C/C++面试必备详解C/C++中volatile关键字
Posted 森明帮大于黑虎帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C/C++面试必备详解C/C++中volatile关键字相关的知识,希望对你有一定的参考价值。
文章目录
- 一、volatile简介
- 二、volatile易变的
- 三、volatile不可优化的
- 四、volatile顺序执行的
- 五、volatile与原子性
- 六、volatile 的作用是什么呢
- 七、volatile的介绍
- 八、volatile的含义
- 九、编译器优化 → C关键字volatile → memory破坏描述符
本文来讲解一下
C/C++ 中的关键字 volatile。在日常的使用中很多使用到,而且在问答中经常被提起,下面具体来看一下。
一、volatile简介
在 C/C++ 编程语言中,volatile 关键字可以用来提醒编译器使用 volatile 声明的变量随时有可能改变,因此编译器在代码编译时就不会对该变量进行某些激进的优化,故而编译生成的程序在每次存储或读取该变量时,都会直接从内存地址中读取数据。相反,如果该变量没有使用 volatile 关键字进行声明,则编译器可能会优化读取和存储操作,可能暂时使用寄存器中该变量的值,而如果这个变量由别的程序(线程)更新了的话,就会出现(内存中与寄存器中的)变量值不一致的现象。
在 C/C++ 编程语言中,使用 volatile 关键字声明的变量具有三种特性:易变的、不可优化的、顺序执行的。下面分别对这三种特性进行介绍。
二、volatile易变的
在 C/C++ 编程语言中,volatile 的易变性体现在:假设有读、写两条语句,依次对同一个 volatile 变量进行操作,那么后一条的读操作不会直接使用前一条的写操作对应的 volatile 变量的寄存器内容,而是重新从内存中读取该 volatile 变量的值。
上述描述的(部分)示例代码内容如下:
volatile int nNum = 0; // 将nNum声明为volatile
int nSum = 0;
nNum = FunA(); // nNum被写入的新内容,其值会缓存在寄存器中
nSum = nNum + 1; // 此处会从内存(而非寄存器)中读取nNum的值
三、volatile不可优化的
在 C/C++ 编程语言中,volatile 的第二个特性是“不可优化性”。volatile 会告诉编译器,不要对 volatile 声明的变量进行各种激进的优化(甚至将变量直接消除),从而保证程序员写在代码中的指令一定会被执行。
上述描述的(部分)示例代码内容如下:
volatile int nNum; // 将nNum声明为volatile
nNum = 1;
printf("nNum is: %d", nNum);
在上述代码中,如果变量 nNum 没有声明为 volatile 类型,则编译器在编译过程中就会对其进行优化,直接使用常量“1”进行替换(这样优化之后,生成的汇编代码很简介,执行时效率很高)。而当使用 volatile 进行声明后,编译器则不会对其进行优化,nNum 变量仍旧存在,编译器会将该变量从内存中取出,放入寄存器之中,然后再调用 printf() 函数进行打印。
四、volatile顺序执行的
在 C/C++ 编程语言中,volatile 的第三个特性是“顺序执行特性”,即能够保证 volatile 变量间的顺序性不会被编译器进行乱序优化。
C/C++ 编译器最基本优化原理:保证一段程序的输出,在优化前后无变化。
为了对本特性进行深入了解,下面以两个变量(nNum1 和 nNum2)为例(既然存在“顺序执行”,那描述对象必然大于一个),介绍 volatile 的顺序执行特性,示例代码内容如下:
int nNum1;
int nNum2;
nNum2 = nNum1 + 1; // 语句1
nNum1 = 10; // 语句2
在上述代码中:
- 当
nNum1 和 nNum2都没有使用volatile关键字进行修饰时,编译器会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”;
当nNum2 使用 volatile关键字进行修饰时,编译器也可能会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”; - 当
nNum1 和 nNum2都使用 volatile 关键字进行修饰时,编译器不会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句1”、再执行“语句2”;
说明:上述论述可通过观察代码的生成的汇编代码进行验证。
五、volatile与原子性
volatile不保证原子性,它只是保证每次都做真实的数据访问,编译器不去优化它,要实现原子性需要加锁。
对于多线程编程而言,在临界区内部,可以通过互斥锁(mutex)保证只有一个线程可以访问该临界区的内容,因此临界区内的变量不需要是 volatile 的;而在临界区外部,被多个线程访问的变量应声明为 volatile 的,这也符合了 volatile 的原意:防止编译器缓存(cache)被多个线程并发用到的变量。
不过,需要注意的是,由于 volatile 关键字的“顺序执行特性”并非会完全保证语句的顺序执行(如 volatile 变量与非 volatile 变量之间的操作;又如一些 CPU 也会对语句的执行顺序进行优化),因此导致了对 volatile 变量的操作并不是原子的,也不能用来为线程建立严格的 happens-before 关系。
int nNum1 = 0;
volatile bool flag = false;
thread1()
// some code
nNum1 = 666; // 语句1
flag = true; // 语句2
thread2()
// some code
if (true == flag)
// 语句3:按照程序设计的预想,此处的nNum1的值应为666,并据此进行逻辑设计
在上述代码中,我们的设计思路是先执行 thread1() 中的“语句1”、“语句2”、再执行 thread2() 中的“语句3”,不过实际上程序的执行结果未必如此。根据前面介绍的 volatile 的“并非会完全保证语句的顺序执行”特性,非 volatile 变量 nNum1 和 volatile 变量 flag 的执行顺序,可能会被编译器(或 CPU)进行乱序优化,最终导致 thread1() 中的“语句2”先于“语句1”执行,当“语句2”执行完成但“语句1”尚未执行时,此时 thread2() 中的判断语句“if (true == flag)”是成立的,但实际上 nNum1 尚未进行赋值操作(语句 1 尚未执行),所以在判断语句中针对“nNum1 == 666”的前提下进行的逻辑设计,就会有问题了。
这是一个在多线程编程中,使用 volatile 不容易发现的问题。
实际上,上述多线程代码想实现的就是一个 happens-before 语义,即保证 thread1() 代码块中的所有代码一定要在 thread2() 代码块的第一条代码之前完成。使用互斥锁(mutex)可以保证 happens-before 语义。但是,在 C/C++ 编程语言中的 volatile 关键字不能保证这个语义,也就意味着在多线程环境下使用 C/C++ 编程语言的 volatile 关键字,如果不够细心,就可能会出现上述问题。所以,使用 C/C++ 编程语言进行多线程编程时,要慎用 volatile 关键字。
六、volatile 的作用是什么呢
volatile 意思是易变的,是一种类型修饰符,在C/C++中用来阻止编译器因误认某段代码无法被代码本身所改变,而造成的过度优化。编译器每次读取 volatile 定义的变量时,都从内存地址处重新取值。
这里就有点疑问了,难道编译器取变量的值不是从内存处取吗?
并不全是,编译器有时候会从寄存器处取变量的值,而不是每次都从内存中取。因为编译器认为变量并没有变化,所以认为寄存器里的值是最新的,另外,通常来说,访问寄存器比访问内存要快很多,编译器通常为了效率,可能会读取寄存器中的变量。但是,变量在内存中的值可能会被其它元素修改,比如:硬件或其它线程等。
来看一个实际的例子:
#include <stdio.h>
int main()
const int value = 10;
int *ptr = (int*) &value;
printf("初始值 : %d \\n", value);
*ptr = 100;
printf("修改后的值 : %d \\n", value);
return 0;
编译程序,执行命令:
linuxy@linuxy:~/volatile$ gcc main.c -o main
运行后输出:
linuxy@linuxy:~/volatile$ gcc main.c -o main
linuxy@linuxy:~/volatile$ ./main
初始值 : 10
修改后的值 : 100
linuxy@linuxy:~/volatile$
可以看到 value 的值变化了。
接下来再看一下编译时添加 -O 参数优化的情况,执行命令 gcc -O main.c -o main。
输出结果为:
linuxy@linuxy:~/volatile$ gcc -O main.c -o main
linuxy@linuxy:~/volatile$ ./main
初始值 : 10
修改后的值 : 10
linuxy@linuxy:~/volatile$
可以看到添加 -O 参数优化后, value 的值并没有变化,这里就有问题了。是因为添加了 -O 参数,编译器对代码进行了优化,忽略了对变量 value 值的更改。
-O 参数:
使用该参数,编译器会尝试减少代码大小和执行时间,但不执行需要占用大量编译时间的优化。优化编译需要占用更多的时间,对于大型函数需要占用更大的内存。
来看一下上面例子优化前和优化后代码大小的对比:
linuxy@linuxy:~/volatile$ gcc main.c -o main
linuxy@linuxy:~/volatile$ ls -al main
-rwxrwxr-x 1 linuxy linuxy 16752 7月 18 14:38 main
linuxy@linuxy:~/volatile$ gcc -O main.c -o main
linuxy@linuxy:~/volatile$ ls -al main
-rwxrwxr-x 1 linuxy linuxy 16704 7月 18 14:38 main
linuxy@linuxy:~/volatile$
可以看到,优化后文件变小了。
那再看一下给上面的代码添加上 volatile 关键字后会怎样?
#include <stdio.h>
int main()
volatile const int value = 10;
int *ptr = (int*) &value;
printf("初始值 : %d \\n", value);
*ptr = 100;
printf("修改后的值 : %d \\n", value);
return 0;
执行命令编译程序:
linuxy@linuxy:~/volatile$ gcc -O main.c -o main
输出为:
linuxy@linuxy:~/volatile$ gcc -O main.c -o main
linuxy@linuxy:~/volatile$ ./main
初始值 : 10
修改后的值 : 100
linuxy@linuxy:~/volatile$
可以看到,即使添加了 -O 参数优化程序, value 的值依然被改变了。
最后,看一下 volatile 是怎样使用的。
1.修饰普通变量
volatile 类型 变量
类型 volatile 变量
volatile 放置到类型前后都可以。例如:
#include <stdio.h>
int main()
volatile int a = 10;
int volatile b = 20;
printf("a = %d\\nb = %d\\n", a, b);
编译后输出:
linuxy@linuxy:~/volatile$ gcc -o main main.c
linuxy@linuxy:~/volatile$ ./main
a = 10
b = 20
linuxy@linuxy:~/volatile$
2.修饰指针
修饰指针和 const 类似(volatile 和 const 都是类型修饰符),有三种形式:
volatile int *p;
int* volatile p;
volatile 类型* volatile 变量;
看一下具体的代码:
#include <stdio.h>
int main()
int a = 10;
volatile int* p = &a;
int* volatile q = &a;
volatile int* volatile x = &a;
printf("*p = %d\\n*q = %d\\n*x = %d\\n", *p, *q, *x);
编译后输出:
linuxy@linuxy:~/volatile$ gcc -o main main.c
linuxy@linuxy:~/volatile$ ./main
*p = 10
*q = 10
*x = 10
linuxy@linuxy:~/volatile$
3.作为函数参数
作为函数参数需要注意,例如:
int square(volatile int *ptr)
return *ptr * *ptr;
编译器处理的逻辑类似于以下情况:
int square(volatile int *ptr)
int a,b;
a = *ptr;
b = *ptr;
return a * b;
因为 ptr 被声明为 volatile,所以 a 和 b 的值可能是不一样的,所以最好采用如下这种方式:
long square(volatile int *ptr)
int a;
a = *ptr;
return a * a;
七、volatile的介绍
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:

这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:

需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
volatile的本意是“易变的”,由于访问寄存器的速度要快过RAM,所以编译器一般都会作减少存取外部RAM的优化。比如:
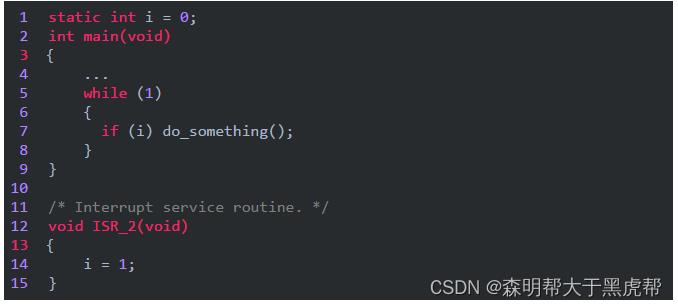
程序的本意是希望ISR_2中断产生时,在main当中调用do_something函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致do_something永远也不会被调用。如果变量加上volatile修饰,则编译器保证对此变量的读写操作都不会被优化(肯定执行)。此例中i也应该如此说明。
一般说来,volatile用在如下的几个地方:
- 1、中断服务程序中修改的供其它程序检测的变量需要加
volatile; - 2、多任务环境下各任务间共享的标志应该加
volatile; - 3、存储器映射的硬件寄存器通常也要加
volatile说明,因为每次对它的读写都可能由不同意义; - 另外,以上这几种情况经常还要同时考虑数据的完整性(相互关联的几个标志读了一半)。
八、volatile的含义
volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以死代码消除。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化,volatile的字面含义是易变的,它有下面的作用:
1.不会在两个操作之间把volatile变量缓存在寄存器中
在多任务、中断、甚至setjmp环境下,变量可能被其他的程序改变,编译器自己无法知道,volatile就是告诉编译器这种情况
2.不做常量合并、常量传播等优化

if的条件不会当作无条件真。
3.对volatile变量的读写不会被优化掉
如果你对一个变量赋值但后面没用到,编译器常常可以省略那个赋值操作,然而对Memory Mapped IO的处理是不能这样优化的。
前面有人说volatile可以保证对内存操作的原子性,这种说法不大准确,其一,x86需要LOCK前缀才能在SMP下保证原子性,其二,RISC根本不能对内存直接运算,要保证原子性得用别的方法,如atomic_inc。
对于jiffies,它已经声明为volatile变量,我认为直接用jiffies++就可以了,没必要用那种复杂的形式,因为那样也不能保证原子性。你可能不知道在Pentium及后续CPU中,下面两组指令作用相同,但一条指令反而不如三条指令快。

九、编译器优化 → C关键字volatile → memory破坏描述符
memory比较特殊,可能是内嵌汇编中最难懂部分。为解释清楚它,先介绍一下编译器的优化知识,再看C关键字volatile。最后去看该描述符。
1.编译器优化介绍
内存访问速度远不及CPU处理速度,为提高机器整体性能,在硬件上引入硬件高速缓存Cache,加速对内存的访问。另外在现代CPU中指令的执行并不一定严格按照顺序执行,没有相关性的指令可以乱序执行,以充分利用CPU的指令流水线,提高执行速度。以上是硬件级别的优化。再看软件一级的优化:一种是在编写代码时由程序员优化,另一种是由编译器进行优化。编译器优化常用的方法有:将内存变量缓存到寄存器;调整指令顺序充分利用CPU指令流水线,常见的是重新排序读写指令。对常规内存进行优化的时候,这些优化是透明的,而且效率很好。由编译器优化或者硬件重新排序引起的问题的解决办法是在从硬件(或者其他处理器)的角度看必须以特定顺序执行的操作之间设置内存屏障(memory barrier),linux 提供了一个宏解决编译器的执行顺序问题。

这个函数通知编译器插入一个内存屏障,但对硬件无效,编译后的代码会把当前CPU寄存器中的所有修改过的数值存入内存,需要这些数据的时候再重新从内存中读出。
2.C语言关键字volatile
C语言关键字volatile(注意它是用来修饰变量而不是上面介绍的volatile)表明某个变量的值可能在外部被改变,因此对这些变量的存取不能缓存到寄存器,每次使用时需要重新存取。该关键字在多线程环境下经常使用,因为在编写多线程的程序时,同一个变量可能被多个线程修改,而程序通过该变量同步各个线程,例如:
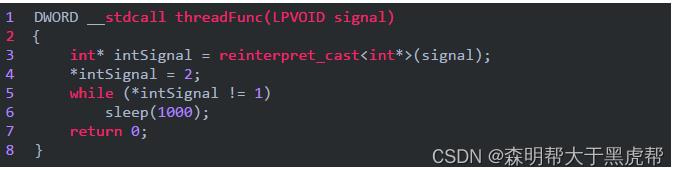
该线程启动时将intSignal置为2,然后循环等待直到intSignal为1时退出。显然intSignal的值必须在外部被改变,否则该线程不会退出。但是实际运行的时候该线程却不会退出,即使在外部将它的值改为1,看一下对应的伪汇编代码就明白了:

对于C编译器来说,它并不知道这个值会被其他线程修改。自然就把它cache在寄存器里面。记住,C 编译器是没有线程概念的!这时候就需要用到volatile。volatile 的本意是指:这个值可能会在当前线程外部被改变。也就是说,我们要在threadFunc中的intSignal前面加上volatile关键字,这时候,编译器知道该变量的值会在外部改变,因此每次访问该变量时会重新读取,所作的循环变为如下面伪码所示:

3.memory破坏描述符
有了上面的知识就不难理解Memory修改描述符了,Memory描述符告知GCC:
- 1)不要将该段内嵌汇编指令与前面的指令重新排序;也就是在执行内嵌汇编代码之前,它前面的指令都执行完毕。
- 2)不要将变量缓存到寄存器,因为这段代码可能会用到内存变量,而这些内存变量会以不可预知的方式发生改变,因此
GCC插入必要的代码先将缓存到寄存器的变量值写回内存,如果后面又访问这些变量,需要重新访问内存。 - 3)如果汇编指令修改了内存,但是
GCC本身却察觉不到,因为在输出部分没有描述,此时就需要在修改描述部分增加“memory”,告诉GCC内存已经被修改,GCC得知这个信息后,就会在这段指令之前,插入必要的指令将前面因为优化Cache到寄存器中的变量值先写回内存,如果以后又要使用这些变量再重新读取。 - 4)使用
“volatile”也可以达到这个目的,但是我们在每个变量前增加该关键字,不如使用“memory”方便。
以上是关于C/C++面试必备详解C/C++中volatile关键字的主要内容,如果未能解决你的问题,请参考以下文章