鲲鹏arrch64系统编译安装Hadoop3.2.2
Posted 随心~稳心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了鲲鹏arrch64系统编译安装Hadoop3.2.2相关的知识,希望对你有一定的参考价值。
目录
背景
安装好的hbase2.4.8不能使用hadoop的LZ4压缩算法,hadoop checknative检查所有的算法都是false,x86下安装是支持这些的。搜索得知官方的算法编译的是x86版本的,我们使用arm就需要自己下载源码进行编译后使用
hadoop 不能加载native-hadoop library问题
借鉴x86下的步骤
Hadoop-3.2.2源码编译环境搭建
官网下载hadoop的源码版本Index of /dist/hadoop/common/hadoop-3.2.2 (apache.org)
上传到服务器,解压
tar -zxvf /opt/package/hadoop-3.2.2-src.tar.gz
准备编译环境
根据解压出来的文件,查看BUILDING.txt
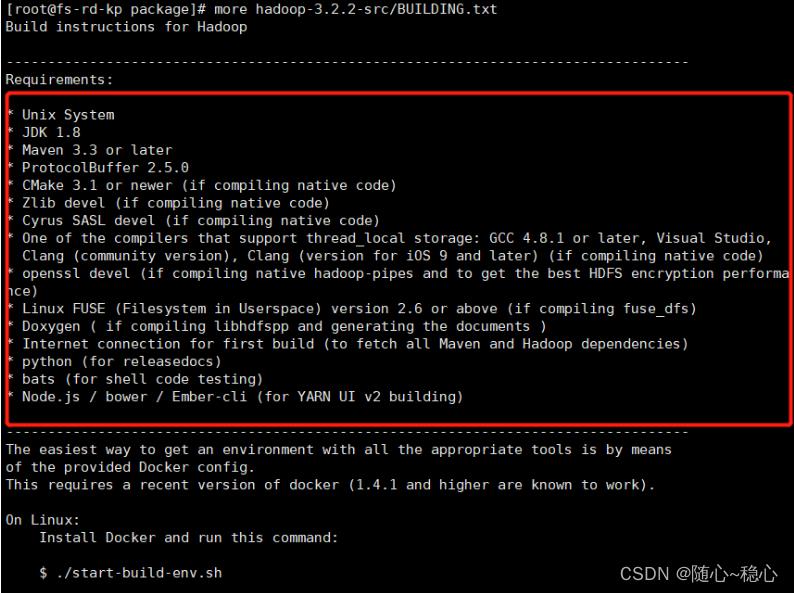
所以我们需要准备这些包
还有一些其他的包我们也可以根据需要来装
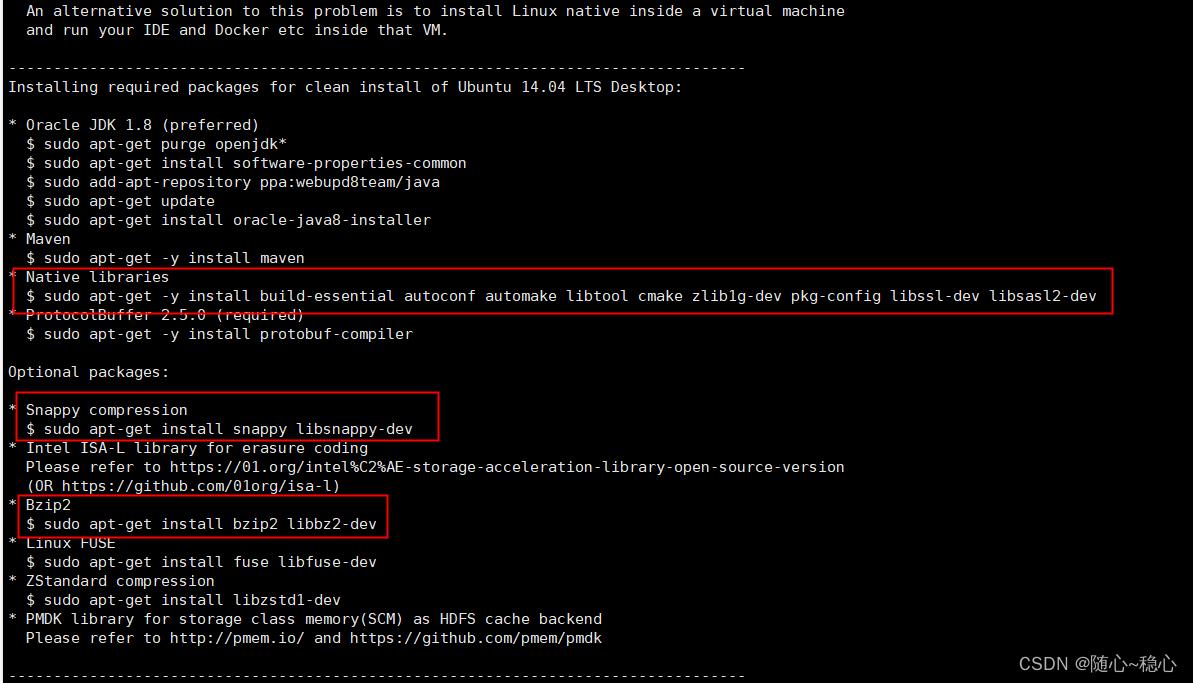
yum install protobuf protobuf-devel
如果看到是2.5.0就直接安装就好
华为云上有所有组件的安装步骤
安装Protobuf_鲲鹏BoostKit大数据使能套件_移植指南(Apache)_Druid 0.
一开始没用yum安装,下载了网上的tgz包,比较坑的一个地方是protobuf2.5.0这个,因为下载的版本不支持arm64的,后来上网找了一圈,原来要打补丁,这里传一个打好补丁的protobuf链接:https://pan.baidu.com/s/1zxUliDQ0woiAWSjVXJlzWw?pwd=o0s4
提取码:o0s4
建议还是用yum安装比较好
PDF是补丁的详情
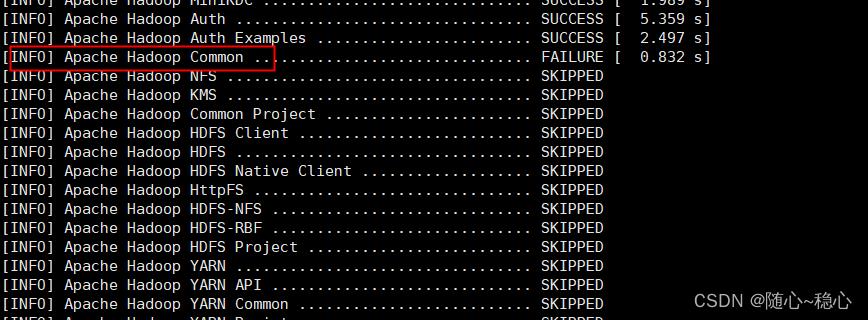
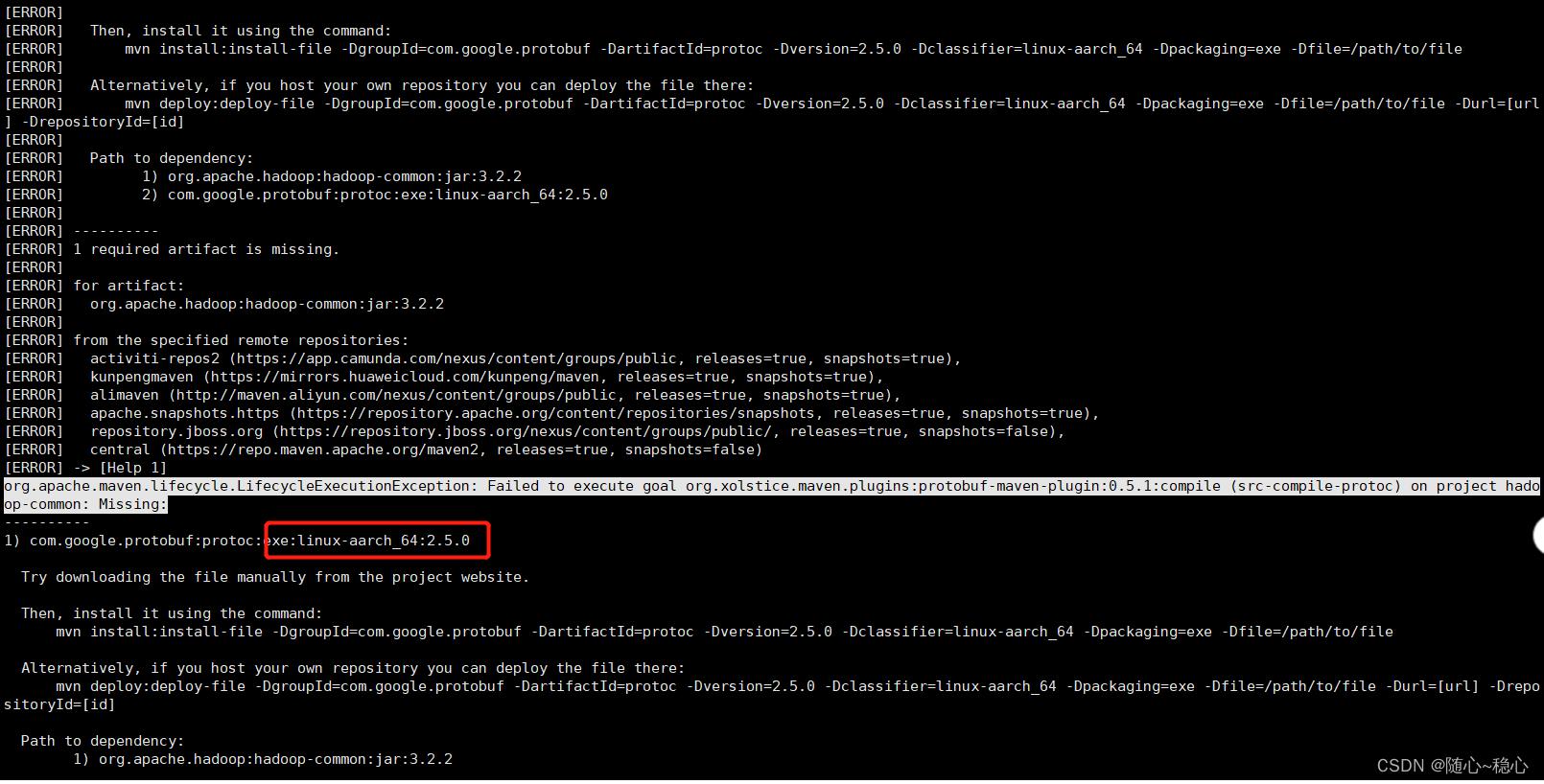
编译过程中出现common包执行错误
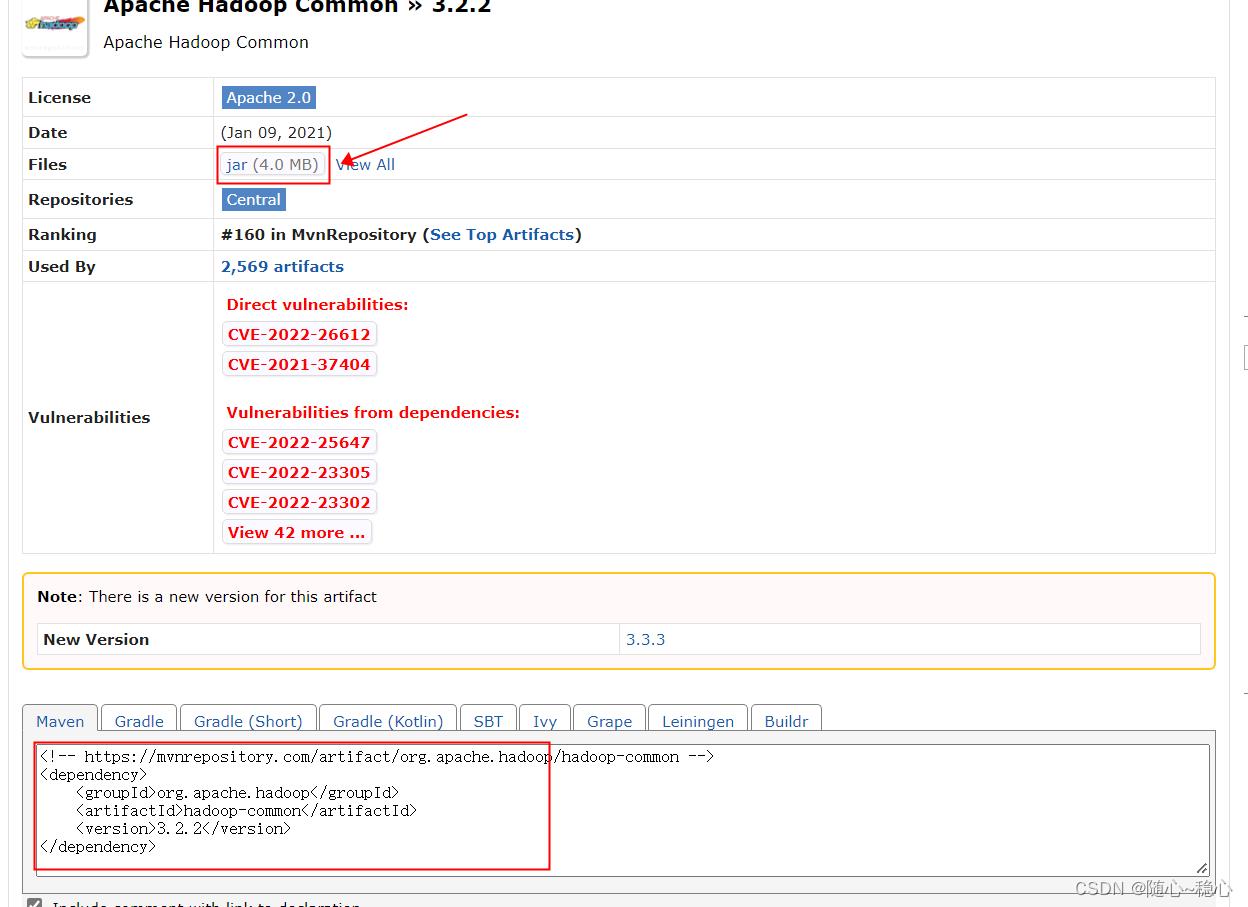
手动去mvn仓库下载
依赖包都安装好后
cd hadoop-3.2.2-src
# 修改pom文件
vi pom.xml
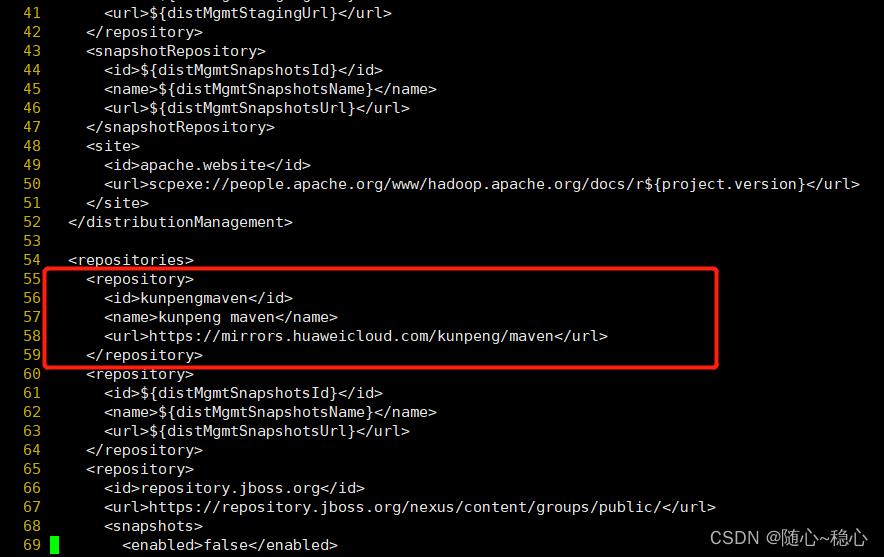
在repositories标签的第一位添加鲲鹏maven仓库源:
<repository>
<id>kunpengmaven</id>
<name>kunpeng maven</name>
<url>https://mirrors.huaweicloud.com/kunpeng/maven</url>
</repository>
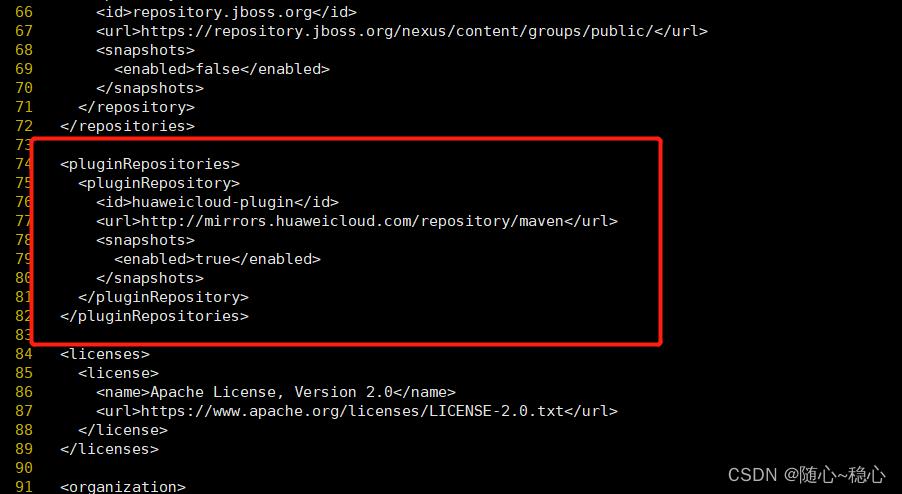
除了依赖仓库源,还要添加插件仓库源,pluginRepositories和repositories的节点级别一样:
<pluginRepositories>
<pluginRepository>
<id>huaweicloud-plugin</id>
<url>http://mirrors.huaweicloud.com/repository/maven</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
开始编译
执行基础编译命令。
mvn package -DskipTests -Pdist,native -Dtar -Dmaven.javadoc.skip=true
(可选)添加snappy库编译命令。
mvn package -DskipTests -Pdist,native -Dtar -Dsnappy.lib=/usr/local/lib64 -Dbundle.snappy -Dmaven.javadoc.skip=true
-Dsnappy.lib=/usr/local/lib64参数为你安装snappy的位置
编译成功后,将在源码下的“hadoop-dist/target/”目录生成tar.gz包
安装Hadoop
下面就和X86版本的安装步骤类似了
1、解压编译出来的tar.gz包
tar -zxvf hadoop-dist/target/hadoop-3.2.2.tar.gz -C /opt/software
重命名
mv /opt/software/hadoop-3.2.2 /opt/software/hadoop
2、配置系统变量
编辑 /etc/profile
vi /etc/profile
在文件末尾添加
#Hadoop Env
export HADOOP_HOME=/opt/software/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
立即生效
source /etc/profile
创建文件夹
指定hadoop的工作目录
mkdir -p /mnt/data/hadoop/tmp
mkdir -p /mnt/data/hadoop/dfs/name
mkdir -p /mnt/data/hadoop/dfs/data
mkdir -p /mnt/data/hadoop/dfs/namesecondary
mkdir -p /mnt/data/hadoop/dfs/edits
mkdir -p /mnt/data/hadoop/logs
配置免密登陆
cd
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
测试 ssh localhost能否成功
如果改了端口号,则是
ssh localhost -p 20022
3、修改Hadoop配置
3.1、配置hadoop-env.sh
vi /opt/software/hadoop/etc/hadoop/hadoop-env.sh
在末尾插入以下内容
export JAVA_HOME=/opt/software/jdk
export HADOOP_LOG_DIR=/mnt/data/hadoop/logs
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/var/run
# 更改ssh端口后需要配置
export HADOOP_SSH_OPTS="-p 20022"
3.2、配置core-site.xml
vi /opt/software/hadoop/etc/hadoop/core-site.xml
在末尾添加以下内容(先把末尾的标签对删除再复制)
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/data/hadoop/tmp</value>
</property>
</configuration>
3.3、配置hdfs-site.xml
vi /opt/software/hadoop/etc/hadoop/hdfs-site.xml
在末尾添加以下内容(先把末尾的标签对删除再复制)
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:9868</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 设置namenode的存储地址 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/data/hadoop/dfs/name</value>
</property>
<!-- 设置datanode的存储地址 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/data/hadoop/dfs/data</value>
</property>
<!-- 设置checkpoint临时映像的存储地址 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/mnt/data/hadoop/dfs/namesecondary</value>
</property>
<!-- 设置secondary namenode的本地工作目录 -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>/mnt/data/hadoop/dfs/edits</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>30</value>
</property>
</configuration>
3.4、配置marpred-site.xml
vi /opt/software/hadoop/etc/hadoop/mapred-site.xml
在末尾添加以下内容(先把末尾的标签对删除再复制)
<configuration>
<!-- 设置MapReduce作业运行时的框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置MapReduce的目录 -->
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/software/hadoop/share/hadoop/mapreduce/*:/opt/software/hadoop/share/hadoop/mapreduce/lib/*</value>
</property>
<!-- 设置历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<!-- 设置历史服务器webapp的地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
</configuration>
3.5、配置yarn-site.xml
vi /opt/software/hadoop/etc/hadoop/yarn-site.xml
在末尾添加以下内容(先把末尾的标签对删除再复制)
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 配置nodemanager服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--配置日志聚合服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs</value>
</property>
<!--配置日志保留时间,单位 秒-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
4、启动
cd /opt/hadoop
1. 格式化
bin/hdfs namenode -format
2. 启动NameNode和DataNode
sbin/start-dfs.sh
jps检查

有这个三个java进程说明启动成功
以上是关于鲲鹏arrch64系统编译安装Hadoop3.2.2的主要内容,如果未能解决你的问题,请参考以下文章
Centos7.6编译安装数据库mysql5.7.22(华为鲲鹏云服务器案例)