爬虫:JS逆向前置准备
Posted 阿呆攻防
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫:JS逆向前置准备相关的知识,希望对你有一定的参考价值。
爬虫:JS逆向前置准备
1. 简介
JS逆向是在爬虫或POC脚本访问请求时,链接请求需要携带动态生成的请求头参数,比如常见的csrf请求头,诸如此类的限制来实现反爬。
2. 逆向环境
- Node.js14.0以上版本
- 官网下载地址:https://nodejs.org/en/download/
- 教程:https://www.runoob.com/nodejs/nodejs-install-setup.html
- Chrome浏览器 / Firefox浏览器
- Chrome官网:https://www.google.cn/intl/zh-CN/chrome/
- Firefox官网:http://www.firefox.com.cn/
- VScode
- 官网下载地址:https://code.visualstudio.com
3. 以谷歌浏览器为例
我们对网页请求参数逆向时需要通过浏览器对其进行分析,需要对浏览器非常熟悉,先来介绍一下浏览器功能,了解过后就开始案例模拟。
1. 右键页面 -> 检查 | 按F12触发

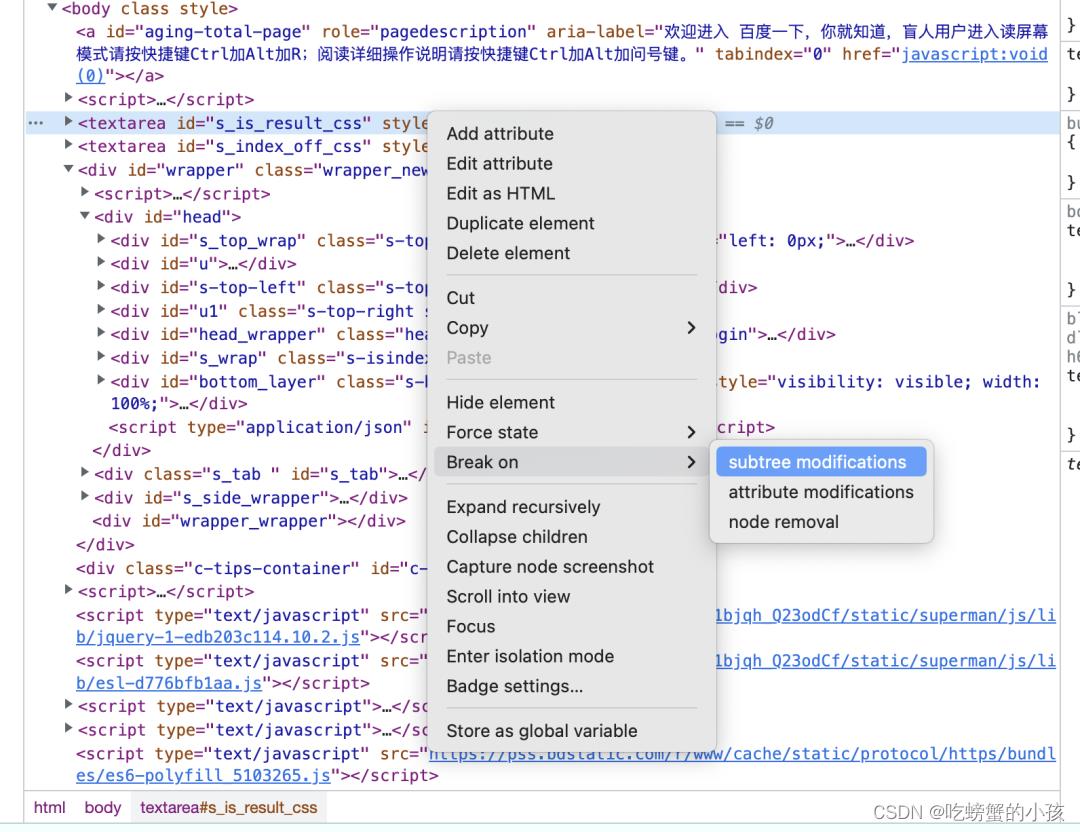
2. Element面板
*下元素断点:选择Break on->subtree modification
3. Console面板
勾选如下设置,此面板主要用于查看开发日志以及与JS交互。
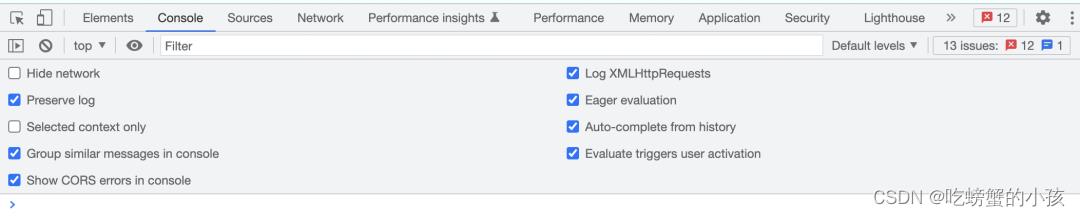
4. Sources面板
此处有3个模块在逆向过程常用,在以后教程会单独举例讲。
Page版块
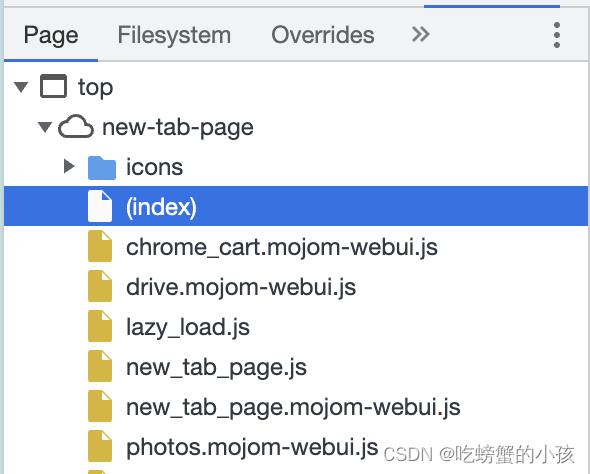
页面加载所加载的资源都在这里,具体内容可以点开后下断点。
Overrides板块
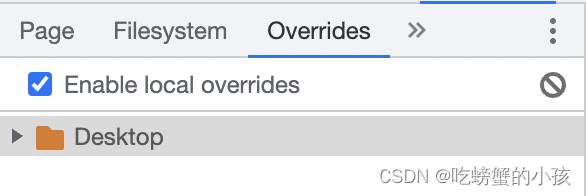
此板块用于项目重写,在Page页选择跳到Overrides的话就可以直接本地替换掉原有的文件。
Snippets板块
这个板块可以自写脚本,可以直接在浏览器本地运行抠下来的代码,点击➡️即可。
5. Network板块

可以看到网页加载时的请求链接,可以看到加密的参数这些情况,具体在后面会说到。
下节预告
直接从实战来了解过程这样学习是非常迅速的,下节我们将直接通过一个DEMO案例来了解如何设置断点,如何抠取代码,如何将代码在本地运行,并且通过python调用成功。
以上是关于爬虫:JS逆向前置准备的主要内容,如果未能解决你的问题,请参考以下文章