浅谈云原生数据库:回顾过去,未来可期
Posted 小虚竹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈云原生数据库:回顾过去,未来可期相关的知识,希望对你有一定的参考价值。
一、传统数据库和云原生数据库的技术解析
1、传统数据库
1.1、传统数据库的发展
传统的数据库系统是基于计算和存储还有通信,三个要素组成的经典计算机架构。
我们来简要看看传统数据库产业变迁:
-
上个世纪50,60年,随着美国登月工程等大型项目而生的数据库,从军用场景进入民用领域。
-
1961年,美国通用公司研发的第一个数据库系统DBMS诞生。
-
1978年,Oracle1.0诞生了,这个看起来只不过是个数据库玩具的产物,当时除了完成简单关系查询不能做任何事情。在甲骨文成立之后的30年里,传统数据库市场蓬勃发展,但传统数据库是封闭技术,只掌握在少数巨头手中,所以价格昂贵。
-
2000年,互联网兴起,开源数据库软件开始勃然发展,mysql、PostgreSQL等开源数据库满足了企业对于海量数据,高并发处理的需求。
1.2、传统数据库的局限
硬件成本高,扩展难
自建机房或自建数据中心如果为了适应业务突然暴涨而引发的流量增长,采购了一批硬件设备,当业务有所调整时,流量回归原来的水平,会造成资源的浪费。
采购新的硬件设备进行扩展时,采购硬件设备,机房拖管,搭建部署,这个周期会比较长,无法快速适应业务的发展变化。
线上机器环境故障维护难
自建机房或自建数据中心出现服务器故障,会引发服务器上搭建的数据库无法使用,会影响业务的正常使用,迁移数据库或者处理服务器故障,是需要大量花费时间和精力的。
迁移成本高
有些行业对数据库的高可用性要求很高,例如金融行业,迁移数据库时,不能影响正常使用。且数据库的数据量大,数据的安全性也有要求,迁移的难度和成本是很高昂的。
生产数据安全性维护难
生产数据的安全是第一重要的,除了制定合理的备份机制;还要保证数据库的安全防护,防止被入侵攻击;还有修复数据库的安全漏洞等事项,这些对DBA的专业性要求是挺高的,一些中小公司不一定会有专门的DBA岗位来处理这些。这样对生产数据的安全性是有很大风险的。
2、云原生数据库
2.1、什么是云原生数据库
说到云原生数据库,先要谈谈什么是云原生,云原生可拆分为云和原生两部分:
-
云:云服务器
-
原生:应用程序从设计之初即考虑到云的环境,原生为云而设计,架构为云设计
-
云原生指的并不是某个技术,它更像是一个技术体系
-
云原生的优势:弹性伸缩,动态调整,最优化资源利用率
云原生数据库吸收了云原生的优势,刚好解决了传统数据库的问题:扩容方式的繁琐和不便,业务高峰过后的缩容也是很痛苦的,造成了资源的浪费。很难应对业务发展的快速变化。
2.2、云原生数据库的优点
2.2.1、高扩展性
云原生分布式数据库与底层的云计算基础设施分离,所以能够灵活及时调动资源进行扩容缩容,以从容应对流量激增带来的压力,以及流量低谷期因资源过剩造成的浪费。生态兼容的特点,也让云原生数据库具备很强的可迁移性。
2.2.2、易用性
云原生分布式数据库非常易于使用,它的计算节点在云端部署,可以随时随地从多前端访问。因其集群部署在云上,通过自动化的容灾与高可用能力,单点失败对服务的影响非常小。当需要升级或更换服务时,还可以对节点进行不中断服务的轮转升级。
2.2.3、快速迭代
云原生分布式数据库中的各项服务之间相互独立,个别服务的更新不会对其他部分产生影响。此外,云原生的研发测试和运维工具高度自动化,也就可以实现更加敏捷的更新与迭代。
2.2.4、节约成本
建立数据中心是一项独立而完备的工程,需要大量的硬件投资以及管理和维护数据中心的专业运维人员。此外,持续运维会造成很大的财务压力。云原生分布式数据库以较低的前期成本,获得一个可扩展的数据库,实现更优化的资源分配。
3、云原生数据库技术解析
介绍目前两种云原生数据库主流的技术路线
3.1、主流的技术路线一:Spanner
以 Google 的 Spanner 为代表,基于云原生开发全新的数据库。受其影响,产生了CockrochDB、TiDB、YugabyteDB 等产品。
3.1.1、架构
以TiDB为例:
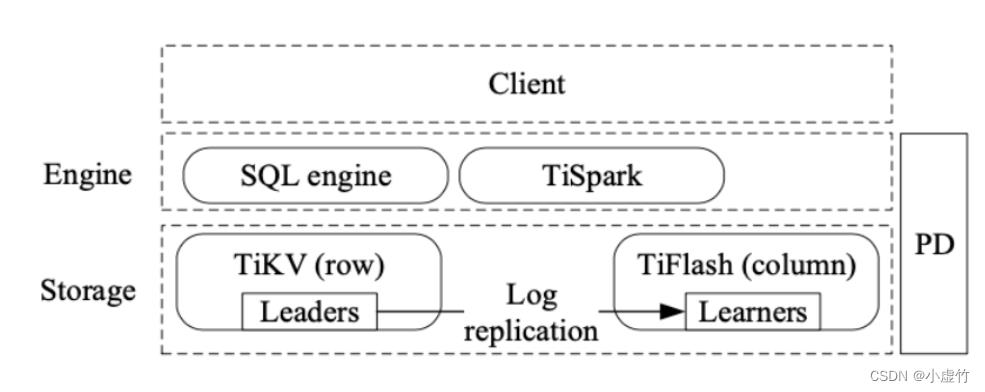
总体来说,此类产品其特点都是在 key-value 存储基础上包装一层分布式 SQL 执行引擎,使用 2PC 提交或者其变种方案实现事务处理能力。计算节点是 SQL 执行引擎,可以彻底实现无状态,本质是一个分布式数据库。
3.1.2、存储高可用性
Spanner 将表拆分为 tablet,以 tablet 为单位使用多副本 + Paxos 算法 实现。
TiDB 为 Region 为单位使用多副本 + Multi-Raft 算法,而 CockroachDB 则采用 Range 为单位进行多副本,共识算法也是使用 Raft。
Spanner 中 key-value 持久化方案,逻辑上仍然是基于日志复制的状态机模型(log-replicated state machines)上再加共识算法实现。
3.1.3、优缺点
优点:
-
彻底的 Share-Nothing
-
号称全球部署
-
使用 key-value 结构与 LSM 树,以及日志复制自动机机制,天然无写放大效应
-
不需要人为分库分表,有很好的横向扩展能力
缺点:
-
全新开发工作量大,技术不算成熟
-
性能不佳
-
事务处理能力有限
-
在内存中处理事务冲突,有冲突的需要读写等待或者提交等待。
-
如:Spanner 对有冲突的事务 TPS 能力最大只有 125
-
-
SQL 支持能力有限
-
如:YugabyteDB 不支持 Join 语句
-
3.2、主流的技术路线二:Aurora
Aurora 是亚马逊推出的云原生数据库。与 Google 的技术路线不同,Aurora 是传统的 MySQL(PostgreSQL)等数据库进行计算与存储分离改造,进而实现云原生的需求,但其本质仍然是单体数据库的读写分离集群。
Aurora 论文对 Spanner 的事务处理能力并不满意,认为它是为 Google 重读(read-heavy)负载定制的数据库系统[1] 。这种方案得到一些数据库厂商的认同,出现了微软 Socrates、阿里PolarDB、腾讯 CynosDB、极数云舟 ArkDB 以及华为 TarusDB 云原生数据库等。
3.2.1、架构
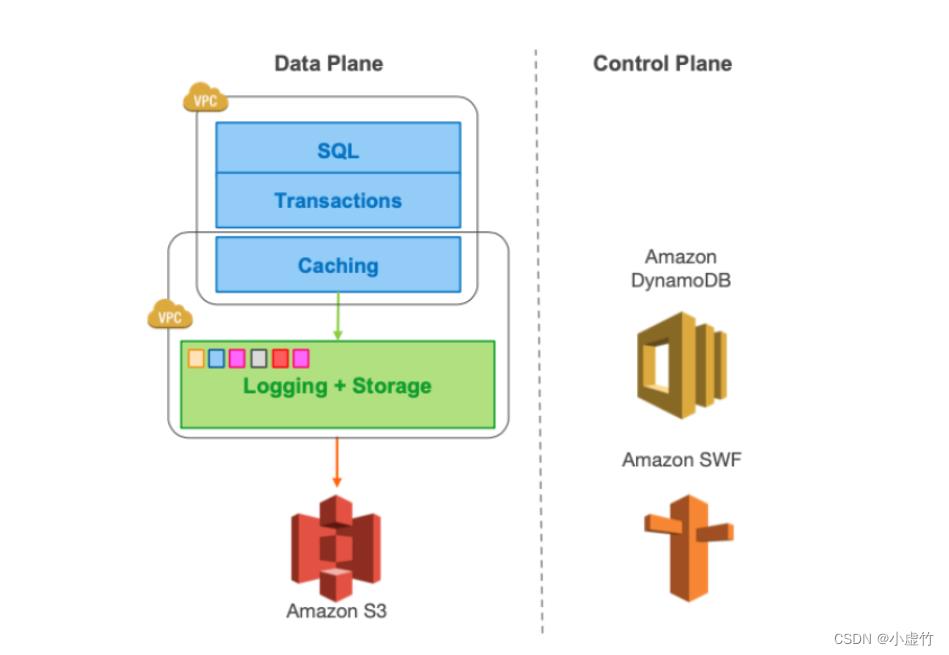
由于传统数据库持久化最小单位是一个物理页,哪怕修改一行,持久化仍然是一个页,加上需要写 redo 日志与 undo 记录,本身就存在一定的写放大问题。如果机械的将文件系统替换成使用分布式文件系统,并且为了实现高可用采用多副本,则写放大效应进一步放大,导致存储网络成为瓶颈而性能无法接受。
Aurora 继承了 Spanner 的日志持久化的思想,甚至激进提出“日志即数据库”的口号,其核心思想是存储网络尽量传输日志流,对于读操作,存储网络传输数据页在所难免,但是计算节点可以通过 buffer pool 来优化。
它对传统数据库进行了如下改造:
-
数据库主实例变成计算节点,数据库主实例不再进行刷脏页动作,仅仅向存储写日志,存储应用日志实现持久化,即日志应用下沉到存储。数据库主实例没有后台写动作,没有 cache 强制刷脏替换,没有检查点;
-
数据库复制实例获取日志内容,通过日志应用更新自身的 buffer/cache 等内存对象;
-
主实例与复制实例共享存储;
-
将崩溃恢复,备份、恢复、快照功能下放到存储层。
3.2.2、高可用
Aurora 采用仲裁协议(Quorum)多数派投票方式来检测故障节点。这种高可用的前提是,10G 分段恢复时间为 10 秒,而 10 秒内出现第二个节点故障的可能性几乎为 0。
它采用 3 个可用区,可以形成 4/6 仲裁协议(6 个节点,写需 4 个投票,读需 3 个投票)。最坏情况是某个可用区出现灾害(地震,水灾,恐怖袭击等)时,同时随机出现一个节点故障,此时仍然有 3 个副本,可以使用 2/3 仲裁协议(3 个节点,写需 2 个投票,读需 2 个投票)继续保持高可用性(AZ+1 高可用)。
3.2.3、优缺点
优点:
-
在成熟的数据库系统进行改造,技术相对成熟稳定、工作量小
-
事务处理能力,性能能保持传统数据库的优势
缺点:
-
本质仍然是改良的读写分离集群
-
有修改一行写一个页的写放大问题,需要小心处理
-
需要 proxy 等组件才能支持分布式事务
二、业务迁移Amazon RDS
1、为什么选择Amazon RDS for MySQL
1.1、易于使用的托管部署
只需在 AWS 管理控制台中单击几下,即可在几分钟内启动并连接到一个可以立即投入生产的 MySQL 数据库。Amazon RDS for MySQL 数据库实例针对您选择的服务器类型预配置了各种参数和设置。数据库参数组可以提供对 MySQL 数据库的精细控制和微调功能。
1.2、快速、可预测的存储
Amazon RDS 为您的 MySQL 数据库提供了两种由 SSD 支持的存储选项。通用型存储可以为小型或中型工作负载提供经济实惠的存储。对于高性能 OLTP 应用程序,预配置 IOPS 能够实现每秒高达 40000 次 IO 的稳定性能。随着存储需求的增长,您可以实时预配置额外的存储,绝无停机时间。
1.3、备份和恢复
借助 Amazon RDS 的自动备份功能,您可以将 MySQL 数据库实例恢复到长达 35 天的指定保留期内的任一时间点。除此之外,您还可以执行用户发起的数据库实例备份。Amazon RDS 会存储完整的数据库备份,直到您明确将其删除为止。
1.4、高可用性和只读副本
Amazon RDS 多可用区部署可以让 MySQL 数据库实现更强的可用性和持久性,使其成为生产型数据库工作负载的理想之选。Amazon RDS 只读副本可以轻松实现弹性扩展,超越单个数据库实例的容量限制,满足读取密集型数据库工作负载的需求。
1.5、监控和指标
Amazon RDS 针对数据库实例免费提供 Amazon CloudWatch 指标,而 Amazon RDS 的增强监控功能让用户可以查看 50 多项 CPU、内存、文件系统和磁盘 I/O 指标。您可以在 AWS 管理控制台中查看各种关键操作指标,包括计算/内存/存储容量使用率、I/O 活动和实例连接。
1.6、隔离和安全
作为一种托管服务,Amazon RDS 可以为 MySQL 数据库提供高级别的安全性,其中包括使用 Amazon Virtual Private Cloud (VPC) 进行网络隔离,使用您通过 AWS Key Management Service (KMS) 创建和控制的密钥来加密静态数据,以及使用 SSL 来加密传输中的数据。
2、案例
我有一个朋友小五,他公司之前有这么一个业务需求:
每年一些特定的节日,网站流量都会立即出现至少 200% 的增长。我们希望能够针对峰值负载实现自动扩展,而不必每次都花费大量时间和金钱来获取和预置新服务器。
团队希望将更多资源投入到新软件开发工作中。集中更多精力打造卓越产品,减少管理后端 IT 环境方面的工作。
后面处理的方案简单跟大家分享下:
先将 100 多个 MySQL 实例迁移到了 Amazon Elastic Compute Cloud (Amazon EC2)。大约一年后,该公司关闭了以前用来托管的数据中心,并将工作重点转移到优化其在 AWS 上的应用程序方面。此次优化过程中,团队将 MySQL 实例从 Amazon EC2 迁移到了 Amazon RDS for MySQL。迁移的部分原因是团队知道不再需要调整数据库 IOPS,而且还可以降低一些运营成本。
三、感想
从传统数据库到云原生数据库,是时代发展的趋势。感受到了云原生数据库按需扩展以支持快速变化的网站流量;与内部数据中心相比,具有更大的弹性和灵活性;无需花费时间和金钱来调整 IOPS,从而将运营成本降低了不少;只需一分钟而不是几十分钟即可完成故障转移方案;为庞大的机密数据提供安全保障。这些好处是时代的红利,抓住时代的红利,机会是留给准备好的人。
以上是关于浅谈云原生数据库:回顾过去,未来可期的主要内容,如果未能解决你的问题,请参考以下文章