教你使用CANN将照片一键转换成卡通风格
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教你使用CANN将照片一键转换成卡通风格相关的知识,希望对你有一定的参考价值。
摘要:这次是将AnimeGAN部署到Ascend 310,从而实现对自己想要图片的一键转换为我们想看到的卡通风格。
本文分享自华为云社区《【CANN训练营】CANN训练营_昇腾AI趣味应用实现AI趣味应用(上)随笔》,作者: Tianyi_Li。
前言
你喜欢动画片,或者说卡通,动漫吗?
我是挺喜欢的。
绚丽多彩的卡通世界从来没有缺失过吸引力。手冢治虫画笔下,那个可以上天入地的阿童木,在与邪恶世界的斗争中教会了我们勇敢与正义。漫画工匠宫崎骏用清新的水彩勾勒出自然的乡村景观,不染一丝现实的尘土。美艳而不可方物的世界令人神往。从《大闹天宫》到《大圣归来》,从《哪吒闹海》到《哪吒之魔童降世》,国漫的发展也不曾落下。恢弘的场景结合扣人心弦的故事,不仅有丰富视觉享受,同时也带来了一个心灵慰藉的港湾。但是卡通世界的诞生需要日积月累的积淀,在一笔笔线条和色彩的勾勒下才能生成动人的场景。
而人工智能却带来了便捷的可能,现实世界的景色人物都可以一键定格为卡通风格。在尽可能保留显示细节的同时也保持着艺术的风格化。
这次是将AnimeGAN部署到Ascend 310,从而实现对自己想要图片的一键转换为我们想看到的卡通风格。
参考实现: https://github.com/TachibanaYoshino/AnimeGAN
参考论文: https://link.springer.com/chapter/10.1007/978-981-15-5577-0_18
最终效果图如下图所示,左图是输入,右图是输出:

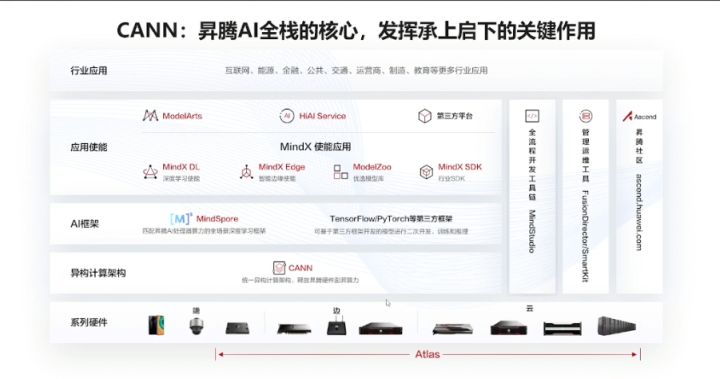
CANN介绍
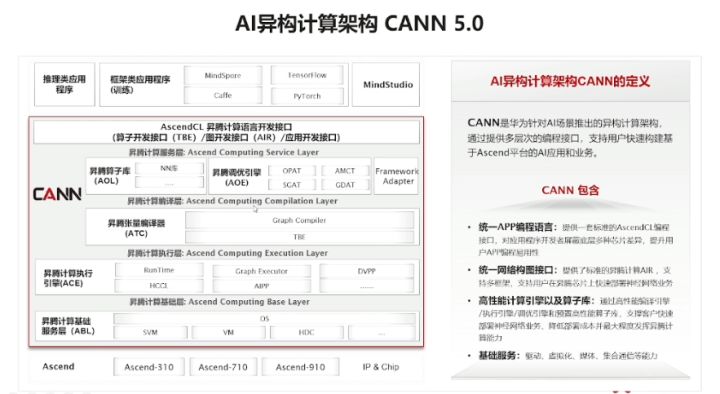
Ascend 310是硬件,我们是基于在硬件上构建的软件进行开发的,不会直接接触到底层的硬件,这里我们是基于CANN开发,CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。包括:
- AscendCL:昇腾硬件的统一编程接口,包含了编程模型、硬件资源抽象、AI任务及内核管理、内存管理、模型和算子调用、媒体预处理接口、加速库调用等一系列功能,充分释放昇腾系统多样化算力,使能开发者快速开发AI应用。
- TBE算子开发工具:预置丰富API接口,支持用户自定义算子开发和自动化调优,缩短工期,节省人力。
- 算子库:基于昇腾处理器,深度协同优化的高性能算子库
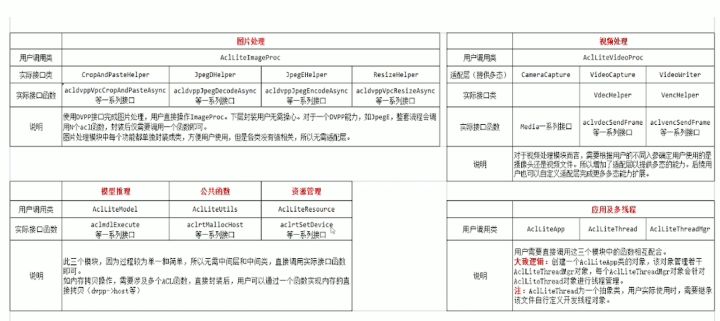
这里我们主要用到的还Ascend CL,也就是ACL,不过为了更加方便开发,减少对原生接口的数据对齐的琐碎限制,我们使用官方推出的进一步封装的acllite,相当于做了进一步封装,更加方便开发者使用。acllite的主要接口如下图所示:
具体的开发流程如下图所示,不仅适用于本应用,也适用于所有的开发应用。

AnimeGAN网络概述
AnimeGAN生成网络结构如下,以Generative Adversarial Networks(GAN)为基础,其架构包括一个生成器(Generator)用于将现实世界场景的照片转换为动漫图像,和一个判别器(Discriminator)区分图像是来自真实目标域还是来自生成器产生的输出,通过迭代训练两个网络(即生成器和判别器),由判别器提供的对抗性损失可以生成卡通化的结果。同时将生成器替换为自编码结构,使得生成器具有更强的生成能力。对于生成器,它希望生成样本尽可能符合真实样本的分布,而判别器则希望尽可能的区分真实样本与生成样本。具体来说,判别器将真实样本判断为正确,记为1;而将生成结果判断为错误,记为0。
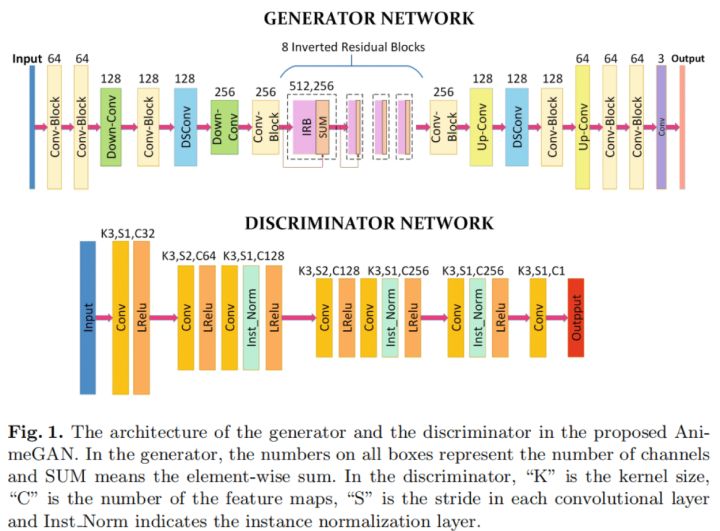
AnimeGAN 的生成器可以被认为是一个对称的编码器-解码器网络。主要由标准卷积、深度可分离卷积、反向残差块(IRB),上采样和下采样模块组成。 在生成器中,最后一个具有 1×1 卷积核的卷积层不使用归一化层,后面是 tanh 非线性激活函数。Conv-Block 由具有 3×3 卷积核的标准卷积、实例归一化层和 LRelu 激活函数组成。 DSConv 由具有 3 × 3 卷积核的深度可分离卷积、实例归一化层和 LRelu 激活函数组成。反转的残差块包含 Conv-Block、深度卷积、点卷积和实例归一化层。
为了避免最大池化导致的特征信息丢失,使用Down-Conv作为下采样模块来降低特征图的分辨率。它包含步长为 2 的 DSConv 模块和步长为 1 的 DSConv 模块。在 Down-Conv 中,特征图的大小被调整为输入特征图大小的一半。 Down-Conv 模块的输出是步长为 2 的 DSConv 模块和步长为 1 的 DSConv 模块的输出之和。使用Up-Conv 用作上采样模块以提高特征图的分辨率。
为了有效减少生成器的参数数量,网络中间使用了 8 个连续且相同的 IRB。与标准残差块 相比,IRB 可以显着减少网络的参数数量和计算工作量。生成器中使用的 IRB 包括具有 512 个内核的逐点卷积、具有 512 个内核的深度卷积和具有 256 个内核的逐点卷积。值得注意的是,最后一个卷积层没有使用激活函数。
为了辅助生成器生成更好的结果,判别器需要判断输出图像是否是真实的卡通图片。因为判断是否真实依赖于图片本身特征,不需要抽取最高层的图片特征信息,所以可以设计成较为浅层的框架。首先对输入进行卷积核为3 x 3的卷积,然后紧接两个步长为2的卷积块来降低分辨率,并且提取重要的特征信息。最后使用一个3 × 3的卷积层得到最终提取的特征,再与真实标签进行损失计算。如果输入为256 × 256,则输出为64 × 64的PatchGAN形式。这里将Leaky ReLU的参数设置为0.2。
开发过程介绍
在拿到一个模型,我们希望做开发部署的时候,基本流程如下图所示:

下面就来看看。
分析预处理代码
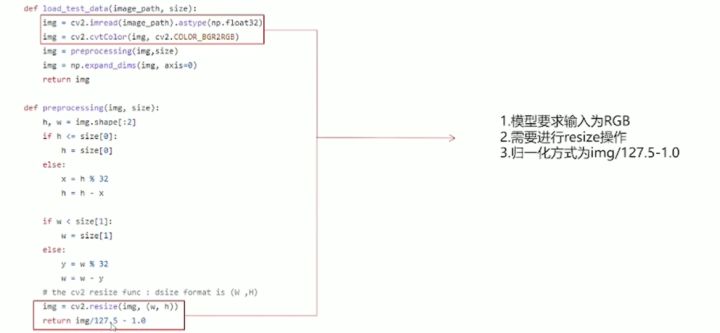
模型转换
获取到原始模型后,需要使用昇腾CANN所提供的ATC模型转换工具,将第三方框架的模型转换为昇腾推理芯片所支持的om模型。模型转换步骤可参考昇腾文档中开发者文档->应用开发->将已有模型通过ATC工具转换(命令行)的指导进行转换。该样例通过不同分辨率的模型支持三种不同的输入图片,直接影响到生成图片的质量。以下为模型转换过程。

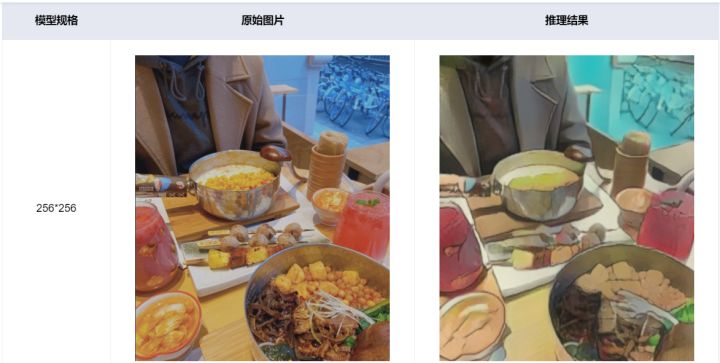
三种不同的模型输入分辨率,分辨率越高,图片质量越好,但模型推理时间也就越长,咱们用的是第一种256 * 256,如下图所示:

测试

预处理代码编写

如果你想用Python,也没问题,来看看Python版本的代码:
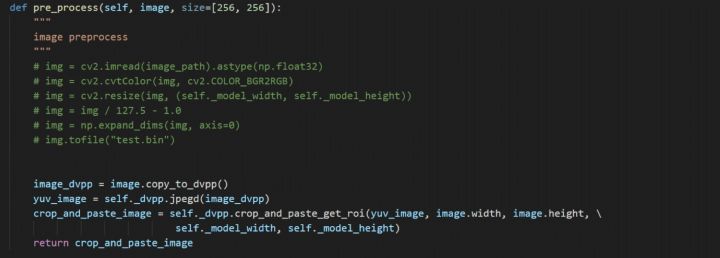
使用DVPP对读入图片进行解码,并缩放至256 × 256分辨率,以符合网络输入大小;在模型转换时,使用AIPP功能,将unit8的数据转换为fp16格式,将0~255的数值归一化到-1~1,将BGR的图片格式转换为RGB格式。
执行推理
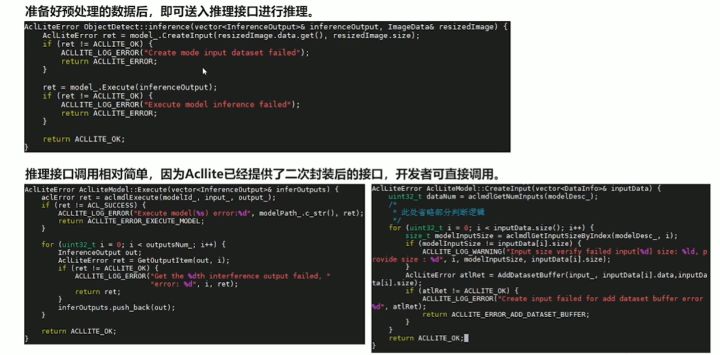
后处理
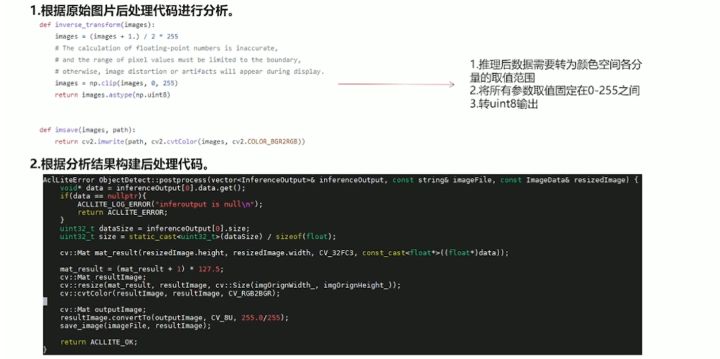
如果使用Python接口开发,代码如下所示:
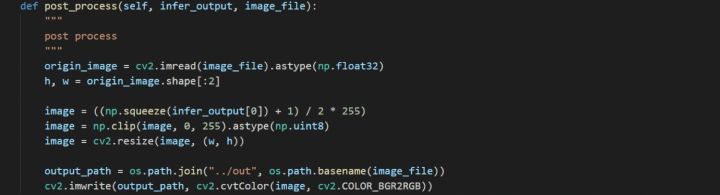
后处理模块主要是对模型的推理结果进行格式变换,然后将变换结果反馈给用户。主要过程是先将-1~1的值映射回0~255,然后将256 × 256的转换结果缩放回原始图像的尺寸大小。最后进行色域转换将RGB格式的输出转换为BGR格式。
结果展示

整理流程图如下图所示:

1.运行管理资源申请:用于初始化系统内部资源,固定的调用流程。
2.加载模型文件并构建输出内存:从文件加载离线模型AnimeGAN.om数据,需要由用户自行管理模型运行的内存,根据内存中加载的模型获取模型的基本信息包含模型输入、输出数据的数据buffer大小;由模型的基本信息构建模型输出内存,为接下来的模型推理做好准备。
3.数据预处理:对读入的图像数据进行预处理,然后构建模型的输入数据。
4.模型推理:根据构建好的模型输入数据进行模型推理。
5.解析推理结果:根据模型输出,解析模型的推理结果。使用OpenCV将转换后的卡通画数据转化为JPEG。
(可选)优化加速

结语
图片卡通化或者说动漫化,还是挺有意思的,算是AI一个娱乐性较强的应用了,可以让每个普通人随时随地创造自己想要的卡通化Demo,很有意思,如果你想体验的话,可以到昇腾开发者社区的在线体验,上传自己的图片转换,如果你想要代码,那也没问题,在线体验提供了原始代码,可以免费下载使用,奉上在线实验链接:昇腾社区-官网丨昇腾万里 让智能无所不及
最后奉上不同分辨率下的运行结果对比:


以上是关于教你使用CANN将照片一键转换成卡通风格的主要内容,如果未能解决你的问题,请参考以下文章
用 Python 制作可视化 GUI 界面,一键实现多种风格的照片处理