操作系统进程的实现---上---04
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统进程的实现---上---04相关的知识,希望对你有一定的参考价值。
操作系统进程的实现---04
温故知新
计算机硬件、操作系统、启动、接口…
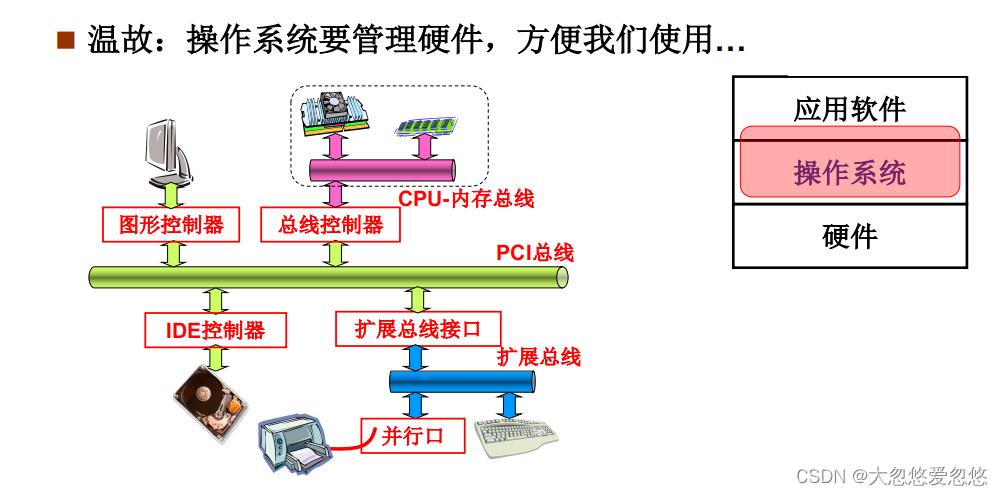
操作系统需要管理硬件,那么它需要管理哪些硬件呢?
- CPU和内存 —> 涉及进程
- 磁盘和外设 —> 文件管理
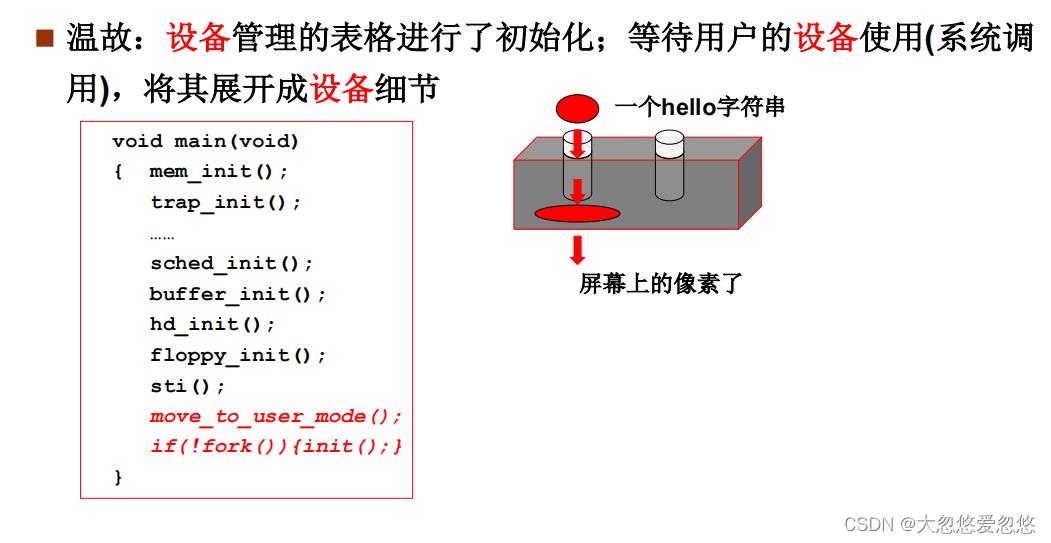
操作系统启动就是将操作系统从磁盘读入内存,然后调用相关初始化方法,初始化形成相关数据结构,让操作系统知道硬件的模样,然后启动shell,等待用户使用。
知新
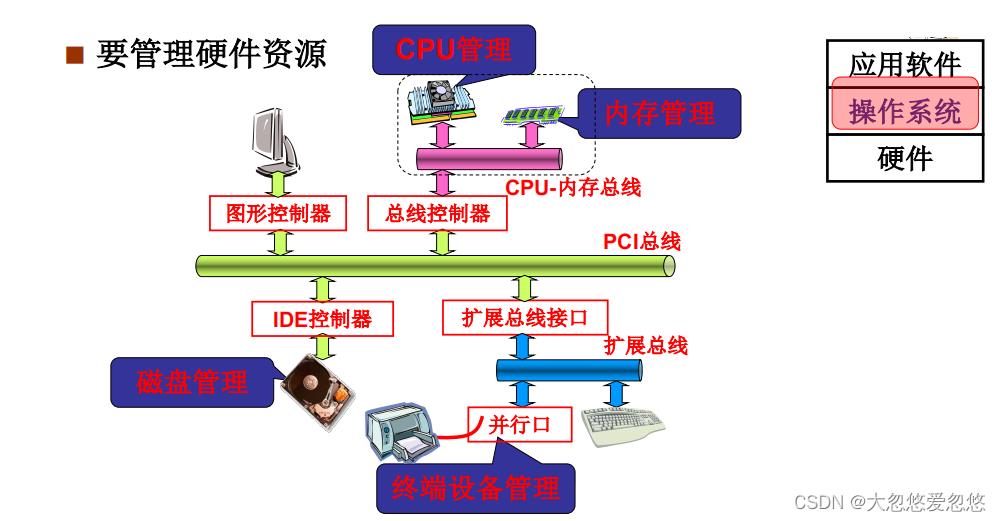
- 方便用户使用硬件资源
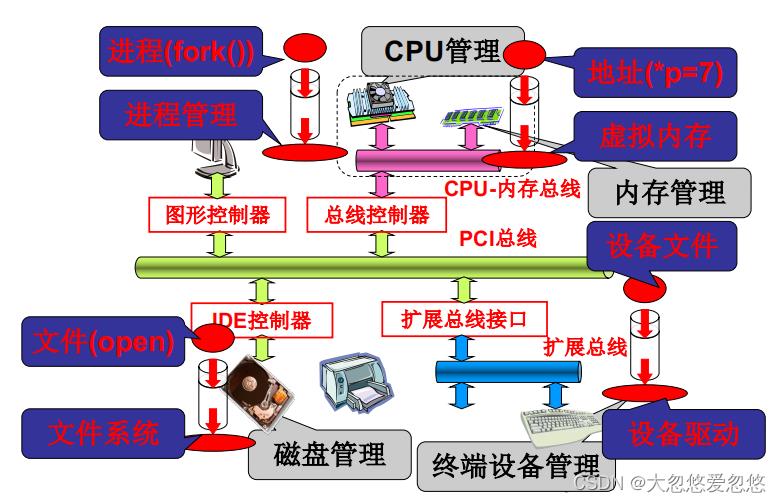
- 需要学什么
进程概念
管理CPU,先要使用CPU…
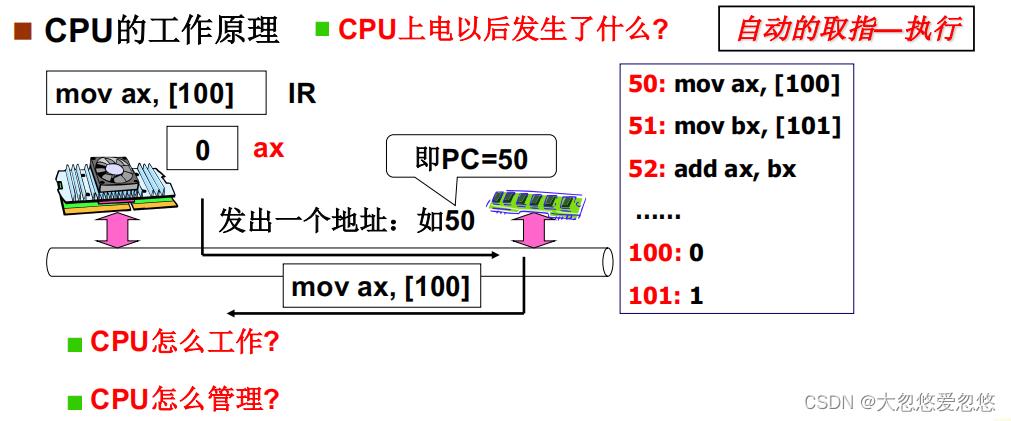
- CPU本质是取指执行
管理CPU的最直观方法
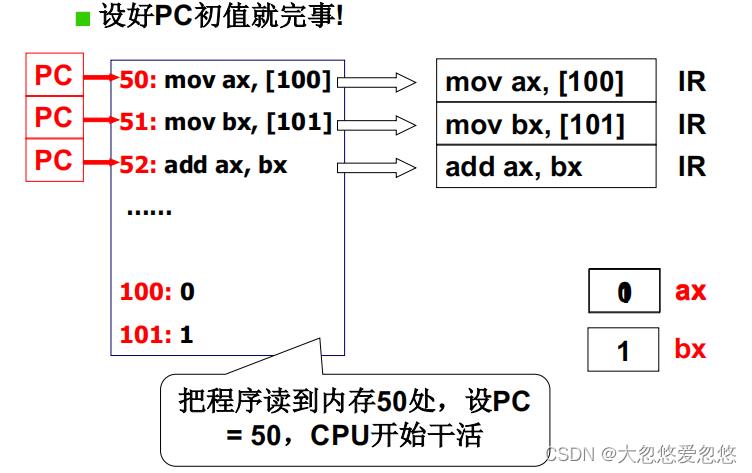
- 设置好PC的初值,然后CPU就不断取指执行即可,然后pc不断+1
看看这样做有没有问题?
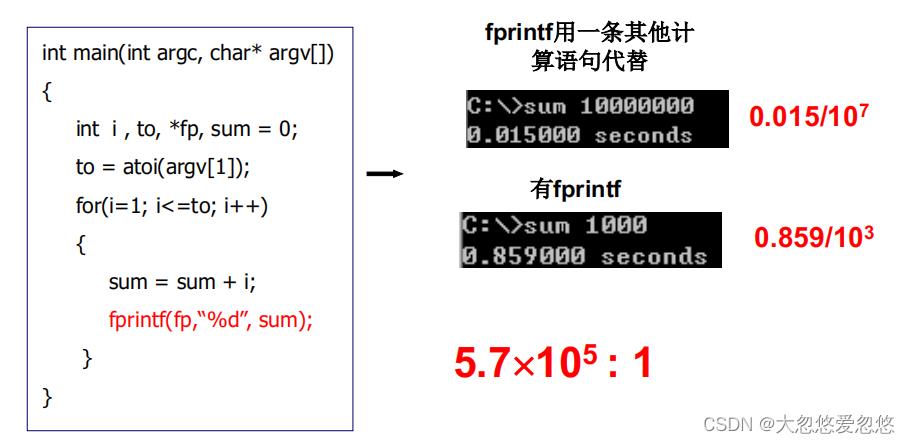
上面给出的是一段程序,执行一百万次不带IO指令fprintf的耗时,和带IO指令,但只执行1000次的耗时
- 可以看出来,带上IO指令后,IO指令耗时非常大
IO指令非常慢,执行一条IO指令的时间,可以执行100万条计算指令
- 如果CPU执行过程中遇到IO指令,就进入等待状态,直到IO就绪,才会继续往下取指执行,那么CPU将会有大量时间处于空闲等待状态,CPU利用率随着IO指令增多,而越来越低
怎么解决?
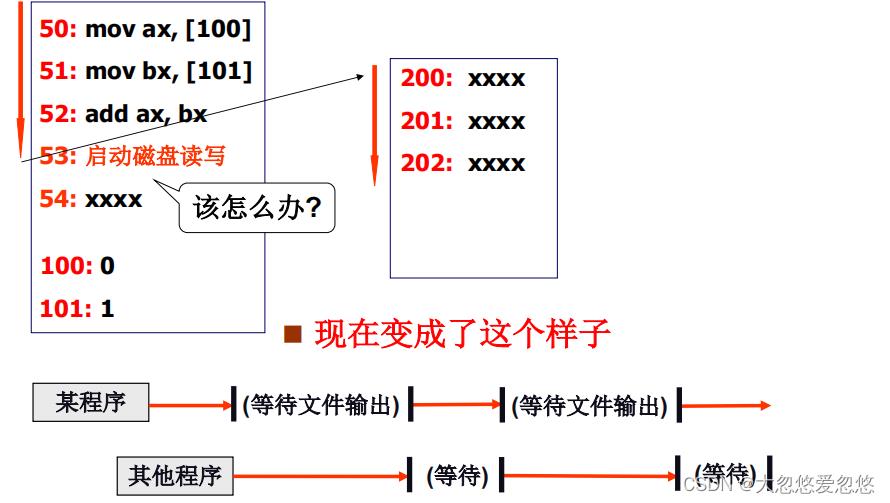
- 当CPU遇到IO指令时,可以先启动先关IO设备,然后切换到其他程序执行,等到IO就绪后,发送一个中断过来,提醒CPU IO已经就绪了
- 然后CPU在切换回来处理
多道程序、交替执行,好东西啊!
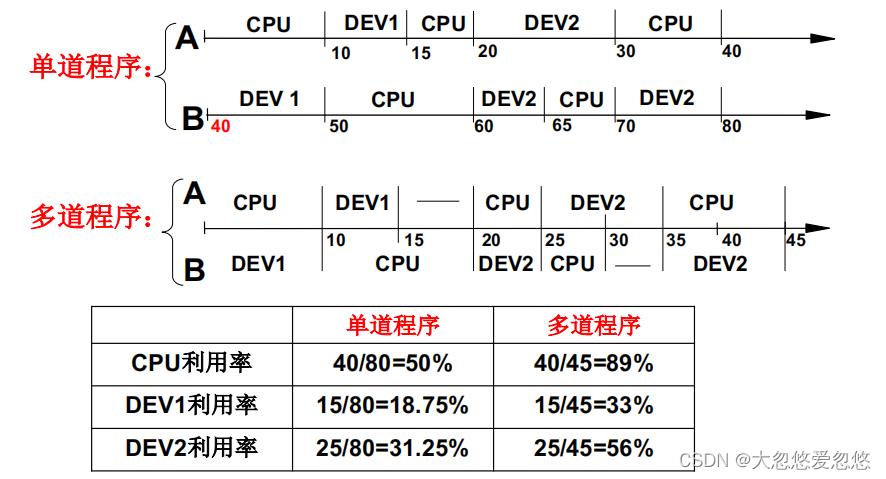
- 如果采用单道程序的话,就是CPU不断执行,遇到IO时,就需要进入等待状态,直到IO就绪,然后CPU继续往下面执行
- 如果采用多道程序的话,可以实现多程序并发执行的形式,即一开始程序B启动打印设备DEV1,然后切换到A程序执行,DEV1处理完后,再通知CPU,CPU再切换执行B程序,A程序此时又可以去利用DEV1执行某些操作。
上面的多道程序,可以让漫长的IO时间不必占用CPU资源,而让CPU可以充分被利用起来
一个CPU面对多个程序?
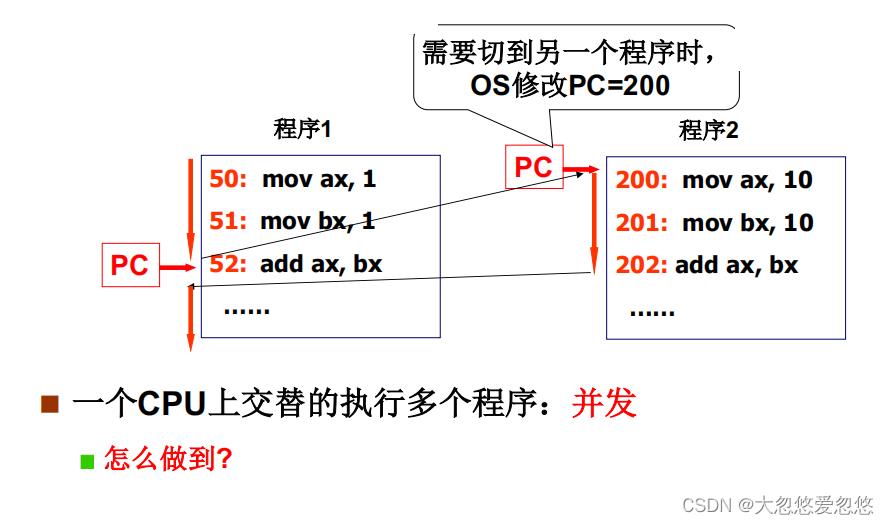
- CPU实现程序间的切换,难道仅仅只是通过修改PC值就行了吗?
修改寄存器PC就行了吗?
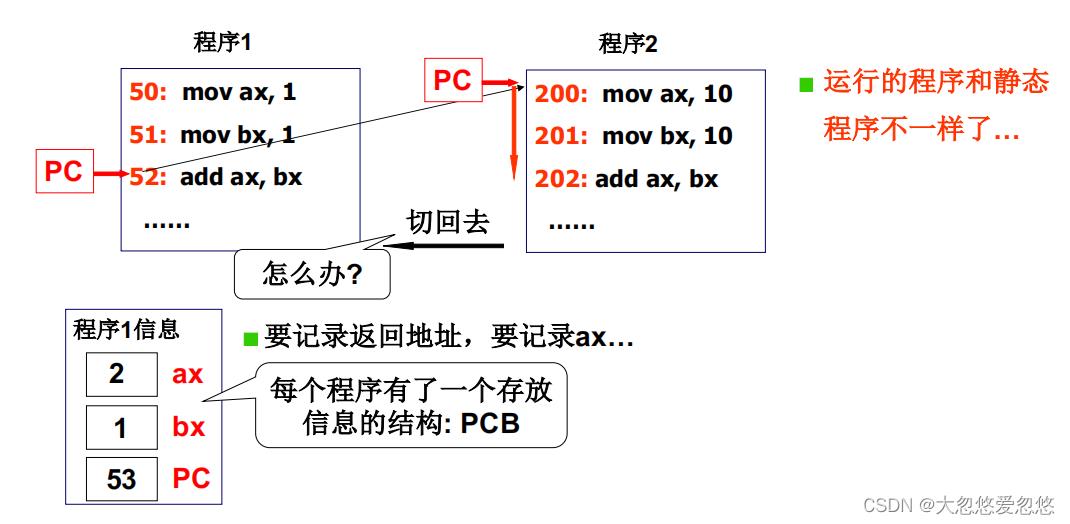
- 当CPU需要切换执行另一个程序时,需要保存当前程序的状态,包括当前程序PC值,相关寄存器状态等
- 当再次切换回来时,需要恢复之前的状态
引入“进程”概念
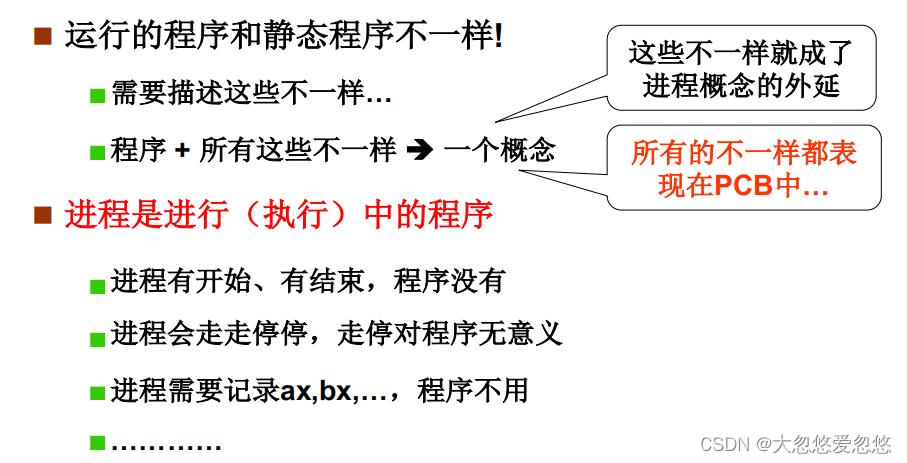
如果CPU只执行单个程序,那么利用率会很低,因此CPU需要去执行多个程序,这就引出了多个程序的切换执行,切换就牵扯到了程序状态的保存。
并且执行起来的程序和静态程序是不一样的,需要一个概念来描述执行起来的程序,这个词就叫做进程。
所以多个进程向前跑的样子,就是管理CPU的核心模样。
多进程图像
多个进程使用CPU的图像

每个启动的程序会创建相应的PCB记录当前程序执行的状态信息,然后CPU根据PCB表,进行程序之间的切换,完成多进程推进执行。
多进程图像从启动开始到关机结束
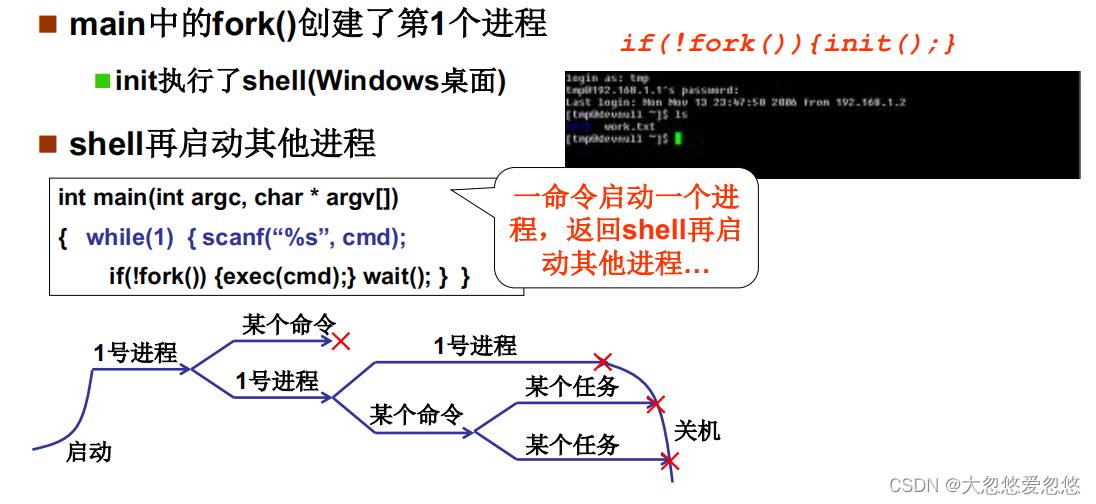
每当需要执行一个任务的时候,就需要开启一个进程进行处理
- 用户使用计算机,就是启动一堆进程
- 用户管理计算机,就是管理一堆进程
- 进程就是正在运行中的程序
多进程图像:多进程如何组织?
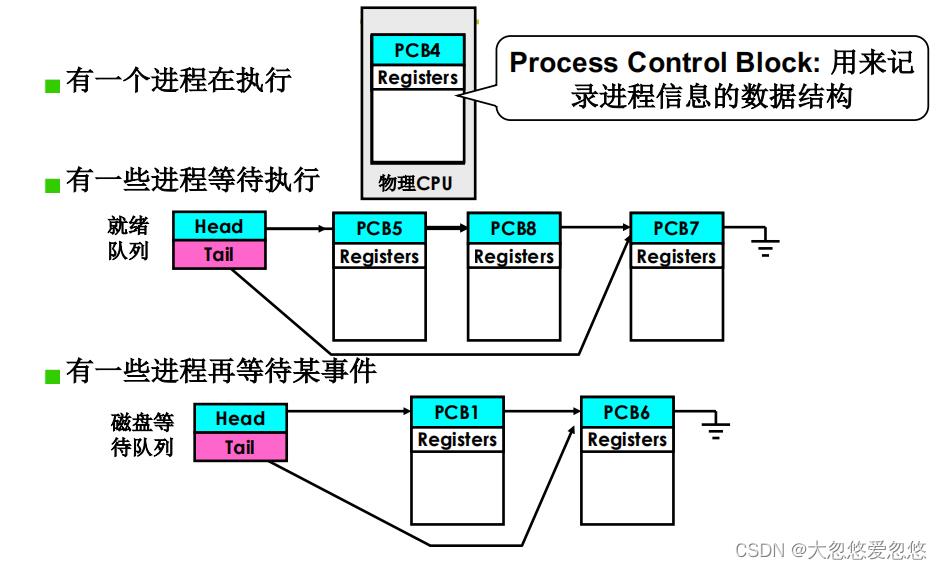
操作系统感知和组织进程都需要PCB的支持。
- 一个程序运行起来时,对应的会创建一个PCB来记录当前程序运行状态
- 因为一个CPU同时只能执行一个进程,因此其余已经就绪的进程,就需要放入到就绪队列中去
- 而对于那些需要等待某就绪事件的进程,则放入对应的等待队列中
多进程的组织:PCB+状态+队列
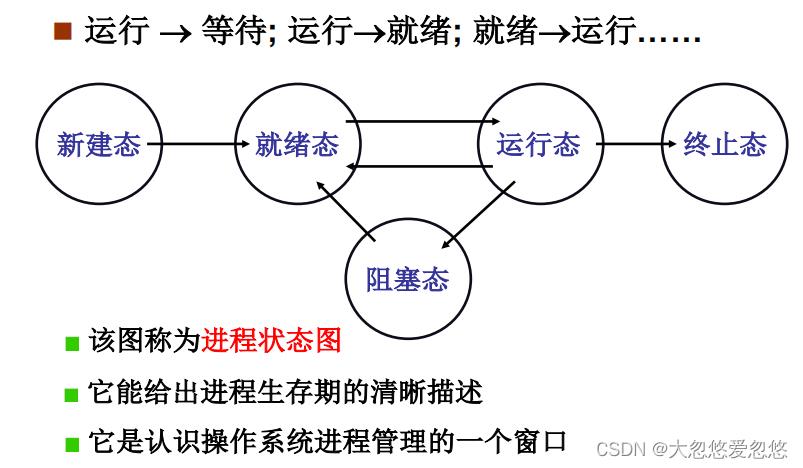
多进程图像:多进程如何交替?
上面主要讲述了如何组织和推进多个进程的执行,下面需要来思考一下多进程之间切换的过程

举例:
- 当前线程需要启动磁盘阻塞,首先需要设置当前进程状态进入阻塞态,将当前进程放入阻塞队列中去
- 进入进程切换函数schedule
- getNext完成进程调度,从就绪队列中找到一个进程
- switch_to完成进程的切换,保护现场,切换到新进程执行
交替的三个部分:队列操作+调度+切换
- 首先是调度,进程的调度是一个非常复杂的问题,这里不过多深究,先考虑几个简单的选择,先进先出和优先级

- 完成了调度,下一步就是切换
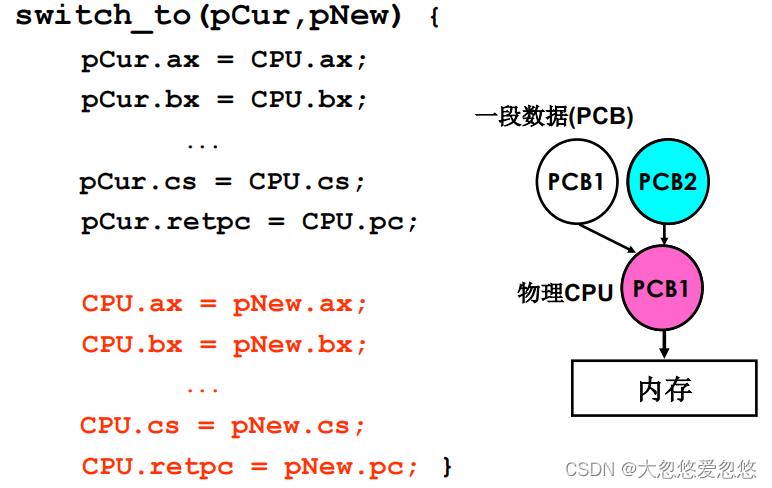
- 如果当前正在执行的进程是PCB1,要切换到PCB2执行,那么首先需要保存现场,将当前相关寄存器值和PC值,保存到PCB1中
- 然后将PCB2保存的寄存器状态值和PC值设置到当前CPU中,即恢复现场
因为涉及到对寄存器相关操作,因此进程切换的代码需要使用汇编编写
多进程图像:多进程如何影响?

因为进程其实就是运行的程序,那么程序本质还是一堆存放在内存中的数据,既然如此,如果进程1程序执行过程中,不小心修改了进程2程序的内存数据,那么进程2不就直接奔溃了吗?
然后实现进程之间的隔离,让不同的进程只能在分配给当前进程的内存中活动,是我们需要解决的事情。
进程执行时的100…
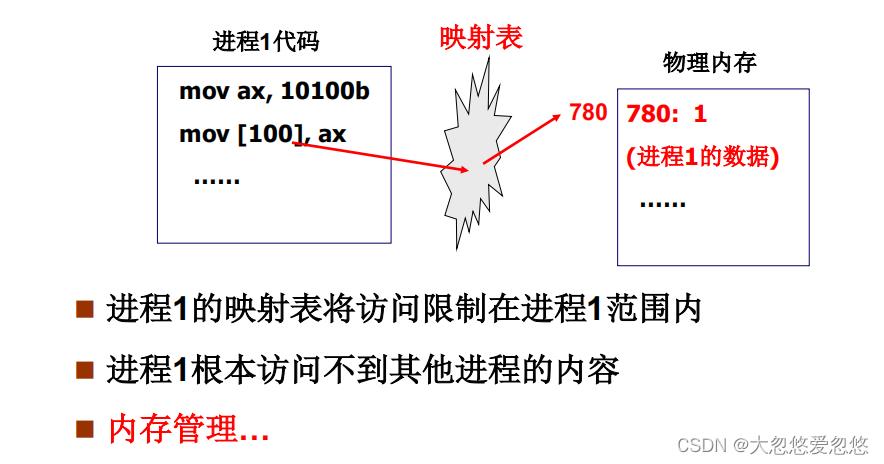
通过映射表完成进程的隔离,进程1访问地址100时,通过映射表会将地址100映射到780.
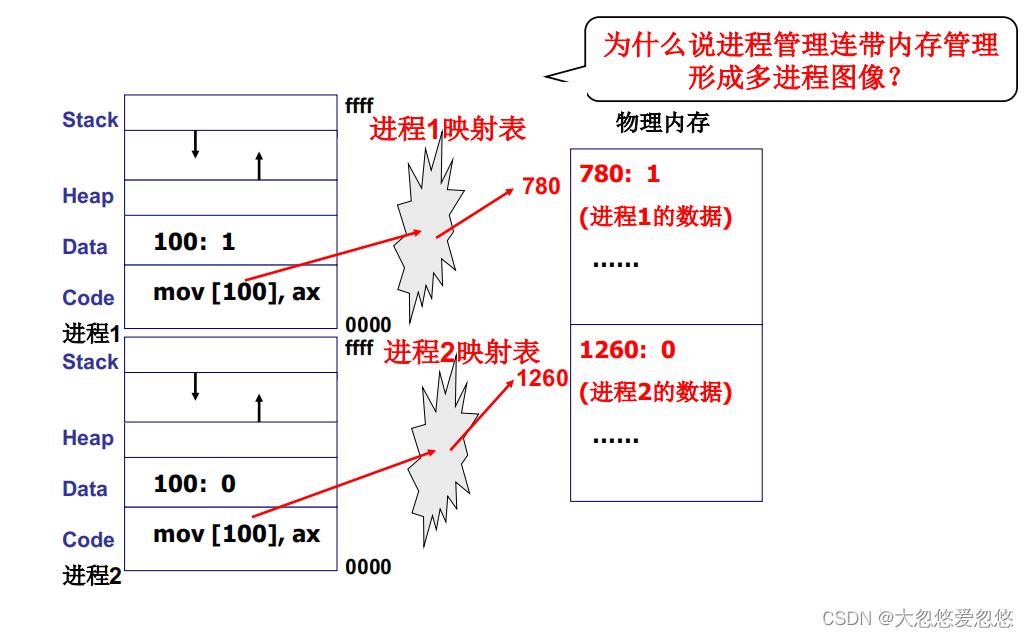
通过映射表处理后,及时两个进程中访问的都是同样的地址,但经过映射表处理后,都会映射到各自进程的内存空间中,从而实现进程间内存的隔离
多进程图像:多进程如何合作?
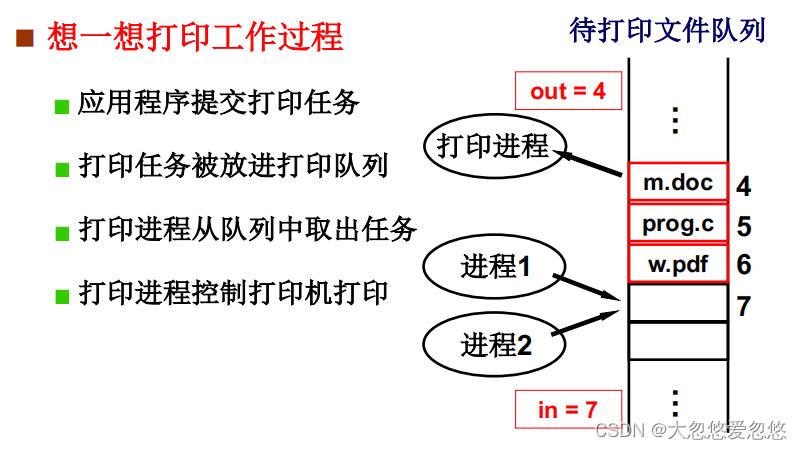
考虑一个打印场景,进程1要将打印pdf1的任务放入打印文件队列中去,因为此时7的位置是空闲的,因此进程1将pdf1放入位置7,但是放置了一半,此时CPU进行了进程切换,切换到了进程2执行,进程2也要进行打印任务,进程2把pdf2的任务放入打印文件队列中去,因为进程2也发现7是空闲的,因此也往位置7放,此时就乱套了。
从纸上到实际:生产者-消费者实例

有两个进程和一块共享的区域,消费者和生产者都可以操作其中的数据。
- 大家思考,上面两个进程同时运行过程中,会不会产生问题
两个合作的进程都要修改counter

- 可以看到,因为执行序列的原因,会导致得到的结果不是我们想要的,那么应该采取什么办法,才能够确保两个进程读取同时操作一块共享内存区域时,不会发生问题呢?
核心在于进程同步(合理的推进顺序)
要确保多进程操作同一共享内存区域时的进程同步,常规思路就是加锁,操作系统也是这样做的,下面来看看:

用户级线程
多进程是操作系统的基本图像
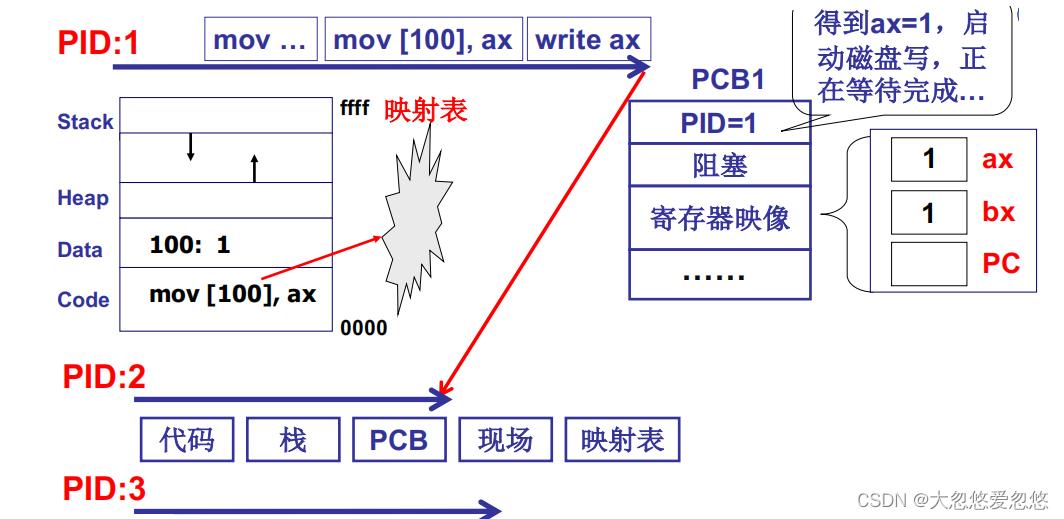
上面主要讲了进程之间的切换,需要通过PCB表和映射表完成切换过程,那么相当于使用映射表对多个进程进行了内存隔离。
进程之间的切换需要通过映射表完成,切换表需要耗费一定的资源,能否不切换表,而直接从A指令序列跳到B指令序列执行呢?
是否可以资源不动而切换指令序列?
如果将进程看做是资源+指令序列,那么如果我们把资源和指令执行分开的话,,一个进程内可以有多套指令执行序列,而资源还是只有一份,相当于多套指令执行过程中共享当前进程的内存资源。
那么这些正运行在进程中的指令序列,就是线程,一个进程内可以存在多个线程,多个线程运行过程中不断切换执行,并且切换只需要保存pc和相关寄存器状态,不需要切换表,这样可以提高效率。
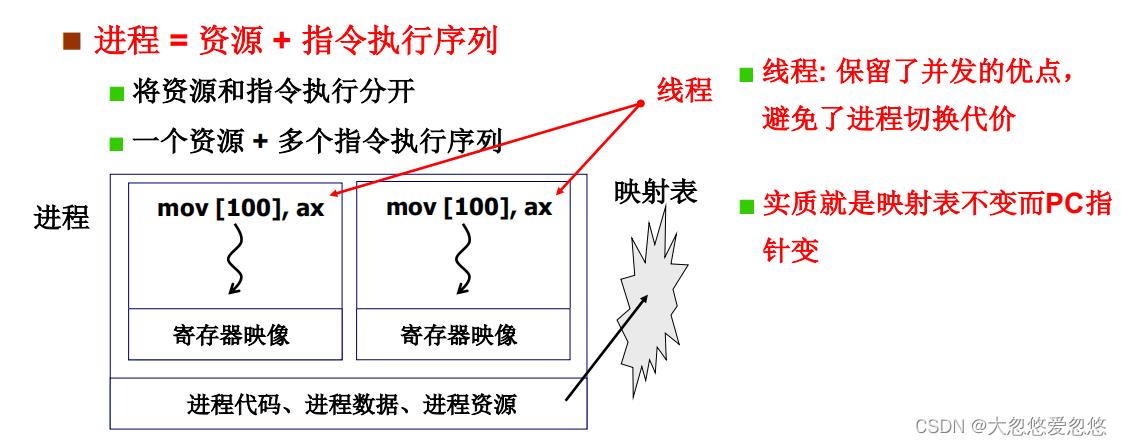
线程本质是指令之间的切换,一个进程中有代码片段,而多个指令序列会存在在这个代码片段中,每个指令序列一旦运行起来了,就是一个线程,当存在多个线程时,对于线程的切换,也只需要切换指令序列即可,不需要设计到映射表和内存段的改变。
多个执行序列+一个地址空间是否实用?
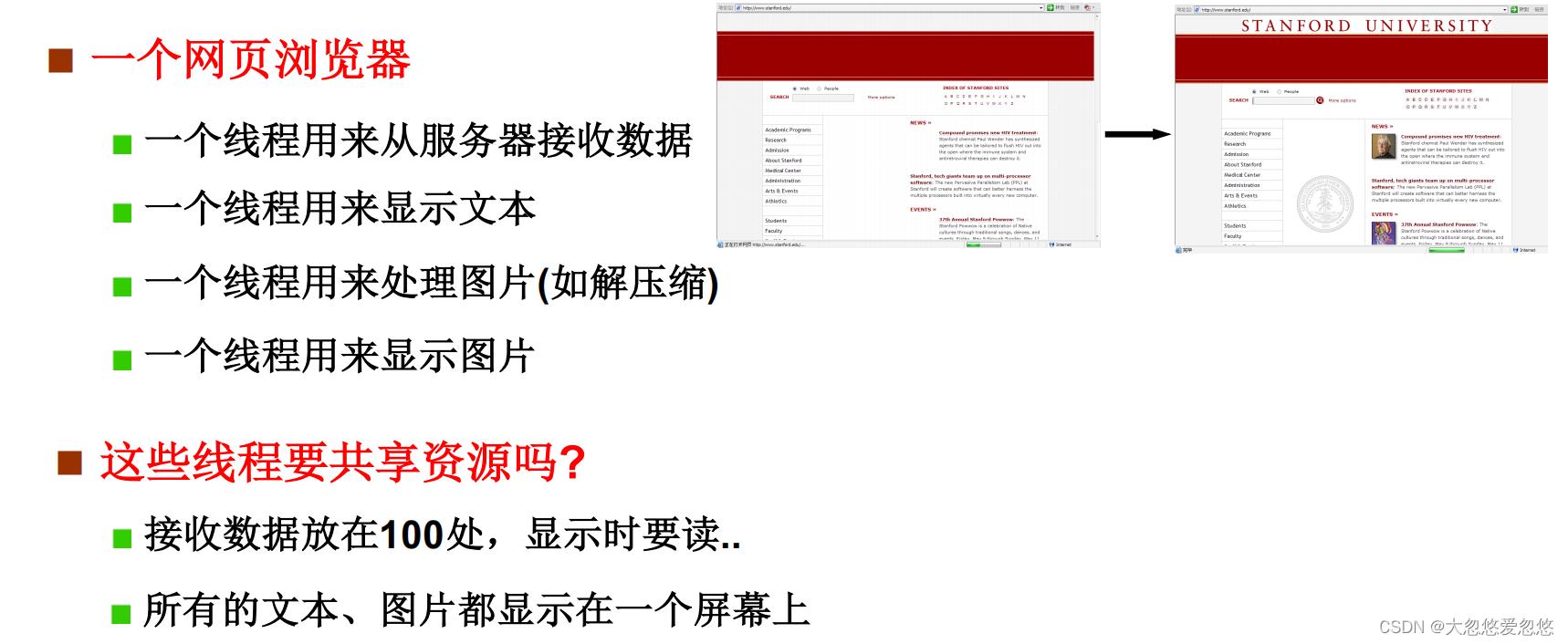
线程有有用,通过上面浏览器的例子也可以看出来,线程具有下面两个特点:
- 共享进程资源
- 切换代价小
开始实现这个浏览器…、
在没讲线程之前,我们的认识中一个进程同时只能去执行一个指令序列,而了解到线程的存在后,我们知道如果进程中可以启动对多个指令序列的执行,那么不就相当于在一个进程中创建了多个线程执行吗?
还有一个问题,我们必须让多个线程执行过程中不断切换执行,否则还是相当于多个指令序列同步执行,那么线程也就没啥用了,只有像CPU对待进程那样,不断切换进程执行,才能真正实现多线程执行的效果。

所以上面给出的代码中通过create函数同时触发了对多个指令序列的执行,相当于创建了多个线程。
而Yield函数用来完成线程之间的切换。
Create? Yield?
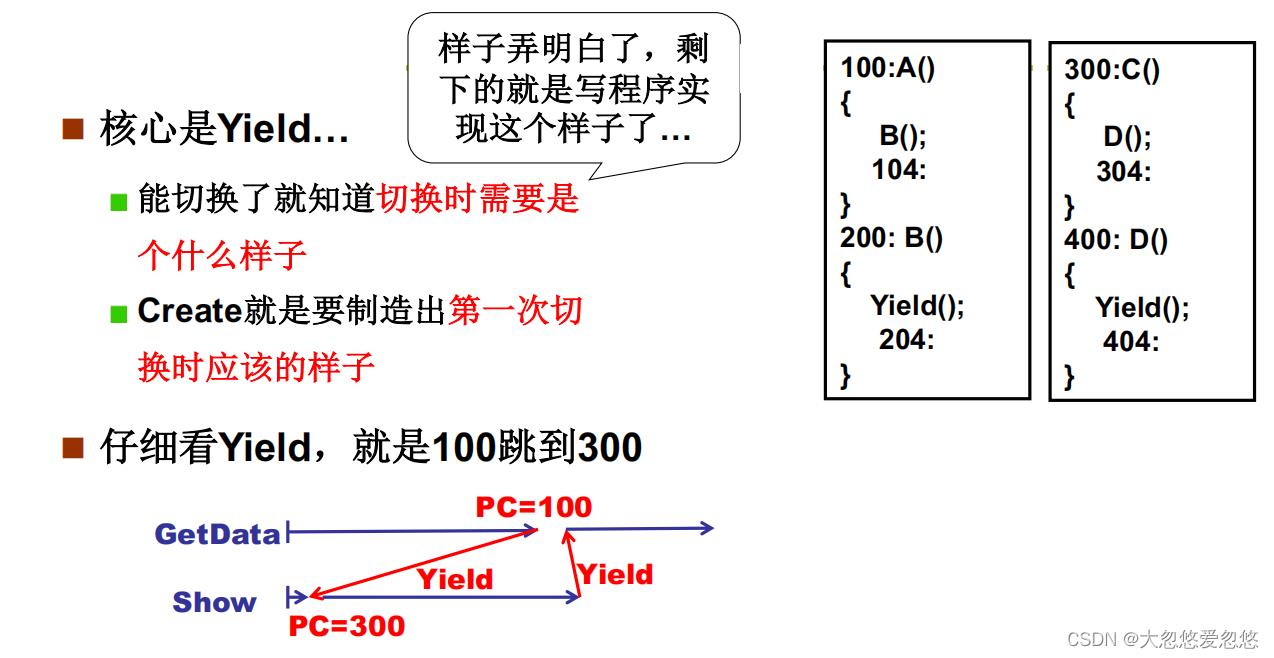
上面给出了两段指令序列,相当于两个线程在运行,然后B()函数执行过程中,通过yield函数,将线程切换到300地址,即c函数处执行
两个执行序列与一个栈…
两个指向序列如果共享一个栈会怎样呢?
函数嵌套调用过程中,需要通过栈保存当前pc值和相关寄存器状态
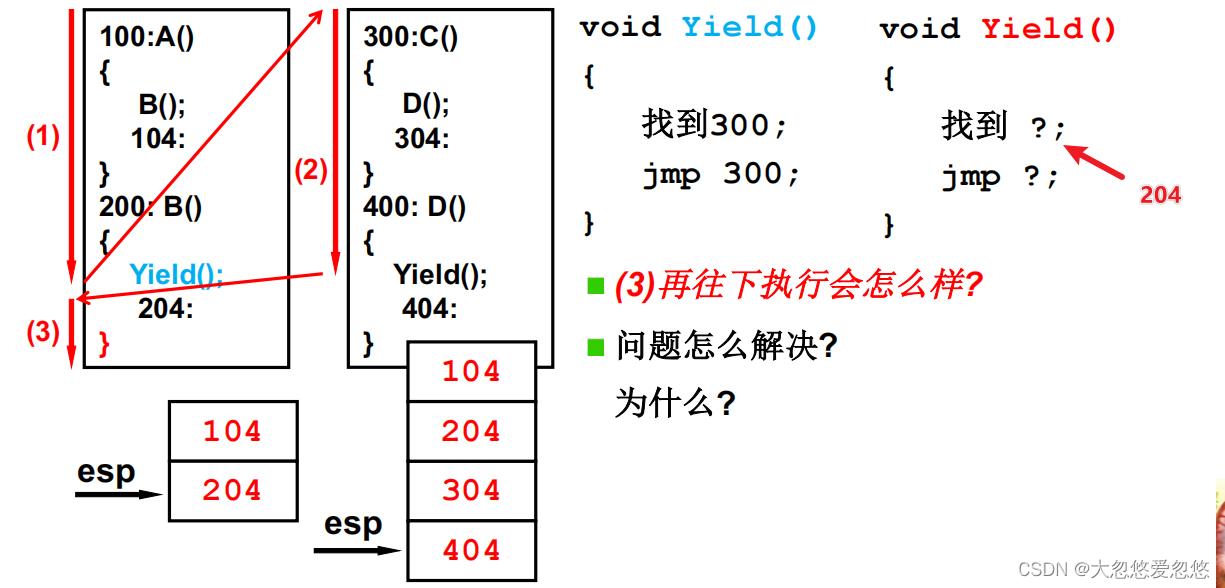
- A调用B函数,需要在栈中保存pc值104
- B通过调用yield函数,切换指令序列执行,栈中保存pc值204
- C调用D时,栈中保存304
- D中调用yield函数,切换指令序列执行,栈中保存pc值404
- 此时因为线程切换,来到了B函数的204位置,函数执行结束后,通过弹出栈顶元素,获得接下来要跳去的地址,发现是404
- 显然,不符合要求,应该跳去104才对
- 这就是多线程共享栈的问题
从一个栈到两个栈…
每个执行序列,即每个线程执行过程中都单独分配一个栈,那么就没有问题了吗?
- 因为引入了多个栈,因此就存在栈顶指针切换的问题,例如:
下面中,400:处的函数D执行Yield函数切换到B函数中的204处执行前,需要做一步工作,就是切换栈。
因为栈顶指针寄存器esp只有一个,并且当前栈顶指针寄存器esp指向的是右边指令序列的栈顶,而因为当前指令序列需要发生切换,所以栈顶指针esp指向也需要切换,切换到左边指令序列位置。
因此,我们需要提前用一个数据结构保存每个指令序列当前栈顶指针的值,即TCB。
这里有两个指令序列,因此存在两个TCB,分别保存各自的栈顶指针的值,并且TCB是一个全局数据结构。
操作系统中一个线程对应着一个TCB(Thread Control Block),叫做线程控制模块,控制着线程的运行和调度。
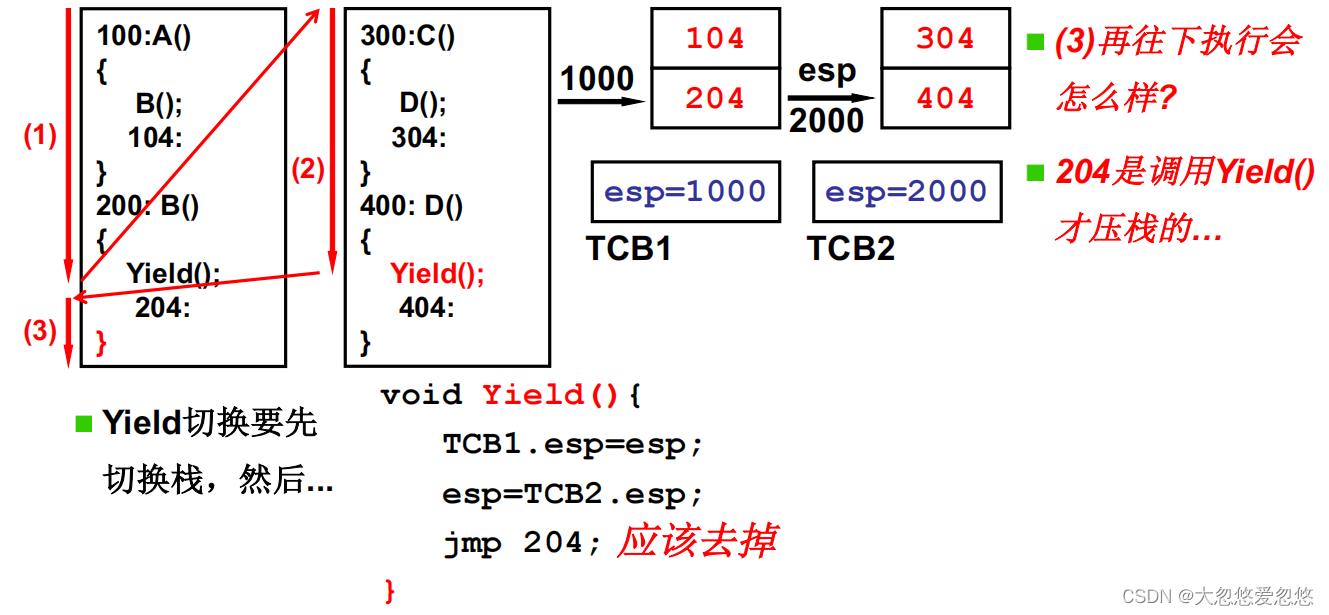
所以在Yield函数切换过程中,实际也是改变当前栈顶寄存器esp的值,然后跳转到对应指令序列执行即可。
Yield函数最后一行jmp 204有必要吗?
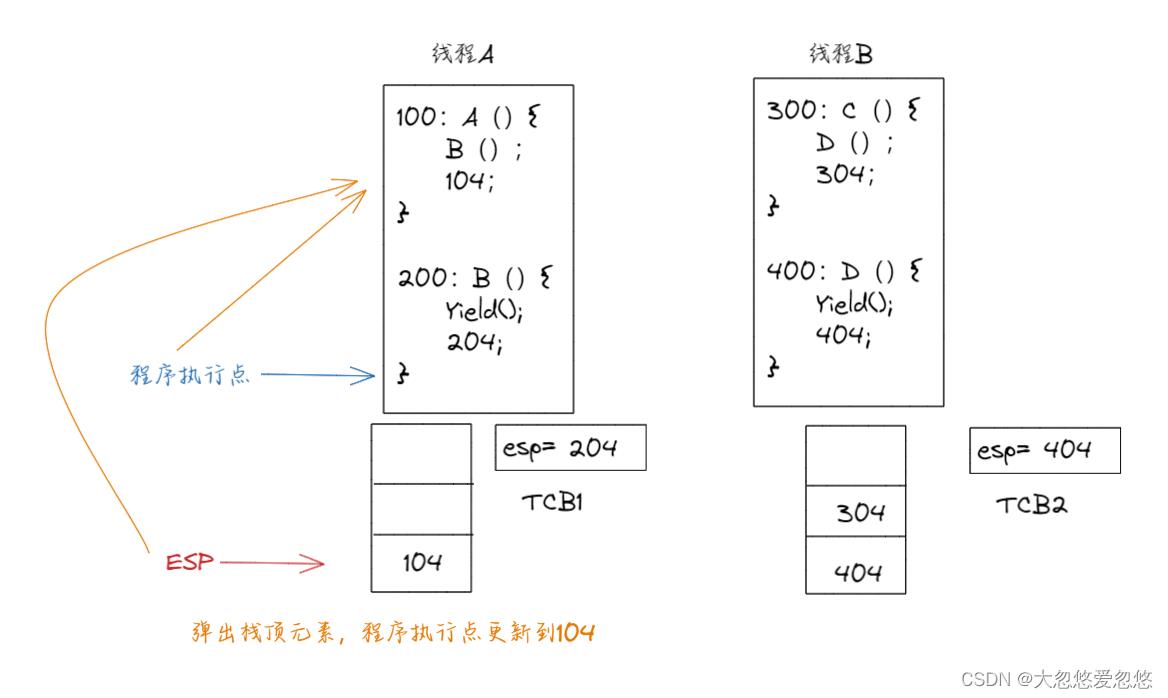
显然是没必要的,并且加了还会有问题,可以分析一下,当函数D中执行Yield函数切换到函数B的204处执行时,当函数B执行完毕,遇到 右括号时,会弹出栈顶元素,即回到先前调用函数B的地方,继续往下执行,按理应该是跳到104执行。
这里涉及到函数执行过程中入栈和出栈的编译知识
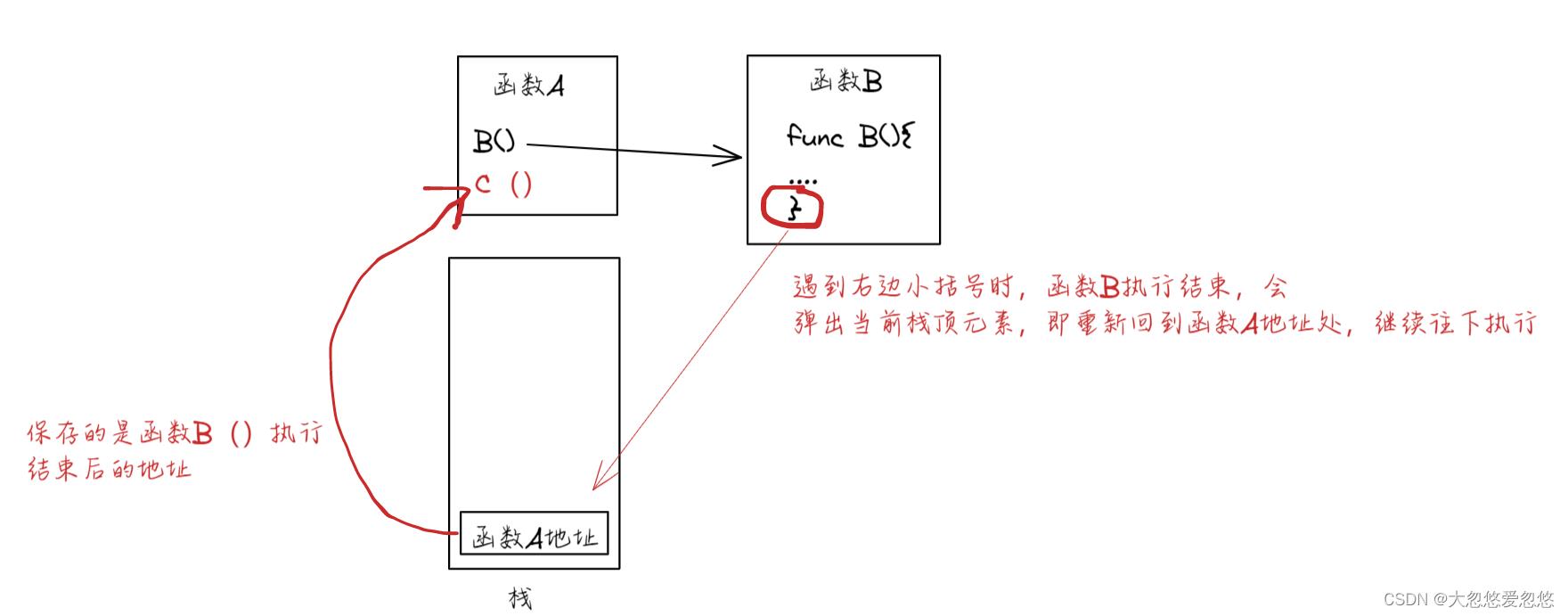
但是,可以发现此时左边指令序列对应的栈顶指针指向的位置是204,显然不合理呀!
这是为什么呢?
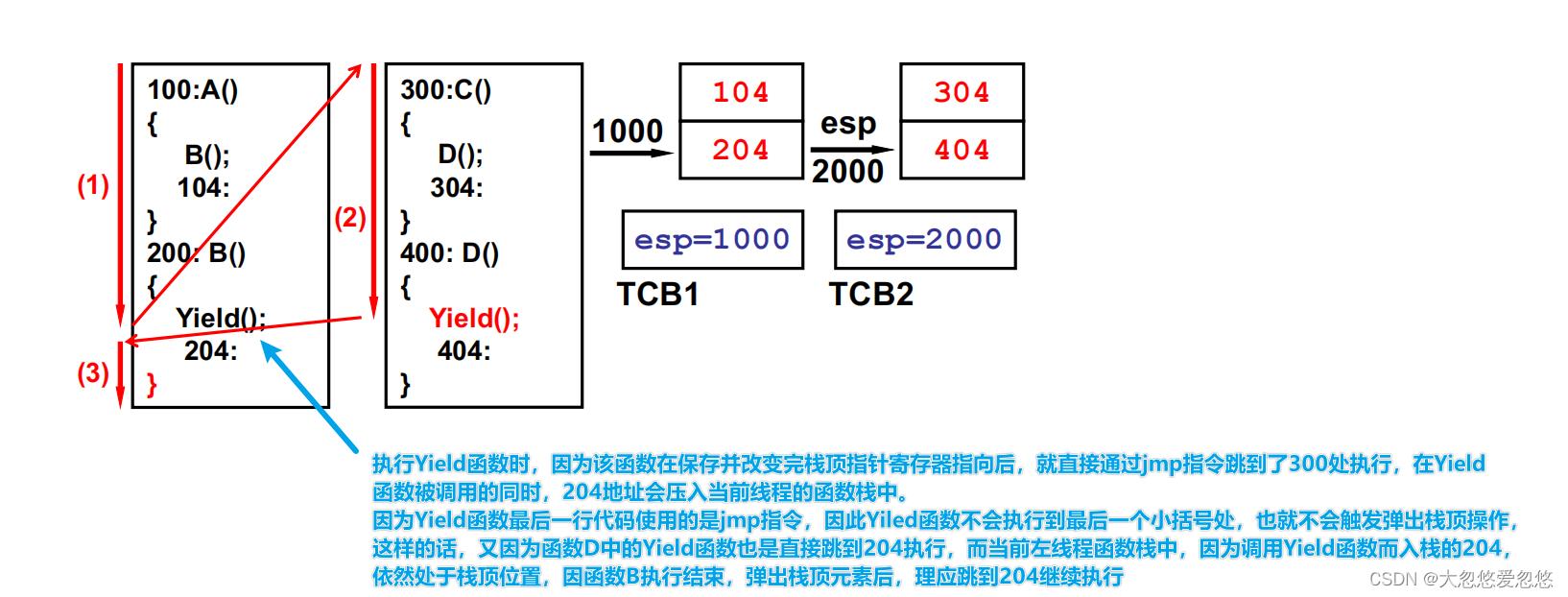
- 本质原因是因为jmp指令可以乱跳,Yiled函数没有执行到最后一个小括号结束,却可以通过jmp指令直接跳到yield函数执行结束后的地址处
- 解决方法也很简单,就是去掉jmp指令即可
去掉jmp指令后,yield函数中只需要完成栈顶指针保存和改变即可,然后Yield函数执行完毕后,会弹出改变指向后的esp指针指向的栈顶元素。
一开始esp指向线程1的栈顶位置,然后经过yield函数后,esp执行线程2的栈顶位置,此时yield函数执行完毕后,需要弹出esp指向的栈顶元素,即弹出线程2的栈顶元素,不是线程1的哦!!! 虽然yield函数是在线程1中被调用的,但是弹栈靠的是esp栈顶指针寄存器指向的栈顶位置
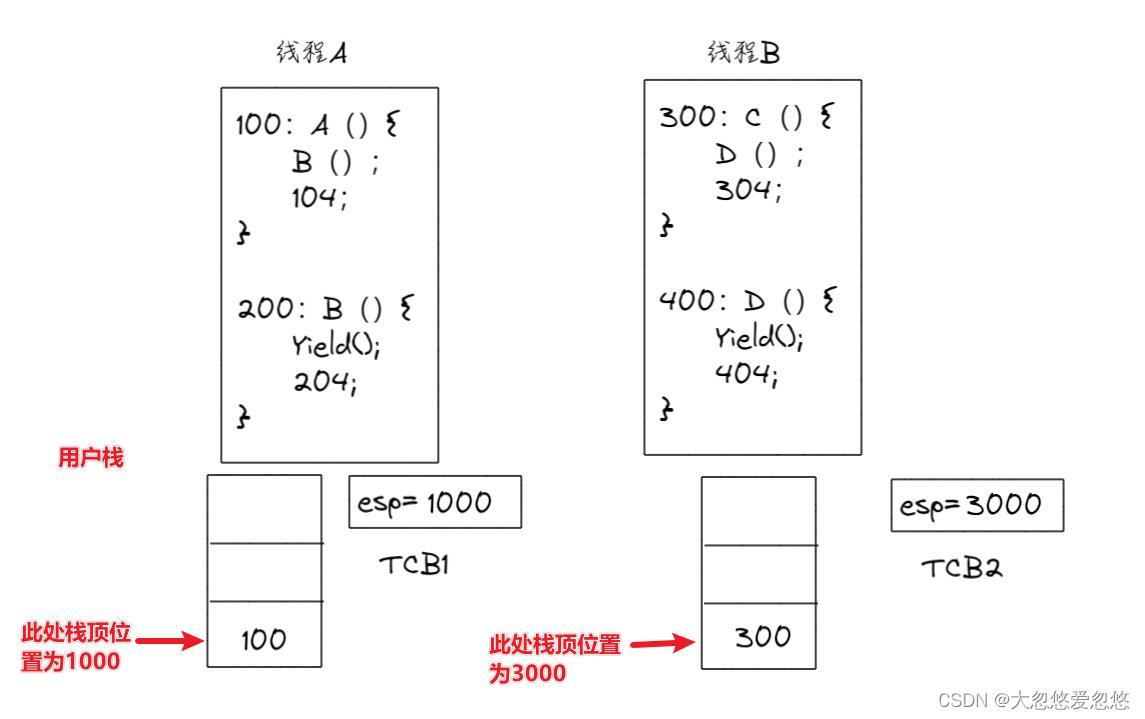
两个线程的样子:两个TCB、两个栈、切换的PC在栈中
esp是一个寄存器,用于指向当前cpu执行到某个线程时,对应线程关联的用户栈或者内核栈的栈顶位置。当某个函数执行结束后,会去弹出esp执行的栈顶元素,然后程序跳转到该元素位置处继续执行。

线程初始化,需要为当前线程创建一个栈,并且将当前函数入栈,再创建一个TCB保存当前线程的栈顶指针位置
具体流程如下:
- 创建线程A,再创建线程B
- 执行线程A

- 执行到B函数中的Yield函数并调用时
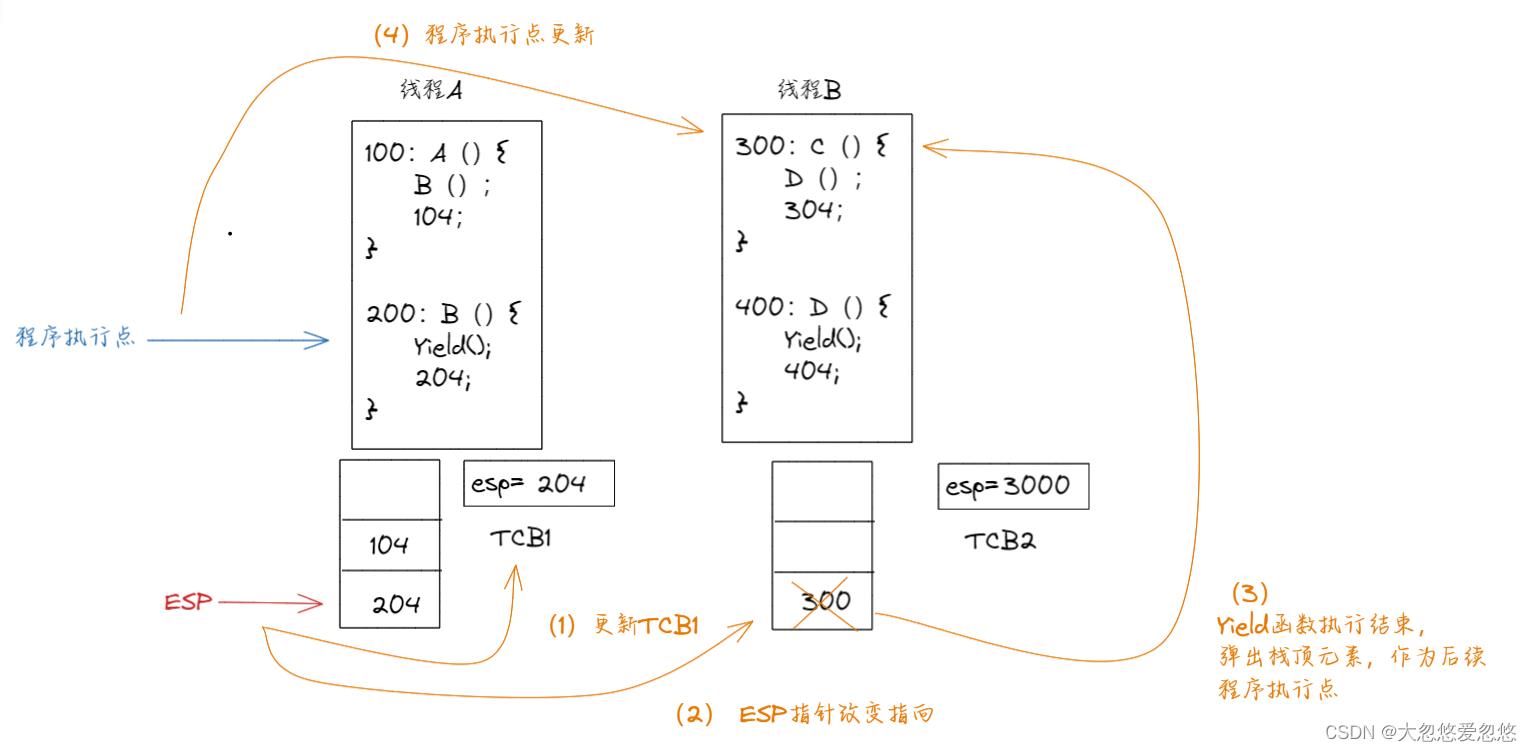
在进行线程切换时,首先需要将当前esp指向栈顶地址保存到当前线程关联的tcb中,这里假设esp指向的栈顶地址和该栈顶地址存放元素值相同。
然后,通过将要切换到的线程B的TCB中的值,赋值给esp,就完成了线程的切换
void Yield()
TCB1.esp=esp;
esp=TCB2.esp
第二步结束后,Yield函数就执行结束了,函数执行结束后,会将esp栈顶寄存器指针指向的栈顶元素弹出,因为此时已经完成了esp指针指向的切换,因此这里弹出的是线程B的函数栈
- 当线程B中的D函数,执行并调用Yield函数时
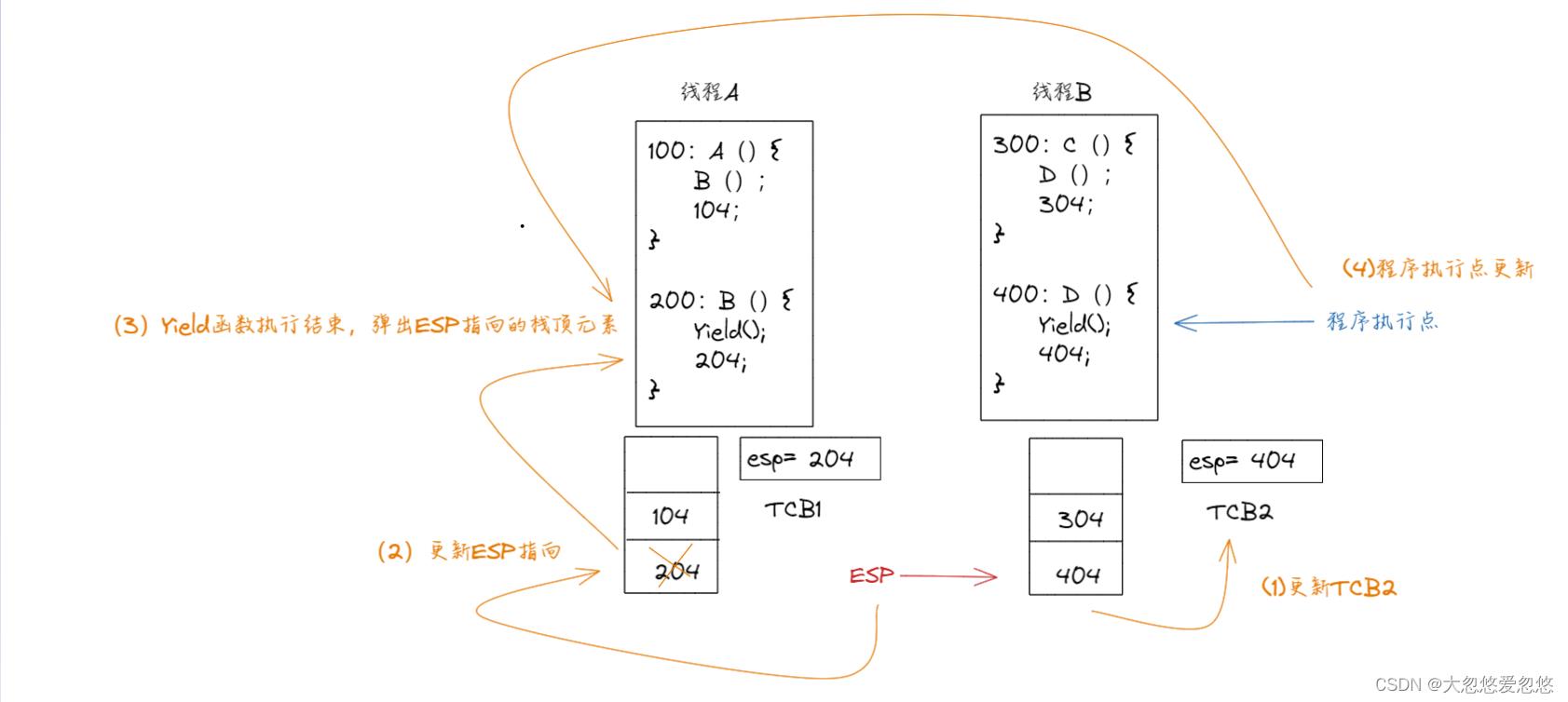
- 当函数B执行结束后,会跳到哪里呢?
将所有的东西组合在一起……

如果要写出一个上面讲到的浏览器模型,其实主要就是下面几点:
- 线程的创建函数 createThread
- GetData函数在遇到下载需求后,先启动下载,然后调用Yield切换线程执行,因为下载过程不需要CPU参与
- Yield函数,除了对相关寄存器状态保存,esp栈顶指针寄存器操作外,还有一点,就是需要通过调度算法选出一个线程来进行切换执行
为什么说是用户级线程——Yield是用户程序
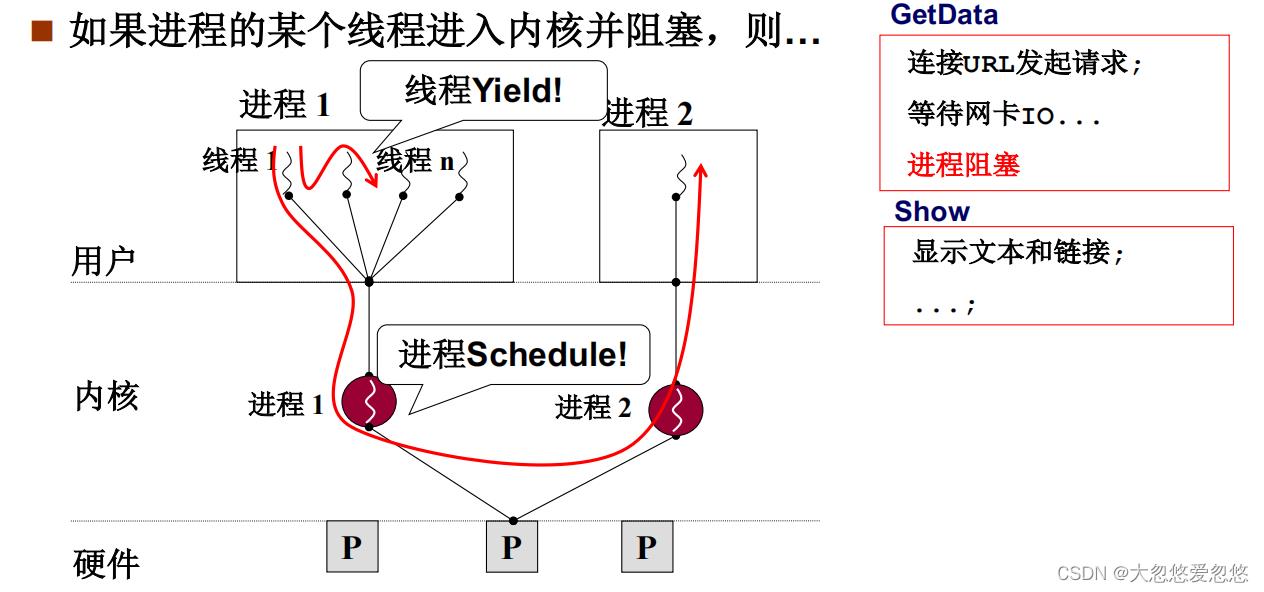
用户级线程只会在用户态来回切换,内核态是不知道用户线程存在的。
- 用户级线程缺点如下:
那上面浏览器案例举例,如果浏览器中某个用户线程执行了下载请求,因为下载需要访问网卡IO,网卡需要硬件,而使用硬件必须经过内核来操作,因此已访问网卡IO,就需要进入内核。
而网卡IO一阻塞住,内核就会切换进程执行,即从当前进程1切换到进程2执行,虽然此时进程1中还有其他线程可以切换执行,例如显示文本的线程,但是由于是用户级线程,操作系统看不见,因此不会处理,直接切换进程。
如果是采用用户级线程实现的浏览器,那么一般一个标签页对应一个用户线程,如果其中一个用户线程阻塞,那么会导致进程切换,即当前浏览器进程失去了对CPU的使用权,所以一旦一个标签卡住了,其他标签也动不了
即使此时只存在浏览器一个进程,那么也会因为其中某个用户级线程阻塞,失去对CPU控制权,CPU处于空转状态,因为CPU看不到其他用户线程,也就不会进行切换
用户级线程切换是不需要进入内核态完成的,并且线程调度算法需要用户自己完成
核心级线程
核心级线程和用户级线程区别,哪个快?
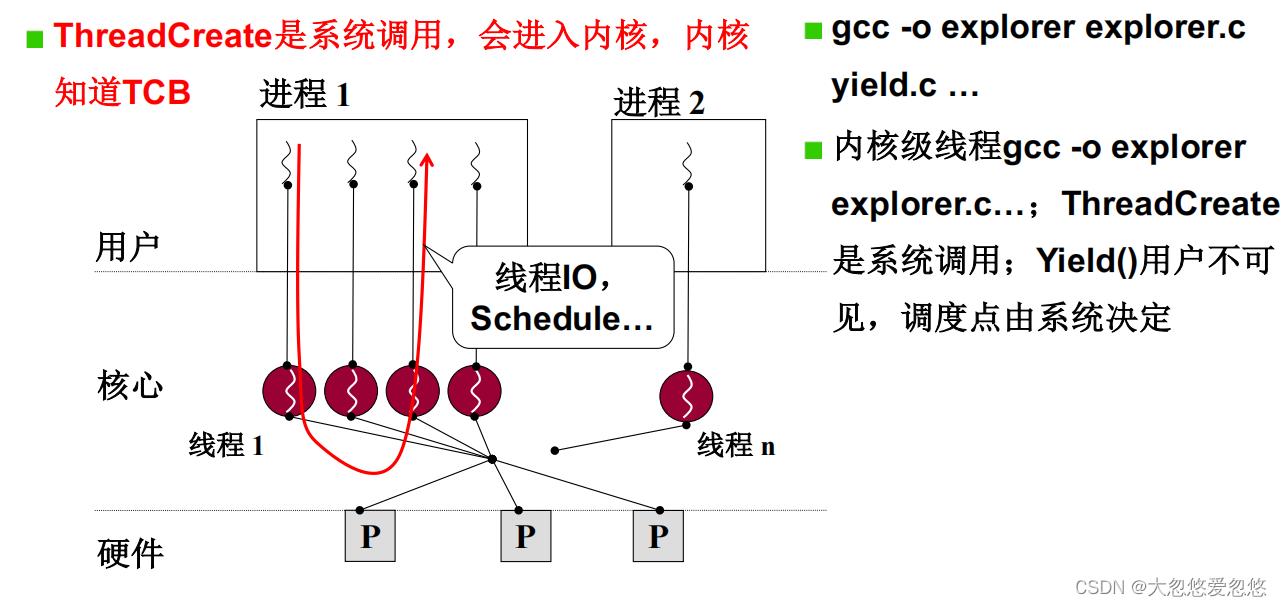
核心级线程和用户线程最大的区别在于,操作系统即内核可以看到相关的核心级线程存在,这样即使某个进程中某个核心级线程IO阻塞住了,CPU也可以切换到当前进程的其他核心级线程继续执行。
而对于用户级线程而言,用于不受内核控制,因此用户需要自己写相关线程调度算法
内核级线程
对于用户线程来讲,其切换过程就是先将指向当前线程函数栈顶的esp指针位置保持到本线程对应的TCB中,然后通过调度算法选择切换到哪一个用户线程,然后将对应用户线程关联的TCB恢复到esp上,然后在弹出esp指向的栈顶元素位置开始执行。
因为栈顶指针寄存器只有一个,而线程有多个,因此在线程切换时,需要一个TCB保存切换时esp指针指向的栈顶位置,再线程切换回来的时候,好恢复现场
开始核心级线程
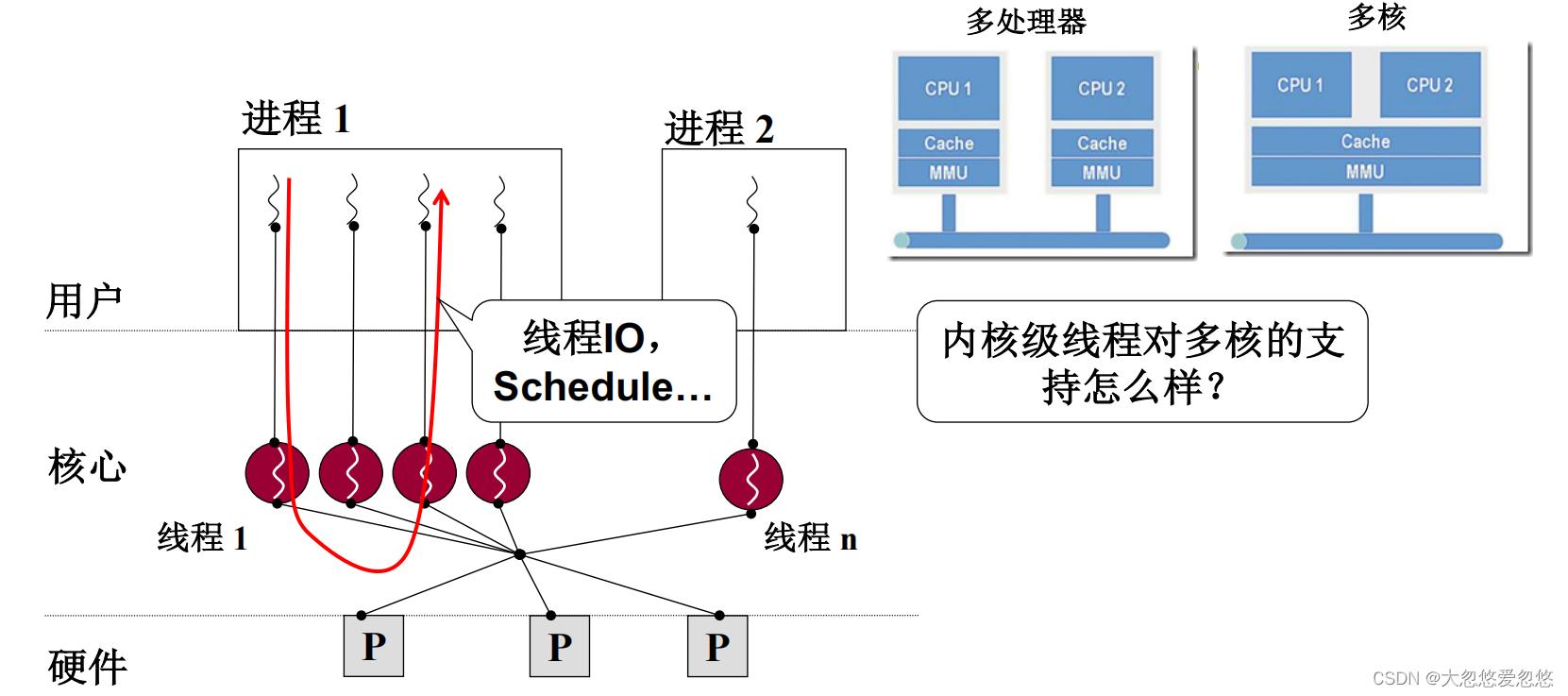
- 对于多处理器来将,每个CPU有其对应的MMU (MMU暂时可以理解为映射表)
- 而多核来说,多个CPU共用一个MMU
多个执行序列使用一套映射,这不就是线程吗?
因此可以简单把多处理器看做是支持多个进程执行,但是由于一个MMU只对应一个CPU,因此该进程内,同时只能处理一个指令序列,因此指令序列只能并发执行。
而对于多核处理器来说,因为多CPU共用一个MMU,因此可以很好的支持一个进程内的多个核心级线程并行执行,因此每个CPU可以同时执行一段指令序列,并且是并行执行。
如果是多进程的话,对于多核处理器来说,需要不断对一套MMU进行切换,计算机根本并行不起来。
并发是同时触发,交替执行
并行是同时触发,并行执行
对于多核来说,为什么一定要是核心级线程呢?
- 操作系统看不见用户级线程,因此也不能为用户级线程分配各种硬件资源
- 因为要访问硬件资源,就必须要进入内核,因此必须要使用内核级线程
和用户级相比,核心级线程有什么不同?

首先,我们需要明白一点,用户区和内核区是分开的,因此对应的函数栈也是不同的。
因此用户区中的函数,如果调用了内核相关的函数,进入内核区的话,需要切换到内核的函数栈。
上面说过,对于内核级线程来说,因为需要在内核中创建,因此必须要进入内核去中。
因此,如果要从用户态切换到内核区,需要准备两套栈
- 在用户态进行线程切换的步骤上面讲过了,就不多说
- 而如果要在内核栈进行内核线程切换时,此时TCB关联内核栈,就需要连同用户栈一起切换过来
用户栈和内核栈之间的关联
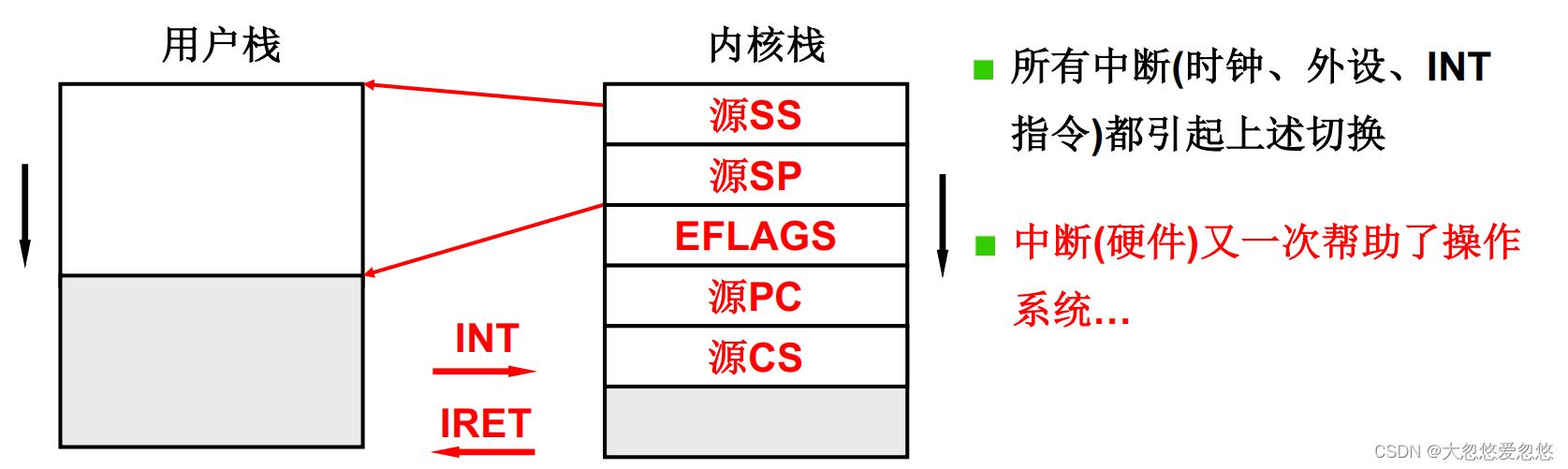
进入内核的唯一方法就是中断
每个内核级线程都对应两套栈,分别是用户栈和内核栈,那么是如何找到内核栈的呢?
- 暂时可以理解为,只要产生了中断,就会找到当前线程对应的内核栈地址
当发生中断,产生用户态到内核态的切换时,会定位到当前线程关联内核栈地址,然后将用户栈的两个状态寄存器SS和SP保存到内核栈中。
还要保存到内核栈中的是pc和cs寄存器的值。
当内核函数执行完毕后,通过IRET指令返回,该指令会弹出上面压入的五个元素,通过pc和cs恢复到刚才用户态中执行指令的位置。
通过SS和SP的值,恢复用户区中函数栈的状态。
仍然是那个A(),B(),C(),D()…
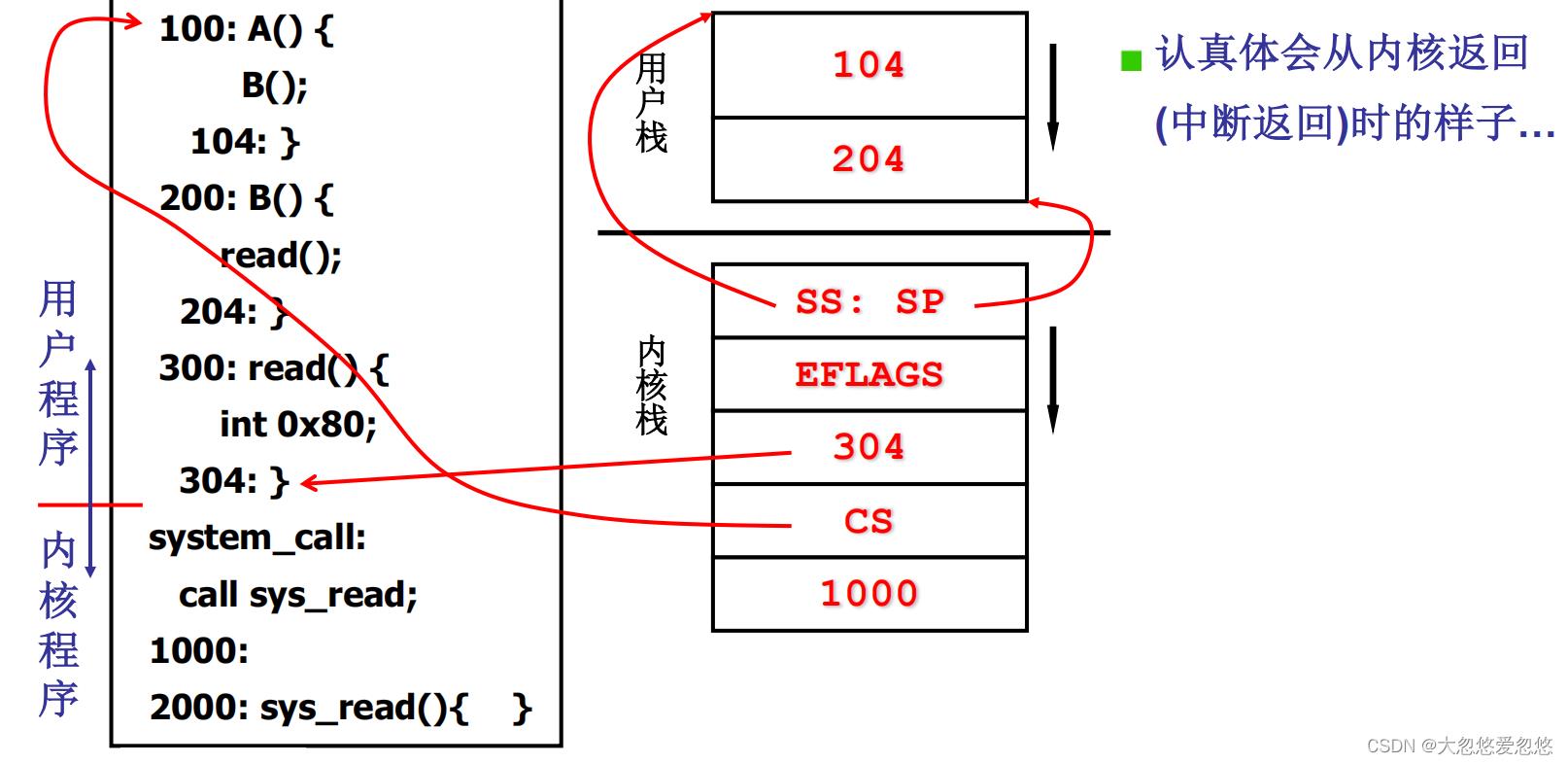
当执行到int 0x80的时候,会产生中断,将用户栈和指令执行位置状态入栈。
大家可以思考一下,如果中断返回了,是不是就直接恢复到用户区304位置去执行了,然后用户栈的状态也恢复了,非常完美
进入内核区后,因为会先调用sys_read函数,因此会把1000压栈,表示sys_read函数执行结束后,会调回到1000地址处继续执行。
开始内核中的切换:switch_to
当内核函数sys_read被调用后,会启动磁盘读,然后当前内核线程进入阻塞状态。
下面就需要进行内核线程的切换。
线程和进程没有本质的区别,区别在于切换时,是否需要切换映射表,以及是否会共享内存资源
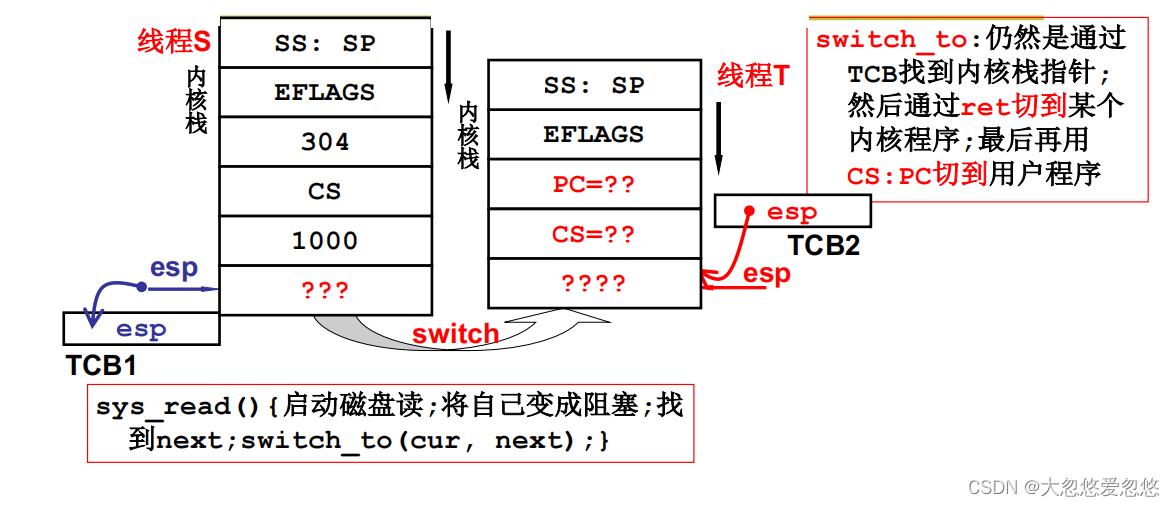
内核栈的切换和用户栈切换类似,首先需要找到下一个内核线程。
然后通过switch_to方法进行内核线程的切换,cur是当前线程TCB,next是下一个线程的TCB。
- 内核线程S要切换到内核线程T
- 首先将指向当前线程S内核栈的esp指针状态保存到TCB1
- 将TCB2中保存值赋值给esp,相当于完成了esp指向的切换
- switch_to函数执行完毕后,会弹出当前esp指向的栈顶元素
- 然后线程T切换到该栈顶元素对应地址处执行
esp是一个寄存器,用于指向当前cpu执行到某个线程时,对应线程关联的用户栈或者内核栈的栈顶位置。当某个函数执行结束后,会去弹出esp执行的栈顶元素,然后程序跳转到该元素位置处继续执行。
回答上面的问号??, ???, ???..
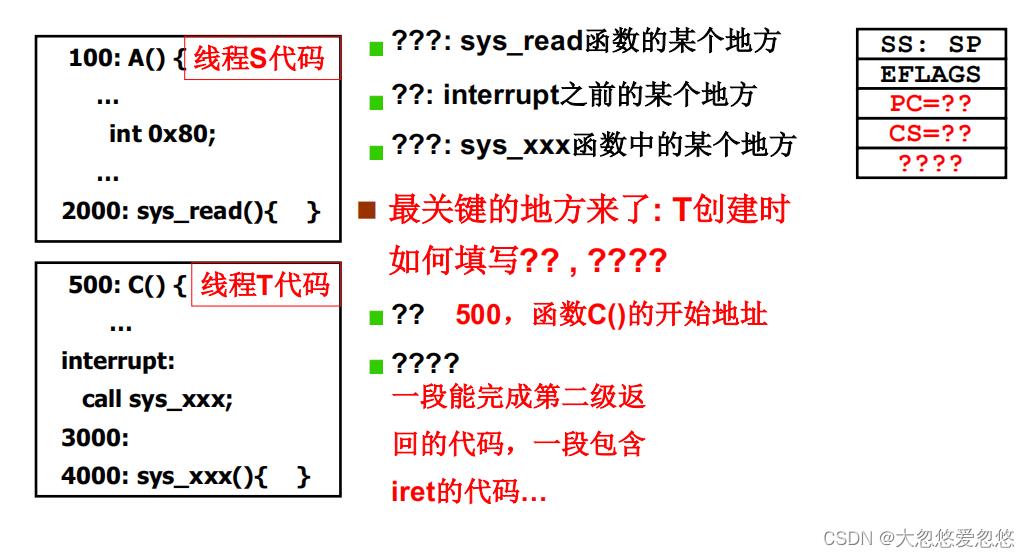
因为要完成内核线程的切换,就必须进入内核态才行,因此当前线程s通过中断切换到内核态进入阻塞后,因为此时需要发生内核线程的切换,要切换到线程t
因为线程t被创建时,会在内核栈中保存当前线程t的用户栈状态和pc,cs状态,因此当第一次切换到线程t执行时,便会弹出这些状态,好恢复到线程t原先运行的样子。
如果线程t是因为阻塞或者时间片到期,被切换的话,那么切换时,也会把相关状态压入当前线程t对应的内核栈中
所以,最后四个问号,保存的是一段包含iret的指令。
内核线程switch_to的五段论
假设是内核线程S需要切换到内核线程T
- 线程S通过中断进入内核区,并且会保存用户态状态到内核栈中
- 找到线程S的TCB1,将当前esp保存到TCB1中
- 再通过相关调度算法,找到切换到下一个线程T
- 获取到线程T的TCB2,赋值给esp,此时switch_to函数执行完毕,需要弹出esp指向的栈顶元素
- 线程T跳到栈顶元素位置处执行,然后执行过程中会执行iret指令,弹出线程T保存的用户态状态
- 线程T回到用户区继续执行
- 后续,如果线程T因为调用相关系统函数,进入阻塞状态 , 或者因为时间片到期,也会触发中断,再次进行内核线程切换,重复上面步骤

- 中断(磁盘读或者时钟中断)
- 调用schedule完成切换
- 调度算法获取下一个线程的TCB,然后调用switch_to进行切换
- 完成内核栈的切换,即tcb切换
- 第二级切换,通过iret指令,弹出用户态状态
- 如果线程S和线程T属于不同的进程,还需要进行映射表切换
ThreadCreate! 做成那个样子…

- 申请当前线程关联的TCB内存
- 在内核态中分配当前内核线程的内存,在用户态分配对应内核线程的内存
- 内核栈中会保存对应用户态的状态,最后还会加上相关中断出口,可以恢复到用户态继续执行
- 设置TCB相关状态
内核线程之所以可以让操作系统看见,是因为他在内核态中有一套内核栈,内核栈中保存了对应用户区状态,这是和用户线程的区别
因此对于内核线程的创建来说,既需要在用户态中分配相关内存存放用户栈和其他数据,也需要在内核态中分配内存存放内核栈数据,并且还需要在内核栈中记录用户态的状态,方便在内核态完成线程切换后,可以恢复到用户态继续执行。
用户级线程、核心级线程的对比
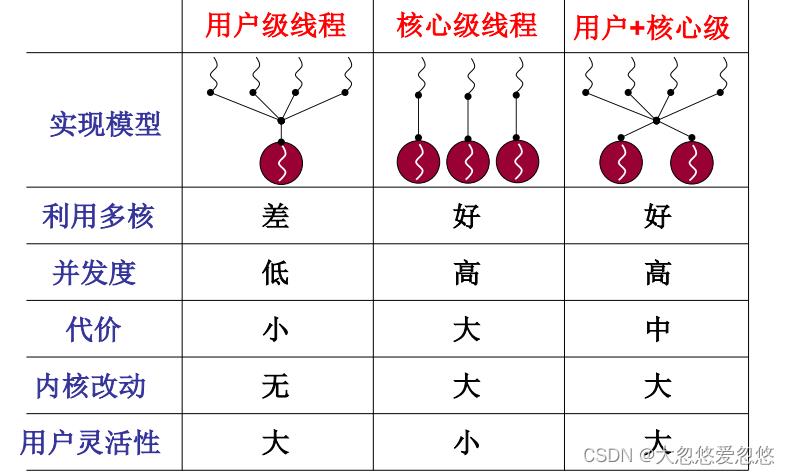
- 用户级线程的切换只在用户态完成,并且线程调度算法由用户自己完成,因此即使一个进程中存在多个用户级线程,其实也可以看做只存在一个核心级线程
- 核心级线程的切换在内核态完成,并且线程调度算法由操作系统完成,因此一个进程中存在多个内核级进程,每一个内核级进程都可以利用一个CPU,这样就可以完成多线程并行执行。 但是由于内核级线程切换需要进入内核态完成,因此切换代价大。
内核级线程和进程的区别其实已经很小了,区别就在于完成了线程的切换后,再切换映射表
以上是关于操作系统进程的实现---上---04的主要内容,如果未能解决你的问题,请参考以下文章