我用免费白拿的服务器搭建了一台基于CentOS7的Hadoop3.x伪分布式环境
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我用免费白拿的服务器搭建了一台基于CentOS7的Hadoop3.x伪分布式环境相关的知识,希望对你有一定的参考价值。
文章目录
前言
最近在和粉丝的交流中,说到白嫖的服务器还没开始用,这里我提供一种使用方式:
她提到伪分布式部署Hadoop的概念启发了我。
由于我接的私活经常需要使用到Hadoop集群,本地启动有启动速度慢、操作麻烦和占用内存等诟病,
有鉴于此何不部署云集群,选择的是Hadoop3.x的伪分布式部署方法。

1. 白嫖服务器
之前发过一篇白嫖服务器的指南:
阿里云双十一服务器注册流程
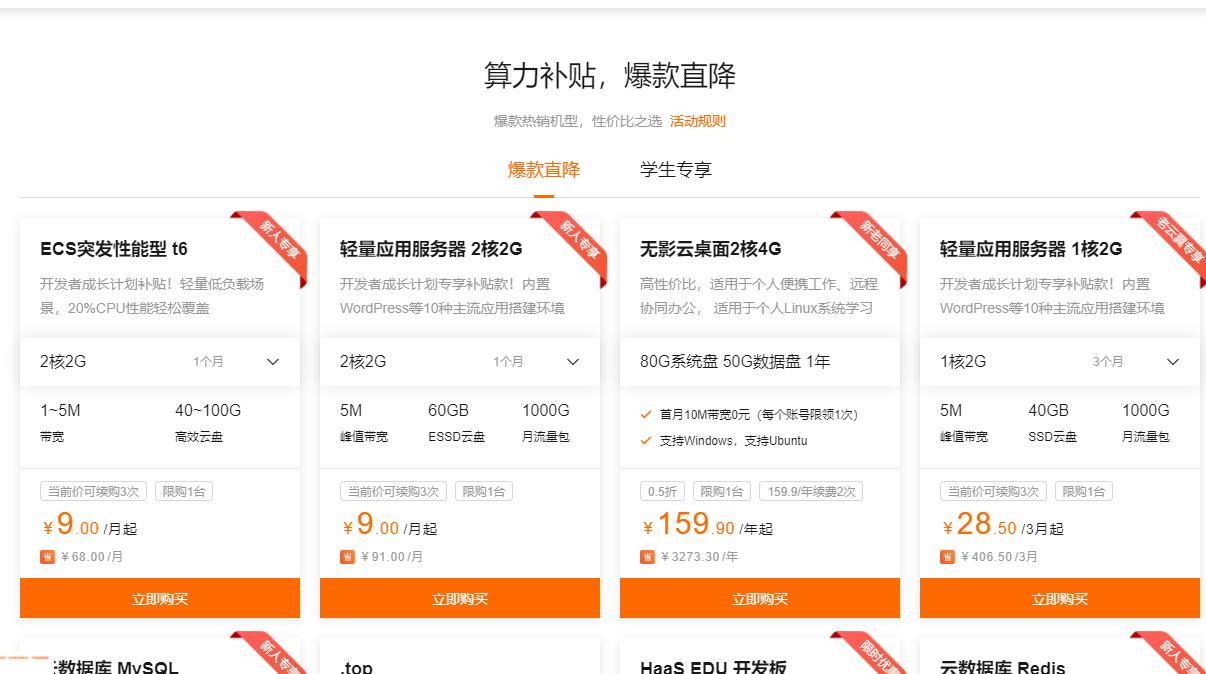
不过现在活动结束了。当然如果你是学生,买服务器还是很便宜的,只需要9.9元/月,
阿里云开发者成长计划
2. 服务器选择和配置
这里选择的是轻量服务器,系统镜像和应用镜像不需要改变,保持默认值就行(WordPress, CentOS 7.3)

这里需要设置root权限和密码
设置成功后通过本地terminal(MAC)或者cmd(Windows)来构建ssh
ssh root@****
然后输入之前设置的root的权限的密码(注意:这里的密码是不会有任何显示的)
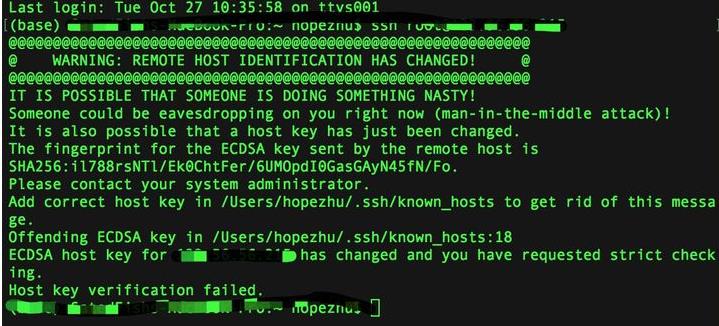
若出现上图的情况,需要清理一下之前的key
ssh-keygen -R XX.XX.XX.XX
然后再次用ssh连接,然后yes

好,到此我们进入到了阿里云的服务器
3. 我们开始配置java环境
首先下载java的jdk
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
然后解压
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
移动位置并且配置java路径
mv java-se-8u41-ri/ /usr/java8
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
检查是否安装成功
java -version
这是理想情况,若安装成功会出现如下结果

4. 我们进行Hadoop的安装
# 借助清华源下载Hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
#这儿是清华的镜像源,国内的小伙伴下载比较快
按照惯例解压
tar -zxvf hadoop-3.2.2.tar.gz -C /opt/
mv /opt/hadoop-3.2.2 /opt/hadoop
hadoop2.x(2022.06.12更新)
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
tar -zxvf hadoop-2.10.1.tar.gz -C /opt/
mv /opt/hadoop-2.10.1 /opt/hadoop
配置地址
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
配置yarn和hadoop
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
查看Hadoop 安装情况
hadoop version

若出现上图情况,则说明安装成功
5. 接下来需要利用vim来操作core-site 和 hdfs-site
vim /opt/hadoop/etc/hadoop/core-site.xml
进入vim环境

按下i(insert)修改
光标移动至configuration之间,复制如下的信息
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
然后按下esc,停止修改,然后打":wq"(实际无“”)退出vim修改
同理操作hdfs-site
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
配置master和slave连接,运行如下指令,并且一直回车,直至出现如下图
ssh-keygen -t rsa

运行如下代码
cd .ssh
cat id_rsa.pub >> authorized_keys
启动Hadoop
hadoop namenode -format
start-dfs.sh
start-yarn.sh
踩坑:
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation
这里踩了一个小坑,
解决方案:
https://blog.csdn.net/ystyaoshengting/article/details/103026872
查看是否配置成功
jps
成功图

6. 注意:接下来需要开启你在阿里云的防火墙端口,才可以在浏览器上访问,否则你怎么弄都是访问不到

最后你就可以在浏览器输入XX.XX.XX.XX**:9870 或者**XX.XX.XX.XX:8088来在浏览器上访问你的Hadoop
效果图如下

以及

HDFSAPI(新)
格式化一下
hdfs namenode -format
hadoop-daemon.sh start namenode
https://manor.blog.csdn.net/article/details/122017204
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 manor 原创,首发于 CSDN博客🙉
⚠️ 若本文所采用图片或相关引用侵犯了您的合法权益,请联系我进行删除。
😄 欢迎大家指出文章错误,与我交流 ~
关于Hadoop集群部署过程中遇到有什么问题,欢迎关注公众号咨询我~

以上是关于我用免费白拿的服务器搭建了一台基于CentOS7的Hadoop3.x伪分布式环境的主要内容,如果未能解决你的问题,请参考以下文章
我用免费白拿的服务器搭建了一台基于CentOS7的Hadoop3.x伪分布式环境
CentOS7基于Apache+php+mysql的许愿墙网站的搭建