MQkafka——如何保证消息不丢失?如何解决?
Posted AresCarry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MQkafka——如何保证消息不丢失?如何解决?相关的知识,希望对你有一定的参考价值。
一、前言
前一篇博客我们介绍了生产者为什么发送消息的吞吐量这么大,其实就是因为,生产者提供了内存缓冲区,把消息打包再发送,从而提高了吞吐量。
那么,消息发送过去,到了broker就算是成功了吗?会不会丢失呢?这篇博客,就向大家介绍一下 kafka在什么情况下会出现消息丢失以及解决方案。
二、什么情况会丢失消息?
首先我们还是要看一下,kafka的架构图:
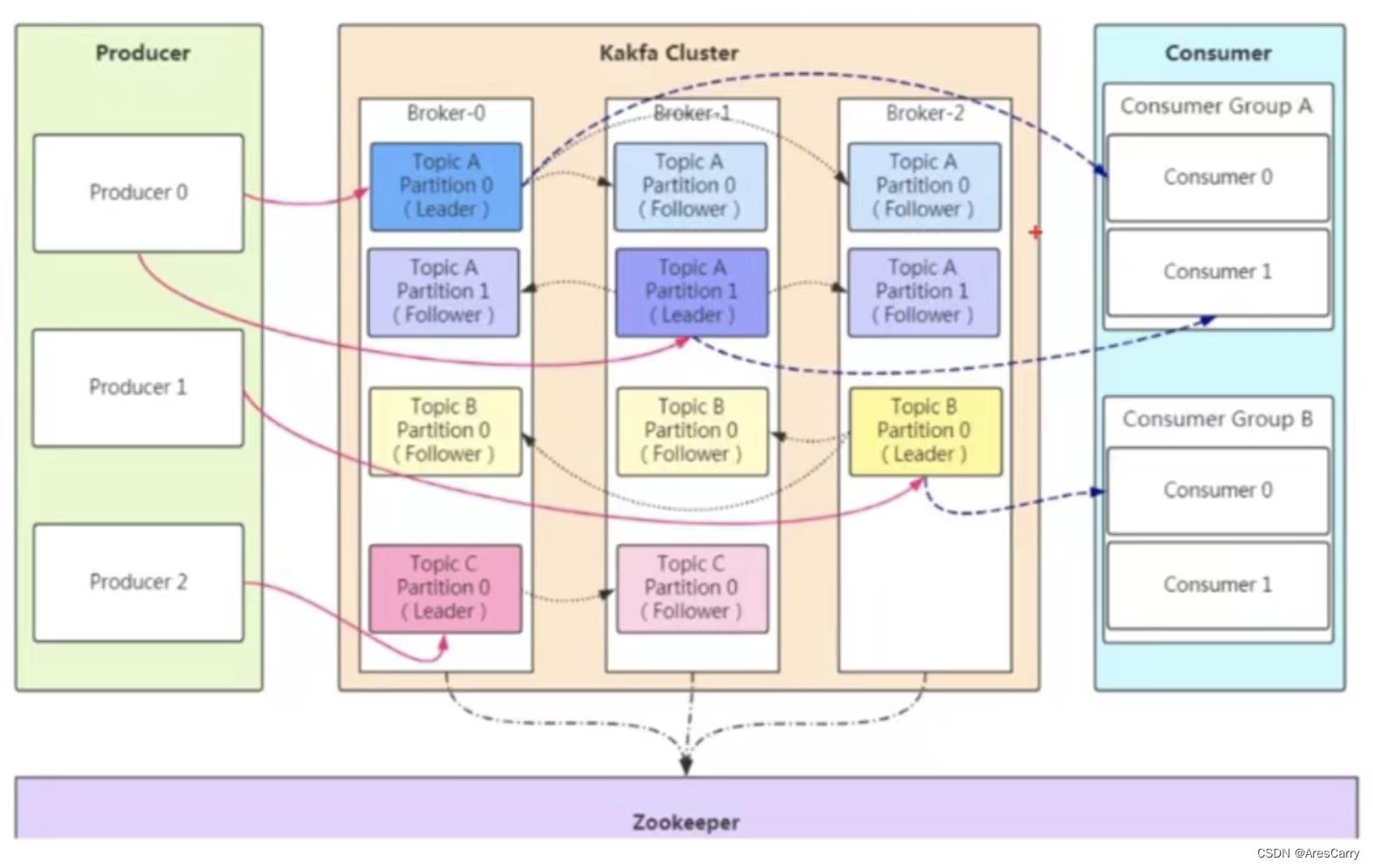
因为我们有三个角色:生产者,broker,消费者。
消费者是消费消息,一般不会丢失,那么消息丢失就会出现在 生产者和 broker之间。
三、生产者的消息丢失和解决
丢失原因分两种
- 消息没有发送成功丢失,通过重试补偿
- 消息发送了,但是broker挂了,没有收到。通过ack机制确认。
解决方案
当我们在配置生产者的时候,我们会有一个配置文件,这个配置文件记录了broker集群的地址,以及鉴权,以及发送批次:
import com.ctrip.framework.apollo.ConfigService;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class BigDataKafkaConfig
private String innerServersProd = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.bootstrap-servers.prod", "").toString();
private String retries = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.producer.retries", "").toString();
private String batchSize = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.producer.batch-size", "").toString();
private String bufferMemory = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.producer.buffer-memory", "").toString();
private String innerServersTest = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.bootstrap-servers.test", "").toString();
private String ack = ConfigService.getConfig(MsgCommonConstant.TECH_BIGDATA_KAFKA).getProperty("spring.kafka.producer.ack", "").toString();
@Bean("ProducerFactoryTest") //生产者工厂配置
public ProducerFactory<String, String> producerFactoryTest(String env)
return new DefaultKafkaProducerFactory<>(senderProps(env));
@Bean("ProducerFactoryProd") //生产者工厂配置
public ProducerFactory<String, String> producerFactoryProd(String env)
return new DefaultKafkaProducerFactory<>(senderProps(env));
/**
* 测试环境-发送kafka
*
* @return
*/
@Bean("bigDataKafkaTempletTest")
public KafkaTemplate<String, String> kafkaTemplateTest()
String env = "TEST";
return new KafkaTemplate<String, String>(producerFactoryTest(env));
/**
* 生产环境发送kafka
*
* @return
*/
@Bean("bigDataKafkaTempletProd")
public KafkaTemplate<String, String> kafkaTemplateProd()
String env = "PROD";
return new KafkaTemplate<String, String>(producerFactoryProd(env));
/**
* 生产者配置方法
* <p>
* 生产者有三个必选属性
* <p>
* 1.bootstrap.servers broker地址清单,清单不要包含所有的broker地址,
* 生产者会从给定的broker里查找到其他broker的信息。不过建议至少提供两个broker信息,一旦 其中一个宕机,生产者仍能能够连接到集群上。
* </p>
* <p>
* 2.key.serializer broker希望接收到的消息的键和值都是字节数组。 生产者用对应的类把键对象序列化成字节数组。
* </p>
* <p>
* 3.value.serializer 值得序列化方式
* </p>
*
* @return
*/
private Map<String, Object> senderProps(String env)
Map<String, Object> props = new HashMap<>();
if ("TEST".equals(env))
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, innerServersTest);
else
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, innerServersProd);
/**
* 当从broker接收到的是临时可恢复的异常时,生产者会向broker重发消息,但是不能无限
* 制重发,如果重发次数达到限制值,生产者将不会重试并返回错误。
* 通过retries属性设置。默认情况下生产者会在重试后等待100ms,可以通过 retries.backoff.ms属性进行修改
*/
props.put(ProducerConfig.RETRIES_CONFIG, retries);
/**
* 在考虑完成请求之前,生产者要求leader收到的确认数量。这可以控制发送记录的持久性。允许以下设置:
* <ul>
* <li>
* <code> acks = 0 </ code>如果设置为零,则生产者将不会等待来自服务器的任何确认。该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且
* <code>retries </ code>配置将不会生效(因为客户端通常不会知道任何故障)。为每条记录返回的偏移量始终设置为-1。
* <li> <code> acks = 1 </code>
* 这意味着leader会将记录写入其本地日志,但无需等待所有follower的完全确认即可做出回应。在这种情况下,
* 如果leader在确认记录后立即失败但在关注者复制之前,则记录将丢失。
* <li><code> acks = all </code>
* 这意味着leader将等待完整的同步副本集以确认记录。这保证了只要至少一个同步副本仍然存活,记录就不会丢失。这是最强有力的保证。
* 这相当于acks = -1设置
*/
props.put(ProducerConfig.ACKS_CONFIG, ack);
/**
* 当有多条消息要被发送到统一分区是,生产者会把他们放到统一批里。kafka通过批次的概念来 提高吞吐量,但是也会在增加延迟。
*/
// 以下配置当缓存数量达到16kb,就会触发网络请求,发送消息
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
// 每条消息在缓存中的最长时间,如果超过这个时间就会忽略batch.size的限制,由客户端立即将消息发送出去
//设置kafka消息大小,msg超出设定大小无法发送到kafka
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
其中我们有配置 acks 这个属性。这个ack表示broker的回执方式。发送者,可以根据broker回复确认收到后,来保证消息准确发送。
props.put(ProducerConfig.ACKS_CONFIG, ack);
ack包含三种情况:
-
ack = 0 ,生产者不确认消息,发完拉倒,此时重试参数无效,因为默认发送成功了。
-
ack = 1 , 生产者发送消息,只等leader写入成功就返回,follower是否同步成功不管。
-
ack = -1 或 all ,生产者发送消息,等leader 接收 且 follower 同步完 再返回,如果有异常或超时,就会重试。影响性能。
另外还有一个参数:retries,生产者发送失败重试次数。
props.put(ProducerConfig.RETRIES_CONFIG, retries);
综上,其实无疑就是要保证消息准确可触达,无疑就是重试 + 回执确认。
这里再补充一下 生产者写入的流程:
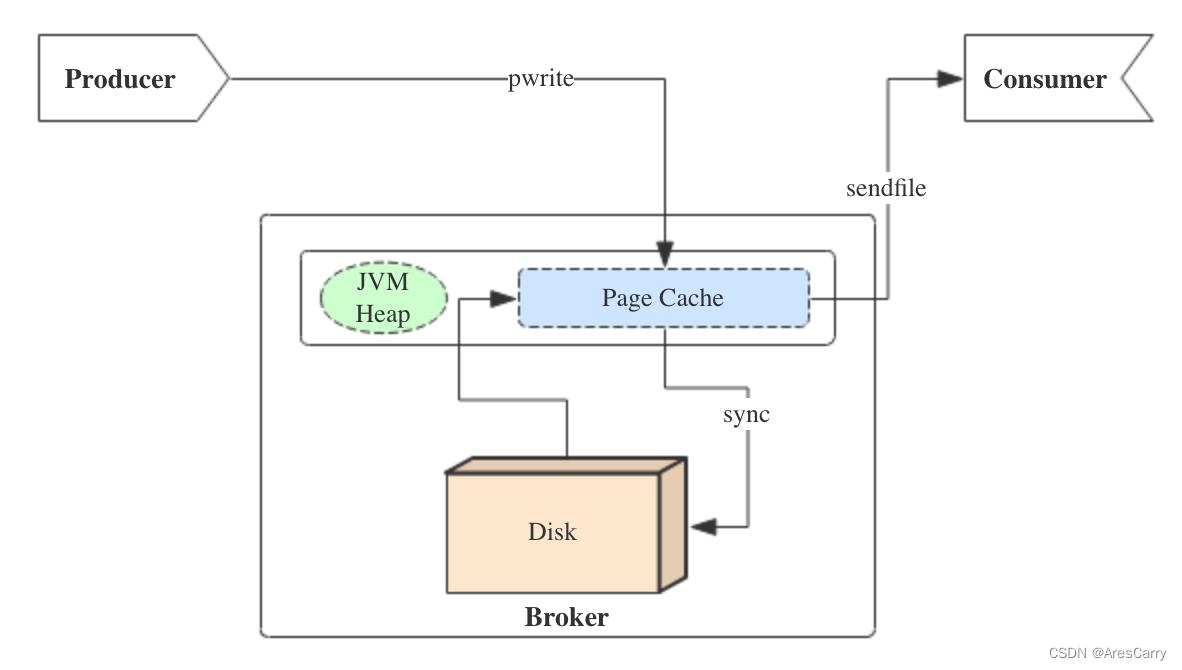
producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
图中没有画出来的还有leader与follower之间的同步,这与consumer是同理的:只要follower处在ISR中,就也能够通过零拷贝机制将数据从leader所在的broker page cache传输到follower所在的broker。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。这个结论俗称为“读写空中接力”。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
四、broker的消息丢失
丢失场景
- 消息没有收到
- broker挂掉了,无法接收
- broker接收到了消息,刷盘到硬盘之前,broker挂了
解释一下刷盘?
当消息到broker后,会先写入到 pageCache,然后系统根据配置的策略 ,异步批量刷盘到磁盘,持久化起来。
常用的刷盘策略有:
og.flush.interval.messages //多少条消息刷盘1次
log.flush.interval.ms //隔多长时间刷盘1次
log.flush.scheduler.interval.ms //周期性的刷盘。
解决方案
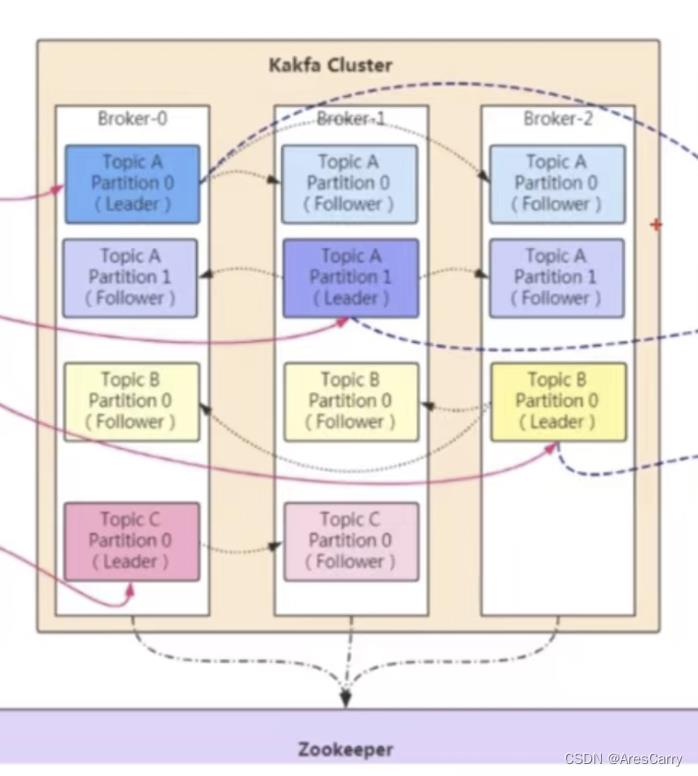
- 利用副本机制
前面我们讲到,broker中有ISR列表,OSR列表。其实就是partition的副本是否可用机制:每个partition都有对应的 1个leader + 多个 follower,leaer专门处理事务类型的请求,follower负责同步拉取leader的数据,也是从leader的pagecache中拉取的。
- 优化刷盘时间
可以通过调整刷盘策略,保证刷盘到磁盘。这样必定会降低性能。
五、小结
无疑还是从三大组件来考虑:
生产者 重试 + acks 确认回执
broker ISR副本机制 + 刷盘策略调整
消费者 一般不会有问题
以上是关于MQkafka——如何保证消息不丢失?如何解决?的主要内容,如果未能解决你的问题,请参考以下文章