国际顶会OSDI首度收录淘宝系统论文,端云协同智能获大会主旨演讲推荐
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了国际顶会OSDI首度收录淘宝系统论文,端云协同智能获大会主旨演讲推荐相关的知识,希望对你有一定的参考价值。

大淘宝技术团队论文入选计算机系统领域顶级国际学术会议OSDI,这是淘宝系统论文首次入选该国际顶会,论文详解了阿里历经四年、自主研发的首个端到端、通用型、规模化产业应用的端云协同机器学习系统“瓦力”——Walle。OSDI特别邀请到的David Tennenhouse在大会主旨演讲中专门推荐了Walle系统,对其技术先进性和应用落地效果赞誉有加。目前,Walle 作为阿里机器学习的基础设施支持 30+APP上 的300+个算法任务。
OSDI 会议
USENIX OSDI(Operating Systems Design and Implementation)是计算机系统领域最顶级的国际学术会议之一,被誉为操作系统领域的奥斯卡,拥有极高的学术地位和影响力,汇集了全球学术界和产业界系统领域专业人士的前沿思考和突破性成果。
今年OSDI大会特别邀请了David Tennenhouse作主旨演讲,他是IEEE Fellow,曾担任Intel、Amazon/A9.com、Microsoft、VMware等公司研究院和DARPA的首席/主管,也曾任教于MIT。David Tennenhouse在主旨演讲「1」中专门推荐了Walle系统,并在Walle talk的前后通过邮件和Slack等方式主动与作者们进行了交流。

Walle 系统命名由来
Walle(瓦力)来源于2008年电影“机器人总动员 WALL-E「2」”。在电影中,WALL-E 机器人负责对地球垃圾进行清理,变废为宝。Walle的架构者也秉持类似的初衷,希望所设计和搭建的端云协同机器学习系统能够像 WALL-E 机器人一样,有效利用数以十亿计移动端设备上的用户数据,充分释放其被忽视的价值,为用户提供更好的智能服务。
Walle 系统设计哲学
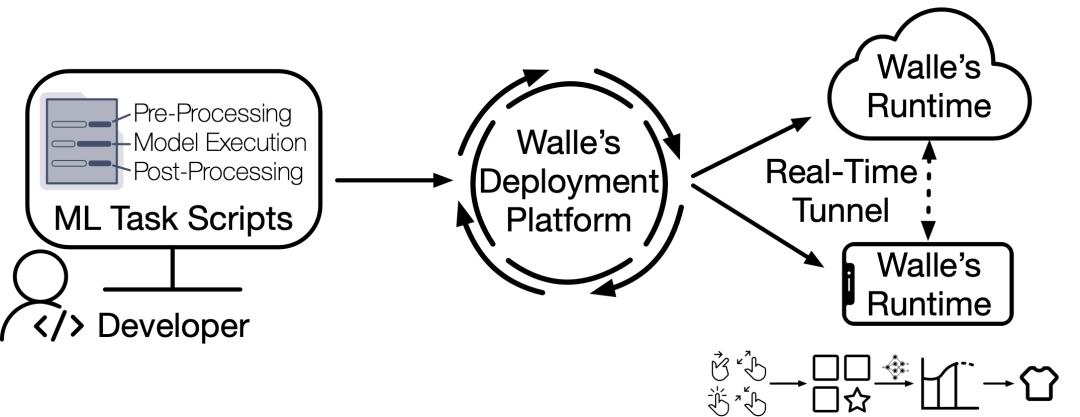
图1: 机器学习任务开发者视角中的Walle工作流程
为了打破主流基于云服务器的机器学习框架延时高、开销成本大、服务器负载高、隐私安全风险高等瓶颈,Walle采用了端云协同机器学习新范式,以充分发挥移动端设备贴近用户和数据的天然优势,实现端云优势互补。不同于端云协同学习已有工作(主要在算法层面,并针对特定应用场景中特定的机器学习推理或训练任务),Walle是首个端到端、通用型、规模化产业应用的端云协同机器学习系统。Walle支持机器学习任务在任意阶段(前处理、模型训练与推理、后处理)在端和云之间交换任意必要的信息(例如数据、特征、样本、模型、模型更新、中间结果等)协同完成任务。Walle遵循端到端的架构设计,面向机器学习任务,从开发者视角出发,覆盖了机器学习任务的研发期、部署期和运行时,并支持端侧和云侧运行时的每个阶段。此外,Walle还遵循通用型的系统设计,而非集成大量面向特定应用、特定平台的定制方案。Walle向下磨平了端云设备软硬件的差异性并保证移动APP的轻量化,向上则支撑了多种类型机器学习任务的大规模产业化应用。
Walle 系统架构
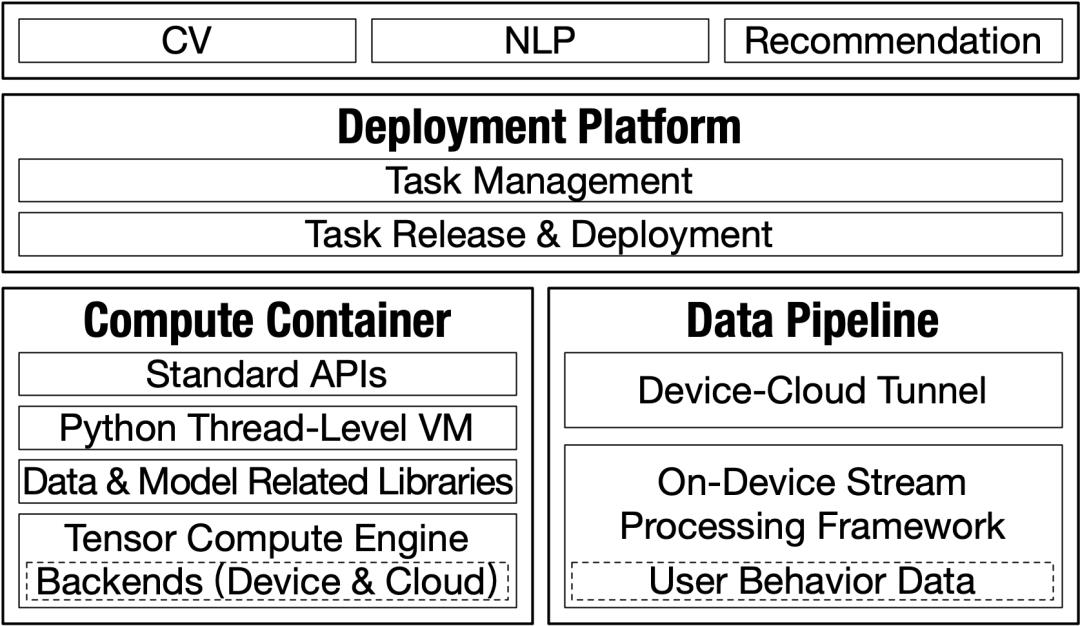
图2: Walle 的整体架构
Walle 主要包含以下三个核心系统模块:
部署平台,管理大规模的机器学习任务并及时部署到亿级设备上;
数据管道,主要涉及机器学习任务的前处理阶段,为端侧和云侧提供任务输入;
计算容器,提供跨平台、高性能的机器学习任务执行环境,同时满足机器学习任务天级迭代的实际需求。
具体来说,
计算容器底层是 MNN 深度学习框架,包含高性能的张量计算引擎和标准数据处理与模型运行库,并通过改造的 Python 线程级虚拟机对外统一透出接口,以支持多种机器学习任务的全链路执行和多任务的并行。MNN 的核心技术创新点是几何计算和半自动搜索这两个新机制,其中几何计算主要通过形变算子的拆解,极大地降低了为十多种硬件后端手工优化上百个算子的工作量,而半自动搜索机制则进一步实现了在运行时快速搜索计算图的最优可用后端和执行方案。Python 线程级虚拟机则舍弃了 Global Interpreter Lock(GIL)并首次支持了多任务多线程的并行,进一步面向移动APP的实际业务需求,通过裁剪与改造首次移植到端上;
数据管道引入了全新的端侧流处理框架,遵循“单台资源受限移动端设备上针对无限数据流的有状态计算”这一基本原则,使得用户行为数据在近数据源处能够被高效处理,同时设计了基于字典树的任务触发管理机制,实现了端侧多个相关流处理任务的批量触发执行。另外,在端云之间搭建了实时传输通道,以支持数据百毫秒级的上传下达;
部署平台通过git机制实现细粒度的任务管理,并采用推拉结合、多批次任务发布的方式保证实效性和稳定性,同时支持统一和定制化的多粒度任务部署策略。
典型实际应用中的系统性能
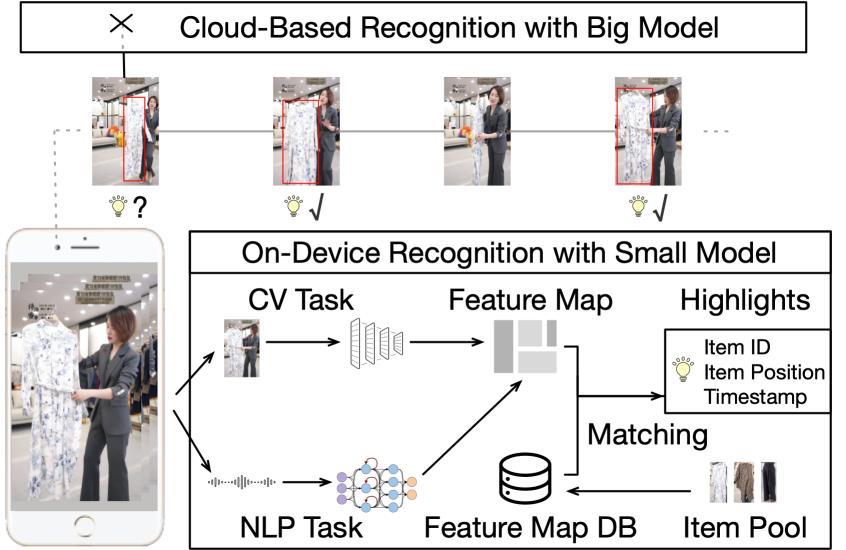
图3: 电商直播场景下端云协同看点识别流程
在淘宝直播场景中,智能看点任务是指通过机器学习方法自动地定位出主播介绍讲解商品看点(即商品对买家有吸引力的信息)的时间点,从而提升用户体验。相比较于以前的纯云智能看点任务链路,引入Walle后的新端云协同链路,将平均生产每看点的云侧负载降低了 87%,将智能看点覆盖的主播数量提升了123%,并将单位云算力产出的看点量提升了 74%。真机测试显示,在华为 P50 Pro上平均每次看点任务的总耗时为130.97 ms,而在 iPhone 11 上的耗时为90.42 ms。上述结果凸显了及端云协同学习框架的实用性以及Walle计算容器的高性能。
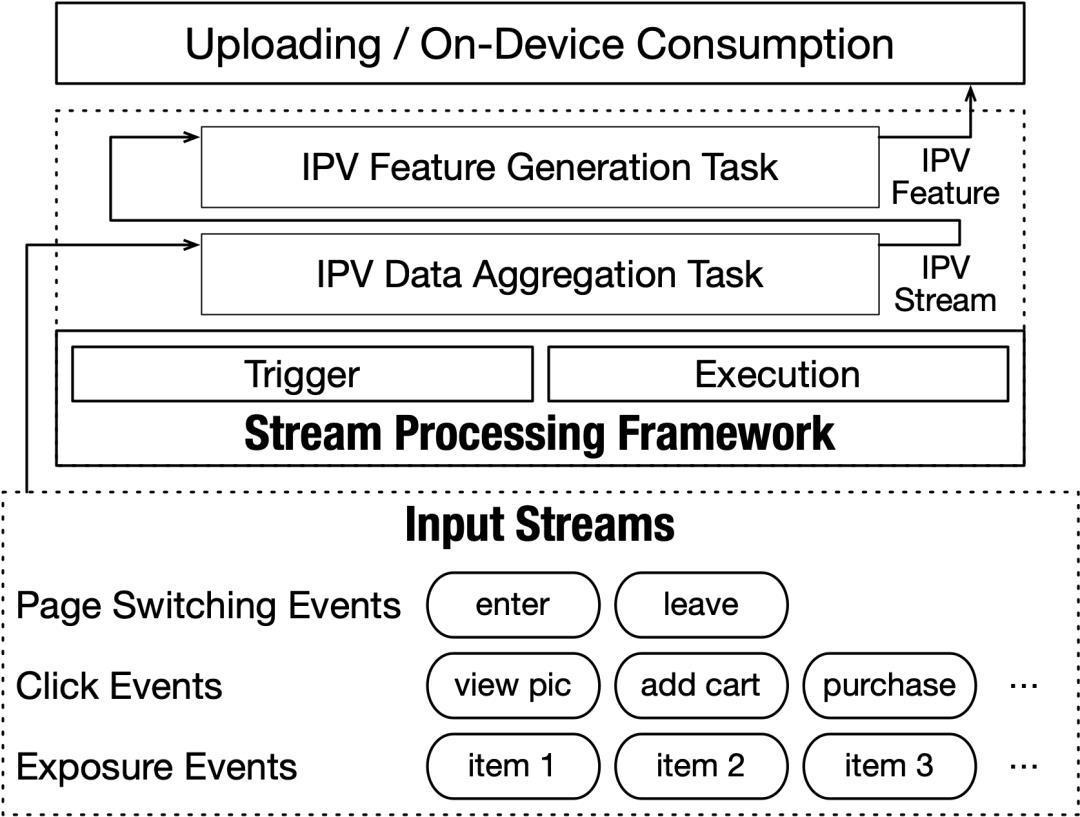
图4: 电商推荐场景下基于Walle数据管道的IPV特征生产流程
在电商推荐场景中,商品页面浏览(Item Page-View, IPV)特征主要记录了用户在某个特定商品的详情页上的行为(例如收藏、加购物车、购买下单等),该特征对于推荐模型起着十分重要的作用。云侧原有的 IPV 特征生产链路,产出一条特征的平均延迟为33.73 秒,同时消耗了大量的计算、通信、存储资源,并存在0.7%的错误率。相比之下,Walle全新的数据管道可以在端侧完成IPV特征生产过程,平均端侧延迟仅为44.16毫秒,同时削减了超过90%的数据量,并保证了特征的正确性。这些结果表明:相较于主流基于云的数据管道,Walle新数据管道大幅提升了特征生产和消费的时效性、高效性和正确性。
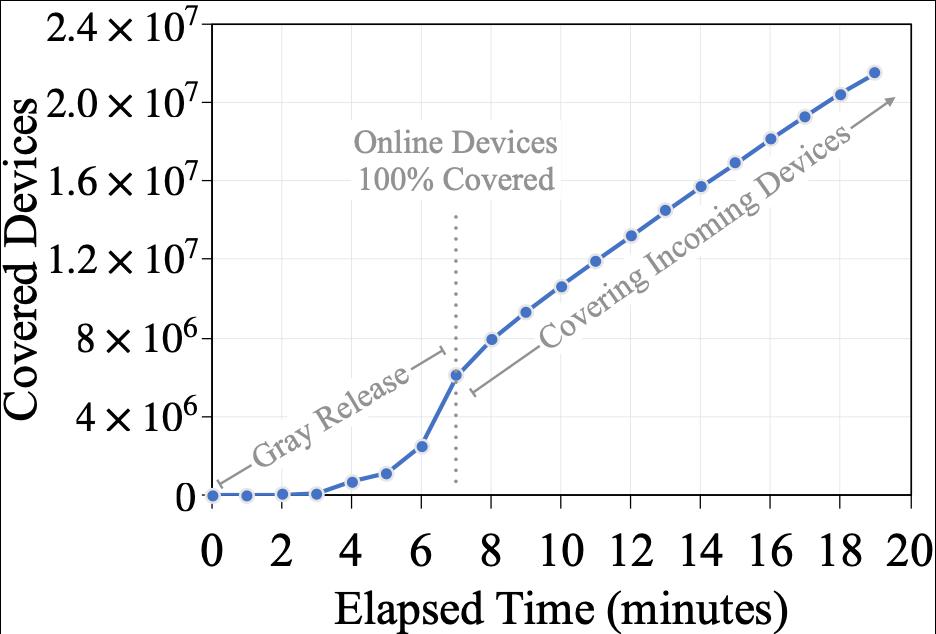
图5: 某个线上随机挑选的机器学习任务的部署过程
为了测试Walle部署平台的时效性和规模化,随机挑选了一个线上的机器学习任务,并监控了其部署到目标设备群体的整个流程。在保证任务稳定性的前提下,Walle部署平台成功覆盖在线的700万移动端设备需要7分钟,而覆盖所有的2200万设备需要22分钟。
核心模块的Benchmark测试结果
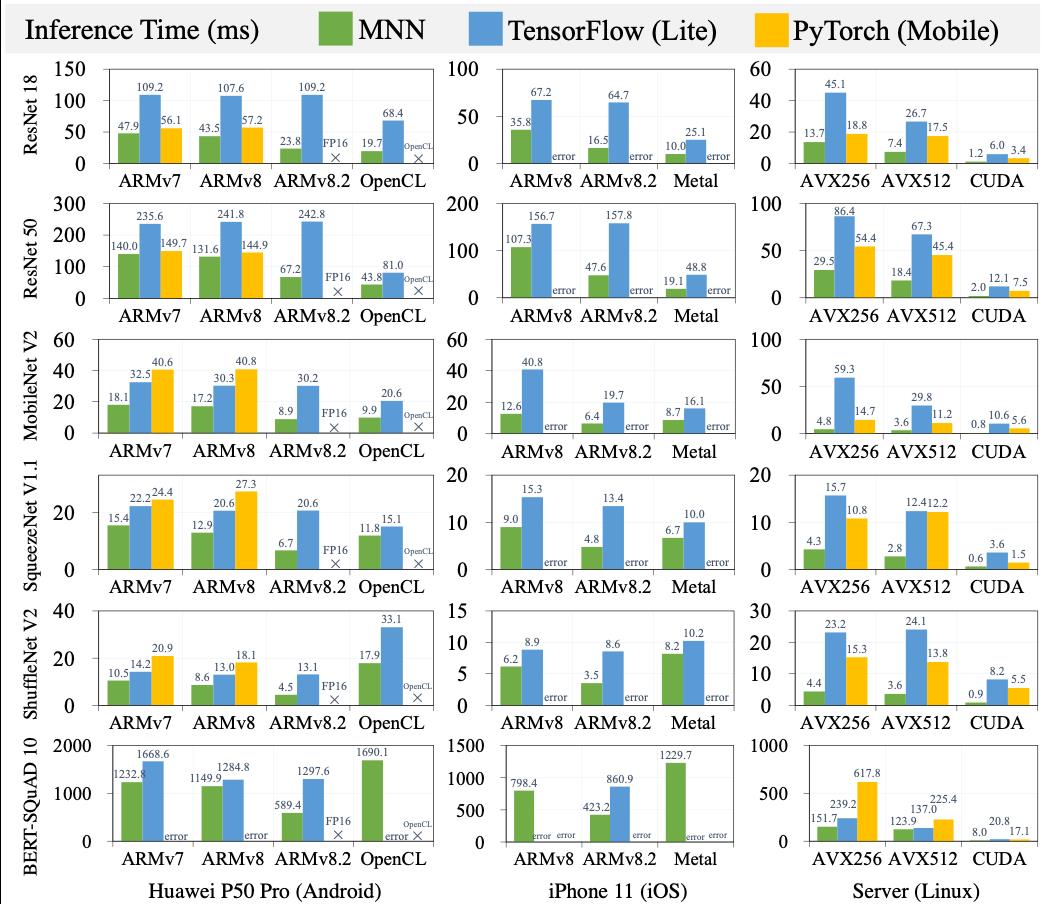
图6: MNN vs. TensorFlow (Lite), PyTorch (Mobile)
在android和ios移动端设备以及Linux服务器的主流硬件后端上对MNN与TensorFlow (Lite)和PyTorch (Mobile)进行了对比测试。测试采用了视觉、自然语言理解、推荐领域中常用的7个模型。结果表明:MNN几乎在所有测试样例中的性能都超过其他的深度学习框架。除了高性能之外,MNN还能够支持所有移动端硬件后端上每个模型的运行,而TensorFlow Lite和PyTorch Mobile则无法支持某些硬件后端或模型,因此MNN的通用性更好。
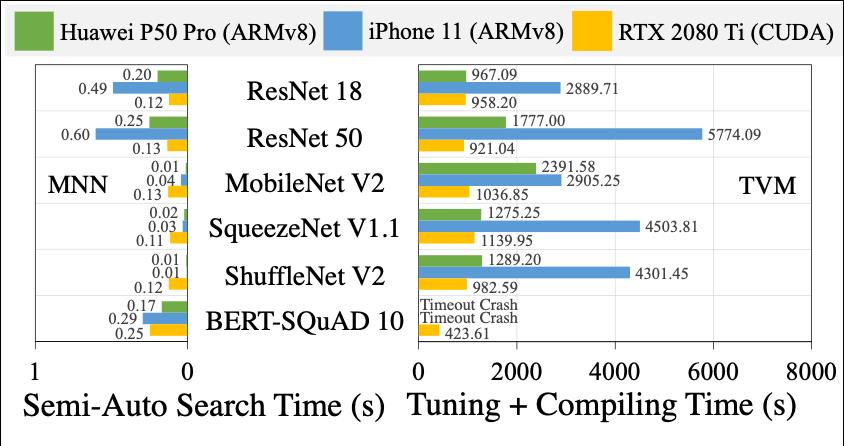
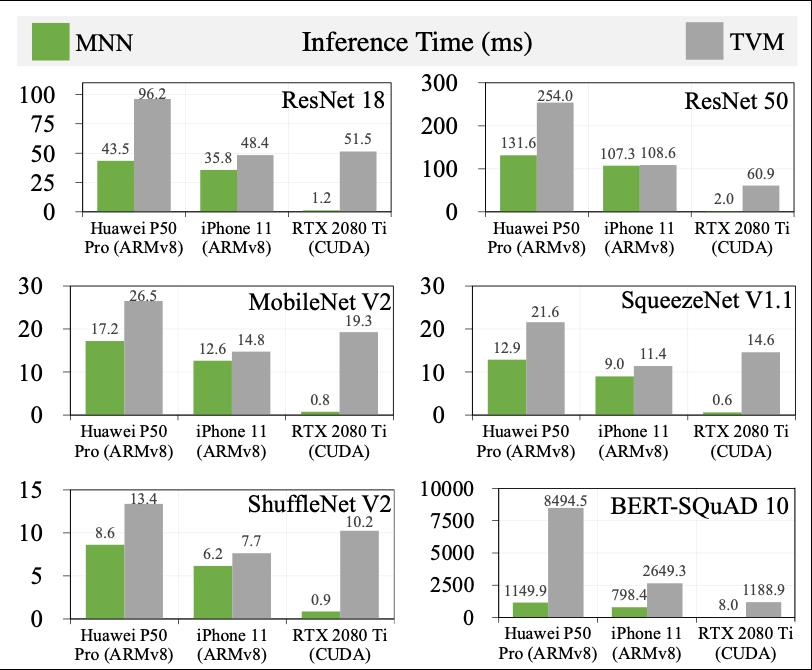
图7: MNN vs. TVM
此外还进行了MNN和TVM的对比测试,其中TVM自动调优和编译的主机是MacBook Pro 2019和NVIDIA GeForce RTX 2080 Ti。一方面,TVM的自动调优和编译大约耗时几千秒,而MNN在运行时的半自动搜索仅需要几百毫秒。进一步结合MNN和TVM在设计和实际部署上的区别(尤其是TVM在iOS设备上模型动态部署能力欠缺,详见PPT和论文),可以得出:MNN能够支持涉及大规模异构硬件后端并需要任务频繁快速迭代的产业界场景,而TVM则不可行。另一方面,在每个硬件后端上每个模型的推理时间方面,MNN也低于TVM,尤其是在GPU服务器上,这主要由于MNN中手工算子优化。
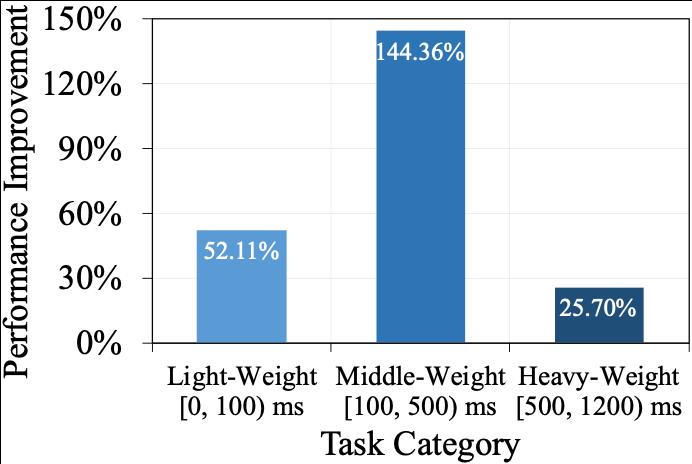
图8:Python线程级虚拟机 vs. CPython(基于线上3000万次机器学习任务执行的统计分析)
最后还对Python线程级虚拟机和CPython进行了性能对比测试。结果表明:在涉及不同计算量的3种任务类型上,Python线程级虚拟机性能大幅提升,主要原因在于解除了GIL并支持任务级的多线程并发。
业务落地情况
目前,Walle 作为阿里巴巴集团机器学习的基础设施,每天被调用超过千亿次,支持着 30 多个移动 APP(包括手机淘宝、饿了么、速卖通、菜鸟裹裹等)上 300 多个视觉、推荐等任务。此外,MNN「3」已在GitHub开源,目前获得 6.8k stars和 1.4k forks,同时入选了 2021 年“科创中国”开源创新榜单,并已在 10 多个其他公司商业化应用。
论文作者及引用信息
Chengfei Lv, Chaoyue Niu, Renjie Gu, Xiaotang Jiang, Zhaode Wang, Bin Liu, Ziqi Wu, Qiulin Yao, Congyu Huang, Panos Huang, Tao Huang, Hui Shu, Jinde Song, Bin zou, Peng Lan, Guohuan Xu, Fei Wu, Shaojie Tang, Fan Wu, and Guihai Chen, Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning, in Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Pages 249-265, Carlsbad, CA, USA, Jul. 11 - 13, 2022. https://www.usenix.org/conference/osdi22/presentation/lv
论文相关资料

「1」主旨演讲:
https://www.usenix.org/conference/atc22/presentation/mon-keynote
「2」WALL-E:
https://movie.douban.com/subject/2131459/
「3」MNN:
https://github.com/alibaba/MNN
团队介绍
大淘宝技术Meta团队,目前负责面向消费场景的3D/XR基础技术建设和创新应用探索,创造以手机及XR 新设备为载体的消费购物新体验。团队在端智能、端云协同、商品三维重建、3D引擎、XR引擎等方面有着深厚的技术积累,先后发布深度学习引擎MNN、端侧实时视觉算法库PixelAI、商品三维重建工具Object Drawer、端云协同系统Walle等。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。欢迎视觉算法、3D/XR引擎、深度学习引擎研发、终端研发等领域的优秀人才加入,共同走进3D数字新时代。简历请投递至: chengfei.lcf@alibaba-inc.com
✿ 拓展阅读

编辑|橙子君
以上是关于国际顶会OSDI首度收录淘宝系统论文,端云协同智能获大会主旨演讲推荐的主要内容,如果未能解决你的问题,请参考以下文章
重磅干货免费下载!阿里云RDS团队论文被数据库顶会SIGMOD 2018收录
蚂蚁安全实验室10篇论文被CCF-A类顶会收录,探索从算法角度实现AI可信
(ACL+ICML)2020推荐系统相关论文聚焦(附下载链接)