大数据背景下外卖饮品数据分析系统设计与实现
Posted biyezuopinvip
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据背景下外卖饮品数据分析系统设计与实现相关的知识,希望对你有一定的参考价值。
资源下载地址:https://download.csdn.net/download/sheziqiong/85977021
资源下载地址:https://download.csdn.net/download/sheziqiong/85977021
摘 要
无论何时何地,信息都很重要。随着万维网的飞速发展,信息以指数的形式出现爆炸式增长。当传统的信息处理延伸到互联网领域时,往往需要下载分布在各个网站本地的信息进行进一步处理。但是,当收集到大量数据时,现有方法自然不适用,而现有方法在网上搜索信息时无法避免的问题之一是难以区分和选择令人眼花缭乱的信息.为了更高效、更准确地获取想要的信息,大量的时间信息是网络爬虫的绝佳手段。自定义规则让您挖掘特定网站的相关信息,筛选后得到更准确的信息。
本设计主要对外卖饮料数据进行数据挖掘和分析。我国外卖市场经过几十年的发展,外卖行业规模不断扩大。外卖行业的规模可以持续增长,外卖平台依托当今领先的外卖平台强大的大数据技术,依靠大数据分析和强大的运营优化和机器学习,在线完成所有环节。线下送货单。外卖平台是一个数据精细化的平台,每一个数据都是一个整体质量的纽带,同时每一个数据都反馈一个当下的问题,通过调整目标来提升质量不再是难事。
网络爬虫主要使用Python 脚本语言。使用Tkinter 库构建图形界面,操作简单。换句话说,单击该按钮会触发该功能。数据存储不使用SQL和NoSQL,网络爬虫的爬取结果直接存储在xlsx文件中,方便数据读取和数据可视化。使用matplolib库,用pandas库读取xlsx文件,通过读取获取的数据创建散点图或直方图,可以轻松观察数据分析。本项目是一款外卖饮料数据分析系统的设计与实现。最后,用户可以登录系统完成饮料数据分析的可视化。
关键词:网络爬虫;Python;数据挖掘;数据分析 ;外卖饮品
ABSTRACT
Information is important wherever and everywhere.With the rapid development of the World Wide Web, information has exploded in an exponential form.When the traditional information processing extends to the Internet field, it is often necessary to download the information distributed in each website for further processing.But, when large amounts of data are collected, existing methods naturally do not apply, and one of the problems that existing methods cannot avoid when searching for information online is the difficulty in distinguishing and choosing dazzling information. In order to obtain the desired information more efficiently and accurately, a large amount of time information is the perfect means for the web crawler.Custom rules allow you to mine the information about a particular site and filter it to get more accurate information.
This design mainly conducts data mining and analysis of external beverage sales data.After decades of development in China’s takeout market, the scale of the takeout industry continues to expand.The scale of the takeout industry can continue to grow. Relying on the powerful big data technology of today’s leading takeout platform, big data analysis, powerful operation optimization and machine learning, the takeout platform can complete all the links online.Offline delivery order.The delivery platform is a platform for data refinement, and each data is an overall quality link. At the same time, each data feeds back a current problem. It is no longer difficult to improve the quality by adjusting the target.
Web crawlers mainly use the Python scripting language.Building a graphical interface using the Tkinter library is easy to operate.In other words, clicking the button triggers the feature.Data storage does not use SQL and NoSQL, and crawling results of network crawlers are stored directly stored in the xlsx file to facilitate data reading and data visualization.Using the matplolib library, the xlsx file is read with the pandas library, and a scatter plot or histogram is created by reading the acquired data to easily observe the data analysis.This project is the design and implementation of a takeaway beverage data analysis system.Finally, users can log into the system to complete the visualization of the beverage data analysis.
Key words: web crawler; Python; data mining; data analysis; takeaway drinks
目录
第1章 绪论 1
1.1选题背景 1
1.1.1课题的国内外的研究现状 1
1.1.2课题研究的必要性 2
1.2课题研究的内容 3
第2章 开发软件平台介绍 4
2.1 软件平台 4
2.2 开发语言 4
2.2.1 Python 4
2.2.2 html+css+js 4
第3章 网络爬虫总体方案 7
3.1 系统组成 7
3.2 工作原理 7
第4章 模块化设计 8
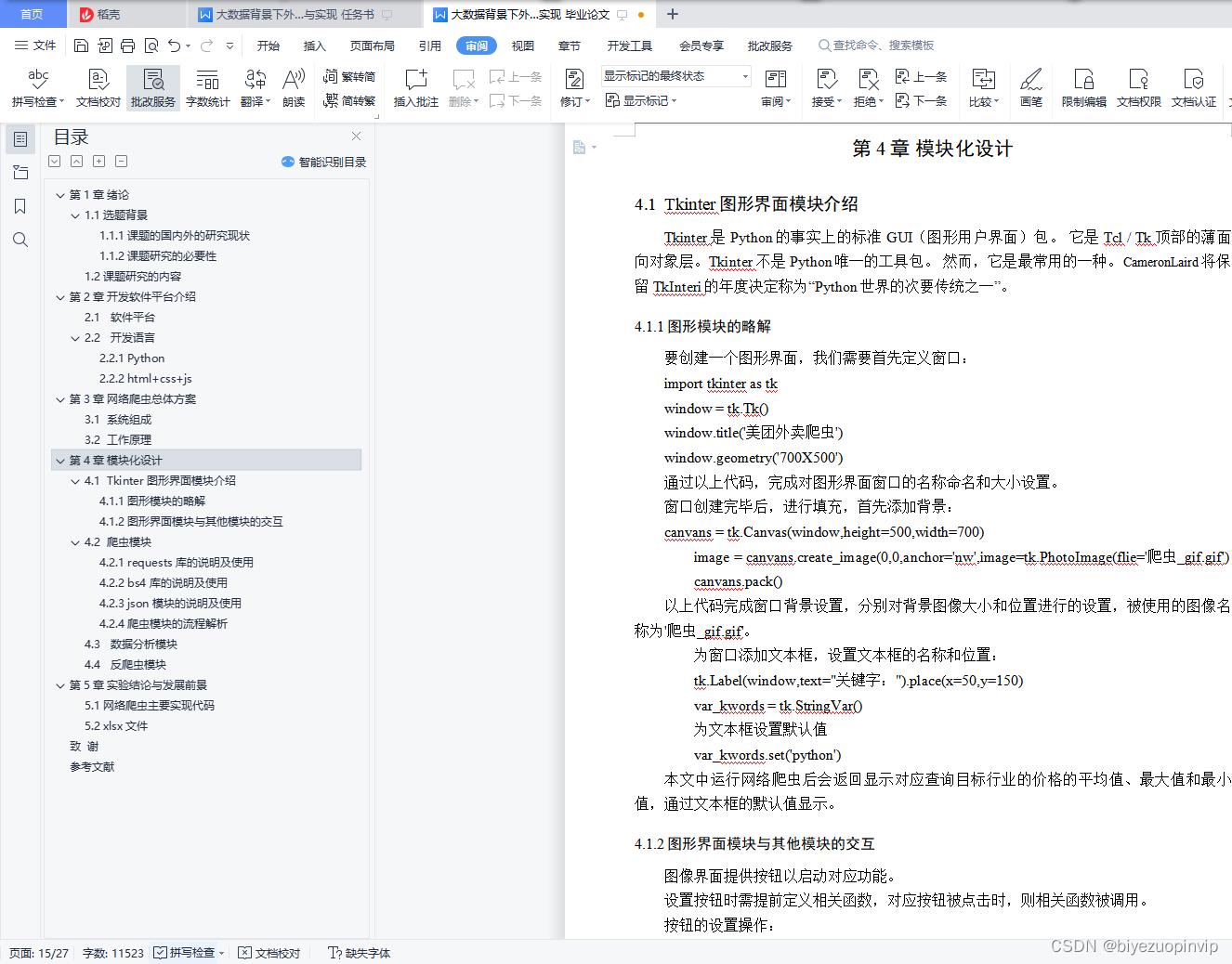
4.1 Tkinter图形界面模块介绍 8
4.1.1图形模块的略解 8
4.1.2图形界面模块与其他模块的交互 8
4.2 爬虫模块 10
4.2.1 requests库的说明及使用 10
4.2.2 bs4库的说明及使用 10
4.2.3 json模块的说明及使用 11
4.2.4爬虫模块的流程解析 11
4.3 数据分析模块 13
4.4 反爬虫模块 13
第5章 实验结论与发展前景 14
5.1网络爬虫主要实现代码 15
5.2 xlsx文件 15
致 谢 19
参考文献 20
本设计主要基于Pycharm的编程平台建设,整个系统由如下几个模块组成,具体如下:Tkinter图形界面模块,设置按钮,点击按钮触发对应功能;爬虫模块,编写爬虫文件,由Tkinter模块‘查询’按钮触发,对获取内容以xlsx保存;数据分析模块,读取对应的xlsx文件,让数据可视化,由Tkinter模块‘生成可视化图’按钮触发;反爬虫模块,用于存储多个浏览器型号和多个代理IP,当爬虫文件启动时,每次循环自动从反爬虫模块中调用函数获取随机得到浏览器型号和代理IP,本文爬取目标网站IP的封禁程度一般,因此代理IP选项被注释掉了(需要使用时将对应语句取消注释即可),即本文暂未使用代理IP。
部分代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 2 19:46:45 2022
@author: 24587
"""
from selenium import webdriver
import time
# from cnocr import CnOcr
class selenium_warm(object):
'''
将selenium爬虫的各个动作封装在这个类当中,但是不会进行数据处理
'''
def __init__(self,web_url):
'''最简单的打开页面'''
self.driver=webdriver.Edge()
self.driver.get(web_url)
def shift(self,page_num):
'''切换页面,page_num是想要跳转到的页面编号,从0开始编号'''
page=self.driver.window_handles
self.driver.switch_to.window(page[page_num])
def close(self):
self.driver.close()
def click(self,xpath,wait_time=0):
'''这里有两个坑,
第一,要先滚动到元素所在位置,让元素加载好,这样才能运行find_element
第二,元素加载好之后不一定可点击,要使其处于可点击状态,并等一会才能点击,所以有个wait_time参数
'''
item=self.driver.find_element_by_xpath(xpath)
# 使元素处于可点击状态
self.driver.execute_script("arguments[0].scrollIntoView();", item)
self.driver.execute_script("arguments[0].scrollIntoView(false);", item)
# 等待
time.sleep(wait_time)
item.click()
# self.driver.find_element_by_xpath(xpath).click()
def wait(self,time_num):
time.sleep(time_num)
def roll_bottom(self):
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
def get_text(self,xpath):
return self.driver.find_element_by_xpath(xpath).text
def get_elements(self,xpath):
return self.driver.find_elements_by_xpath(xpath)
def screen_shot(self,xpath,save_path):
item=self.driver.find_element_by_xpath(xpath)
# 截图的时候也要使其加载好才行
self.driver.execute_script("arguments[0].scrollIntoView();", item)
self.driver.execute_script("arguments[0].scrollIntoView(false);", item)
item.screenshot(save_path)
# def ocr(self,xpath,mid_img_save_path):
# '''目前返回的是未处理的识别结果,是一个列表
# 列表的每一项是识别出来的一个文字块,文字块也是一个列表,其中第一项是文字内容列表
# 第二项是置信率
# '''
# item=self.driver.find_element_by_xpath(xpath)
# self.driver.execute_script("arguments[0].scrollIntoView();", item)
# self.driver.execute_script("arguments[0].scrollIntoView(false);", item)
# item.screenshot(mid_img_save_path)
# ocr = CnOcr()
# res = ocr.ocr(mid_img_save_path)
# return res
def get_html(self):
html = self.driver.execute_script("return document.documentElement.outerHTML")
return html
def page_back(self):
self.driver.back()
if __name__ == "__main__":
warm=selenium_warm("https://www.icourse163.org/")
warm.roll_bottom()
text=warm.get_text('//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a')
print(text)
text=warm.ocr('//*[@id="app"]/div/div/div[1]/div[1]',"ocr.jpg")
print(text)
warm.screen_shot('//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a', "shot.jpg")
warm.click('//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a',0)



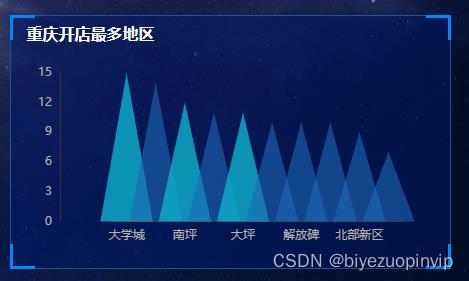
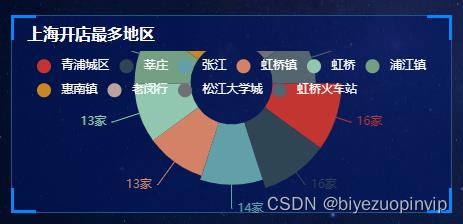
资源下载地址:https://download.csdn.net/download/sheziqiong/85977021
资源下载地址:https://download.csdn.net/download/sheziqiong/85977021
以上是关于大数据背景下外卖饮品数据分析系统设计与实现的主要内容,如果未能解决你的问题,请参考以下文章
简易WAP手机版外卖订餐管理系统的设计与实现论文.rar(论文+项目源码+数据库+视频录制+项目部署文件)
手机wap网站外卖订餐管理系统的设计与实现论文.rar(论文+项目源码)
基于Spring Boot的在线外卖系统的设计与实现 .rar(毕业论文+程序源码)