PyTorch随笔 - ConvMixer - Patches Are All You Need
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch随笔 - ConvMixer - Patches Are All You Need相关的知识,希望对你有一定的参考价值。
2022.1.24,ICLR 2022,Paper:Patches Are All You Need,即ConvMixer,卷积混合,在很多实验上,都取得很多效果。
Conv2d:

-
stride,窗口移动的步长,向左、向下
-
padding,填充,residual设置为same
-
dilation,膨胀、空洞,扩大范围的点,跳过一些点,选择一些点,增加感受野,不增加计算量
-
groups,解耦通道之间混合,降低计算,只混合部分通道,例如Depth-wise Convolution,再接一个Point-wise Convolution
Patches + Conv 代替 ViT,用patch代替像素点,Swin-Transformer效果最好
ViT:Transformer?Patch?
ViT + MLP-Mixer -> ConvMixer,以图像的patch作为输入,空间混合和通道混合分离
源码:https://github.com/locuslab/convmixer
网络结构:输入与输出一致,没有做下采样
- ConvMixer Layer写的非常Trick!
- Patch Embedding:nn.Conv2d(3, h, patch_size, stride=patch_size)
- Depthwise-Convolution:nn.Conv2d(h, h, kernel_size, groups=h, padding=“same”)
- Pointwise-Convolution:nn.Conv2d(h, h, 1)
- nn.Flatten(),向量展开
- nn.Linear(h, n_classes),FC层
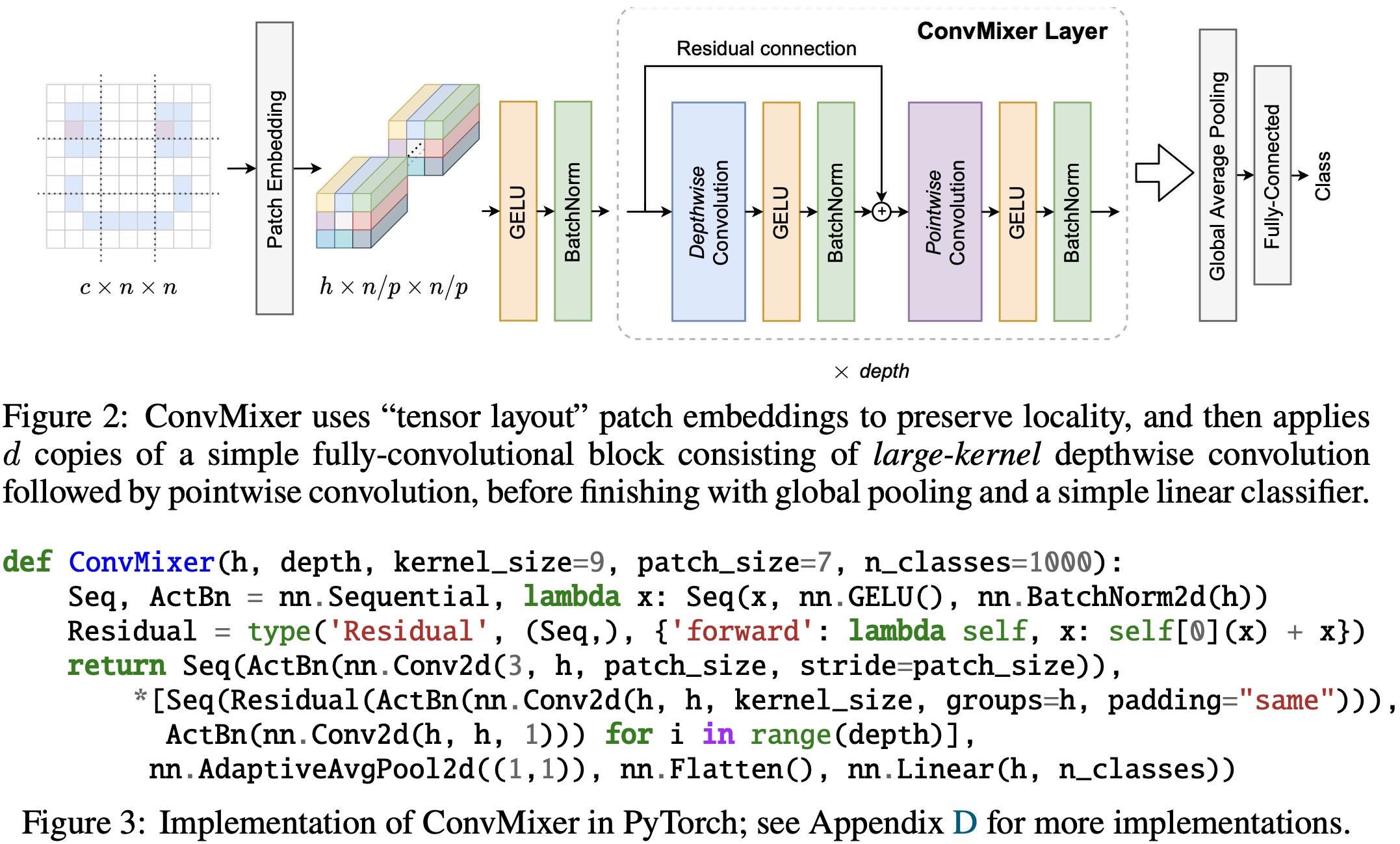
Patch Embeddings:通过kernel_size和stride都是p

GELU:Gaussian Error Linear Units,高斯错误线性单元,用于GPT-3,BERT
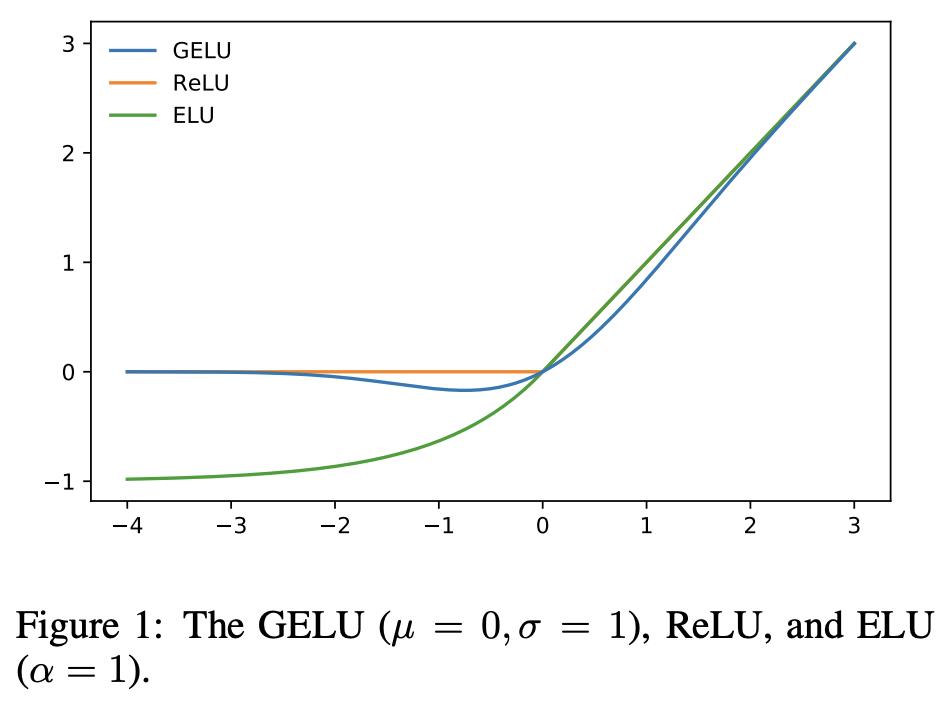
函数:

erf(x):error function,误差函数
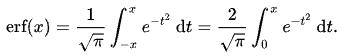
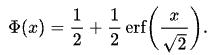
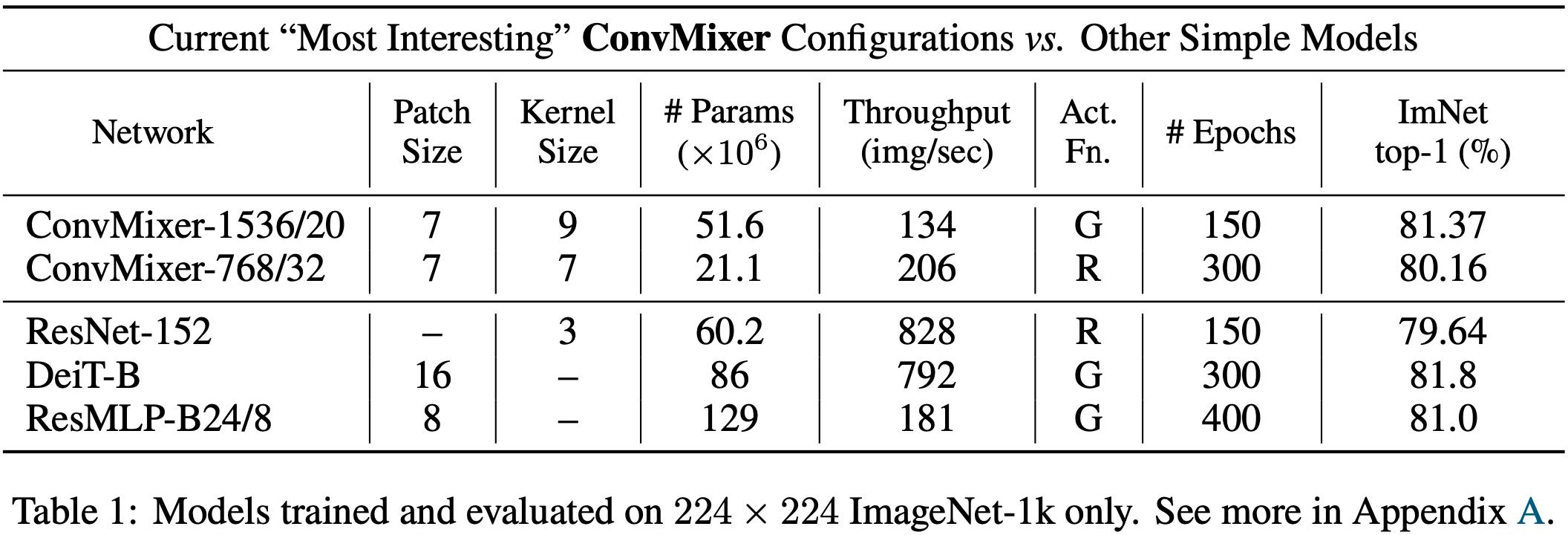
效果:We name ConvMixers after their hidden dimension and depth, like ConvMixer-h/d
- h是hidden dimension,即输出channel数,d是depth,即ConvMixer Layer的层数
conv2d对比depthwise+pointwise的参数量:
import torch
import torch.nn as nn
conv_general = nn.Conv2d(3, 3, 3, padding="same")
subconv_space_mixing = nn.Conv2d(3, 3, 3, groups=3, padding="same") # Depth-wise
subconv_channel_mixing = nn.Conv2d(3, 3, 1) # Point-wise
for p in conv_general.parameters():
print(p.size(), torch.numel(p)) # weight 3x3x[3x3] = 81, bias = 3
for p in subconv_space_mixing.parameters():
print(p.size(), torch.numel(p)) # weight 3x1x[3x3] = 27, bias = 3
for p in subconv_channel_mixing.parameters():
print(p.size(), torch.numel(p)) # weight 3x3x[1x1] = 9, bias = 3
# 84 -> 27+3+9+3 = 42,参数量降低一半
以上是关于PyTorch随笔 - ConvMixer - Patches Are All You Need的主要内容,如果未能解决你的问题,请参考以下文章