() 函数,每次调用都会产生罪行的当前时间,每次都不能命中查询缓存。 - 查询失效时间短
如果是频繁修改的表,查询缓存也会被被频繁的修改,这样反而加大系统的消耗,导致缓存频繁失效。
总之,因为查询缓存弊大于利,查询缓存的失效非常频繁。
一般建议大家在静态表里使用查询缓存,所谓的静态表,就是极少被更新的数据表,比如:一个系统的配置表,字典表,这张表上的查询才适合使用查询缓存。
查看查询缓存是否开启
在MySQL 5.7中通过如下命令查看当前MySQL实例是否开启缓存机制
show variables like 'query_cache_type';

默认情况是不开启的,后面会详细介绍如何开启查询缓存。query_cache_type 有三个值,0代表关闭查询缓存OFF,1代表开启ON,2表示按需开启,如果设置为2的话,当需要使用到查询缓存时,可以使用 SQL_CACHE,像下面这个语句一样:
SELECT SQL_CACHE * FROM test WHERE ID=10;
监控查询缓存的命中率
通过下面的命令可以监控查询缓存的命中率:
show status like '%Qcache%';
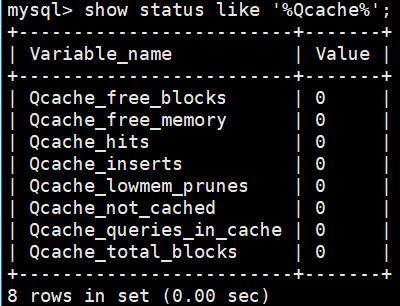
运行结果解析:
- Qcache_free_blocks: 表示查询缓存中还有多少剩余的blocks,如果该值显示较大,这说明查询缓存中的内存碎片过多,可能在一定的时间进行整理。
- Qcache_free_memory: 查询缓存的内存大小,通过这个参数可以很清晰的指导当前系统的查询内存是否够用,是多了,还是不够用,DBA可以根据实际情况做出调整。
- Qcache_hits: 表示有多少次命令缓存,我们主要可以通过该值来验证我们的查询缓存的效果,数字越大,缓存效果越理想。
2. 解析器
在解析器中对SQL语句进行语法分析,语义分析。
如果没有命令查询缓存,就要开始真正执行语句了。首先,MySQL需要知道你要做什么,因此需要对SQL语句做解析,SQL语句的分析分为词法分析与语法分析。
分析器先做**“词法分析”**,你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。
MySQL从你输入的SELECT 这个关键字识别出来,这是一个查询语句,它也要把字符串"T" 识别成"表名T",把字符串"ID" 识别成"列ID"。
接着,要做"语法分析"。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输入的这个SQL语句是否满足SQL语法。
如果你的语句不对,就会收到"You have an error in your SQL syntax" 的错误提示,比如下面这个语句"from" 写成了 “fro”。
mysql> SELECT * FRO test WHERE ID=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FRO test WHERE ID=1' at line 1
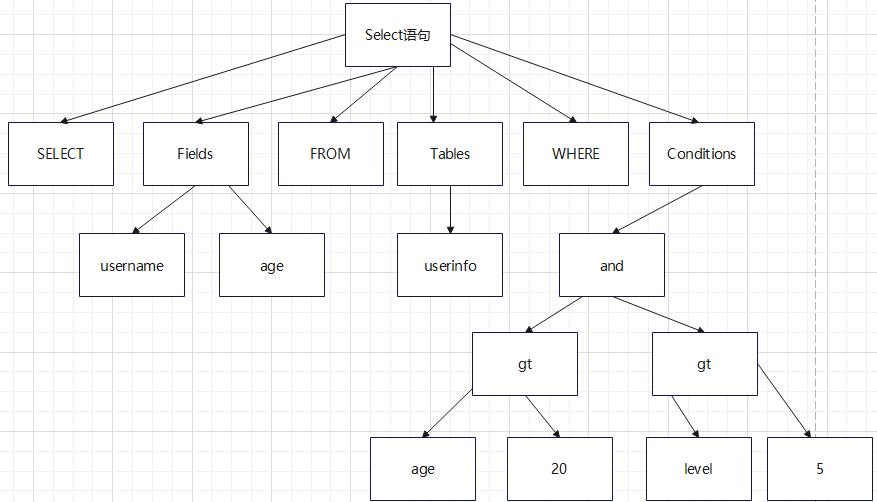
如果SQL语句正确,则会生成一个这样的语法树:
以如下SQL进行说明:
SELECT username,age FROM userinfo WHERE age>20 and level>5;
下面是SQL词法分析的过程步骤:
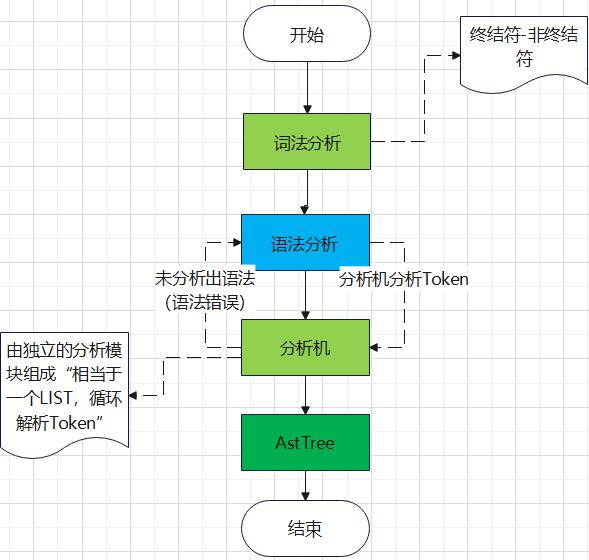
解析器的基本工作就是进行词法分析以及语法分析,达到一个语法树,然后交给它的下游。
3. 优化器
在优化器中会确定SQL语句的执行路径,比如是根据 全表检索,还是根据 索引检索等。
经过解析器,MySQL就知道你要做什么,在开始执行之前,还要先经过优化器的处理,一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
比如:优化器是在表里面多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候决定各个表的连接顺序,还有表达式简化、子查询转为连接,外连接转为内连接等。
举例:如下语句是执行两个表的join;
SELECT * FROM test1 join test2 using(ID)
WHERE test1.name='zhangsan' and test2.name='MySQL从入门到精通课程';
方案一:可以先从表test1里面取出name=‘zhangsan’的记录ID值,在根据ID值关联表test2,在判断test2里面name的值是否等于’MySQL从入门到精通课程’。
方案二:可以先从表test2里面取出name='MySQL从入门到精通课程’的记录的ID值,再根据ID值关联到test1,再判断test1里面name的值是否等于zhangsan。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有所不同,而优化器的作用就是决定选择使用哪一种方案,优化器阶段完成后, 这个语句的执行方案就确定下来了,然后进入执行器阶段。
在查询优化器中,可以分为逻辑查询优化阶段和物理查询优化阶段。
逻辑查询优化就是通过改变SQL语句的内容来使得SQL查询更高效,同时为物理查询优化提供更多的候选执行计划。通常采用的方式是对SQL语句进行等价变换,对查询进行重写,而查询重写的数学基础就是关系代数。对条件表达式进行等价谓词重写、条件简化,对视图进行重写,对子查询进行优化,对连接语义进行了外连接消除,嵌套连接消除等。
物理查询优化是基于关系代数进行的查询重写,而关系代数的每一步都对应着物理计算,这些物理计算往往存在多种算法,因此需要计算各种物理路径的代价,从而选择代价最小的作为执行计划。在这个阶段里,对于单表和多表连接的操作,需要高效地使用索引,提升查询效率。
4. 执行器:
截止到目前,还没有真正去读写真实的表,仅仅只是产生了一个执行计划,于是就进入了执行器阶段。
在执行之前需要判断该用户是由具备权限,如果没有,就会返回权限错误。如果具备权限,就执行SQL查询并返回结果。在MySQL8.0以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
SELECT * FROM test WHERE id=1;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,调用存储引擎API对表进行读写。存储引擎API只是抽象接口,下面还有个存储引擎层,具体实现还是要看表选择的存储引擎。
比如:表test中,ID字段没有索引,那么执行器的执行流程是这样的:
调用InnoDB引擎接口取这个表的第一行,判断ID值是不是1,如果不是则跳过,如果是则将这行存在结果集中;调用引擎接口取"下一行",重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了,对于有索引的表,执行的逻辑也差不多。
SQL执行流程的演示
既然一条SQL语句会经历不同的模块,那我们就来看下,在不同的模块下,SQL执行所使用的资源(时间)是怎样的。如何在MySQL中对一条SQL语句的执行时间进行分析。
1. 确认profiling是否开启
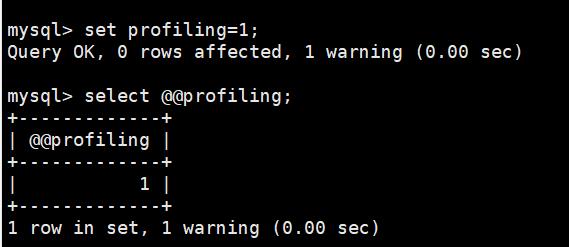
了解查询语句底层执行的过程:select @@profiling; 或者show variables like '%profiling%' 查看是否开启计划。开启它可以让MySQL收集在SQL执行时所使用的资源情况,命令如下:
# 默认查询的是session级别的,如果要查询全局级别的则可以使用 select @@global.profiling;
mysql> select @@profiling;
mysql> show variables like 'profiling';

profiling=0代表关闭,我们需要把profiling打开,即设置为1;
mysql> set profiling=1;
Profiling功能由MySQL会话变量:profiling控制,默认是OFF(关闭状态)。
2. 多次执行相同SQL查询
然后我们执行任意一个SQL查询。
SELECT * FROM customer limit 100;

接着就是通过如下命令查看每条SQL的执行时间。
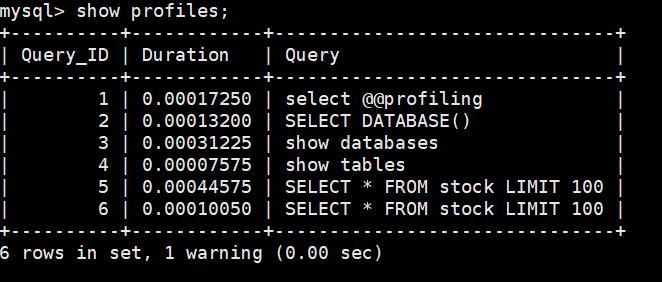
mysql> show profiles;
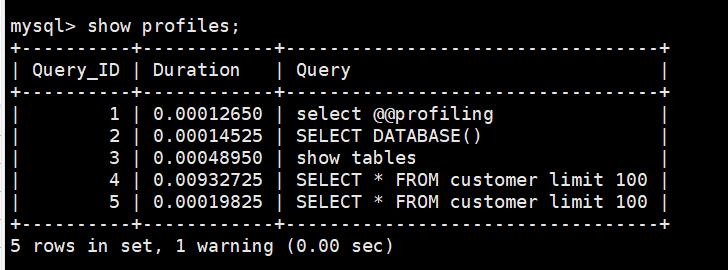
如果要查看最近一条SQL语句的具体执行计划可以通过如下命令;
mysql> show profile;
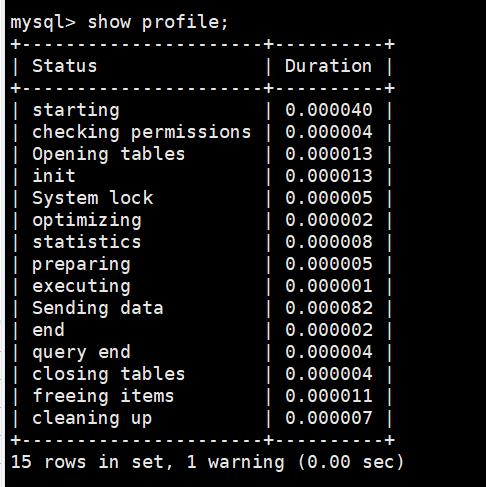
这里详细展示了SQL语句SELECT * FROM customer limit 100; 在每一步的执行耗时,包括开始,检查权限,打开数据表,初始化,系统锁等等。
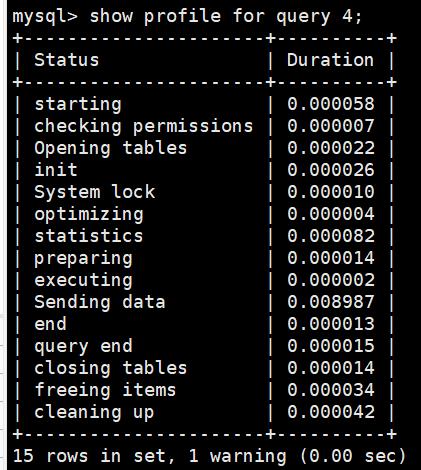
如果要查询具体某条SQL的详细执行情况可以通过如下命令;
mysql> show profile for query [Query_ID];
比如查询Query_ID为4的SQL语句的执行情况。
开启查询缓存
1. 在配置文件开启查询缓存
在/etc/my.cnf 中新增一行:
query_cache_type=1
2.重启mysql服务
systemctl restart mysqld
3.开启查询执行计划
由于重启过服务,需要重新执行如下指令,开启profiling。
mysql> set profiling=1;
- 执行语句两次:
mysql>SELECT * FROM stock LIMIT 100;
mysql>SELECT * FROM stock LIMIT 100;
执行之后查询SQL语句的总耗时,发现第二次执行时的总耗时明显比第一执行时要短很多。
在分别查看SQL语句在每个环节中的耗时,发现第一次执行SQL语句时共有29个状态

而第二次执行时只有9个状态,并且可以看到 sending cached result to client 这个状态,故,第二次查询是从查询缓存中直接返回数据。

当然,profile命令除了查询耗时,还可以查询每个阶段耗费cpu,io的情况。

需要注意的是SQL语句必须完全一致才能命中缓存,否则不能命中缓存。
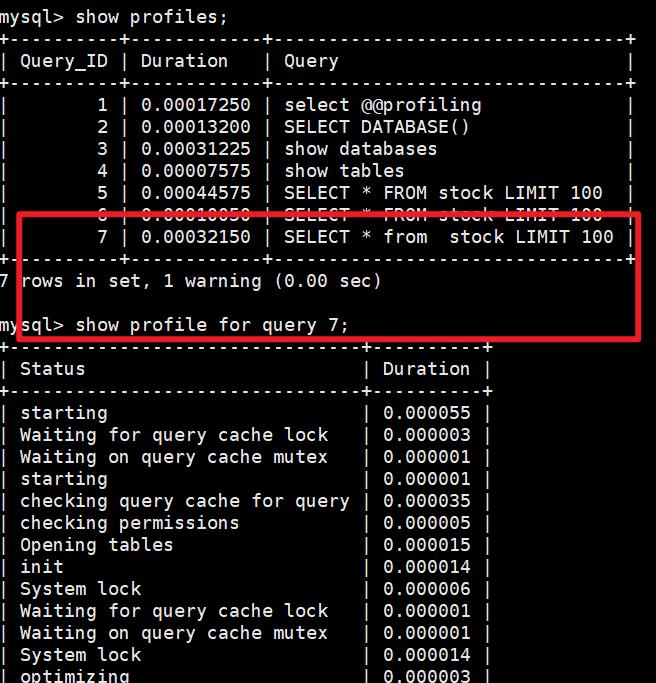
现在将上面的那个查询语句稍微修改下;
SELECT * from stock LIMIT 100;
将form改成小写,在from和stock之间增加空格,发现不能命中缓存。
总结
熟练掌握SQL的执行流程非常非常的重要!!
本文主要就是三点;
- 不建议开启查询缓存
- SQL的执行过程主要是:SQL语句–>查询缓存–>解析器—>优化器—>执行器
- 通过 select profiles可以查询所有sql的执行耗时,通过select profile 可以查询最近一条sql的每个阶段的耗时
以上是关于MySQL从入门到精通高级篇MySQL的SQL语句执行流程的主要内容,如果未能解决你的问题,请参考以下文章
MySQL从入门到精通高级篇(二十二)慢查询日志分析,SHOW PROFILE查看SQL执行成本
MySQL从入门到精通高级篇(二十二)慢查询日志分析,SHOW PROFILE查看SQL执行成本