基于双语数据集搭建seq2seq模型
Posted aelum
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于双语数据集搭建seq2seq模型相关的知识,希望对你有一定的参考价值。
👨💻 作者:raelum
🗒️ 博客主页:https://raelum.blog.csdn.net
📢 如果这篇文章有帮助到你,可以关注❤️ + 点赞👍 + 收藏⭐ + 留言💬,这将是我创作的最大动力
目录
一、前言
本文将基于英-法数据集(源语言是英语,目标语言是法语)来构建seq2seq模型(不包含注意力机制)并进行训练和测试。
双语数据集的下载地址:Tab-delimited Bilingual Sentence Pairs。
数据集的前六行展示:
Go. Va ! CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #1158250 (Wittydev)
Go. Marche. CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #8090732 (Micsmithel)
Go. Bouge ! CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #9022935 (Micsmithel)
Hi. Salut ! CC-BY 2.0 (France) Attribution: tatoeba.org #538123 (CM) & #509819 (Aiji)
Hi. Salut. CC-BY 2.0 (France) Attribution: tatoeba.org #538123 (CM) & #4320462 (gillux)
Run! Cours ! CC-BY 2.0 (France) Attribution: tatoeba.org #906328 (papabear) & #906331 (sacredceltic)
导入本文所需要的所有包:
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import math
import string
import matplotlib.pyplot as plt
from tkinter import _flatten
from collections import Counter
二、数据预处理
2.1 数据清洗
我们需要先清除一些无关的信息,例如以 CC-BY... 开头的字样
首先读入数据并按行分开
with open('fra.txt', encoding='utf-8') as f:
# 这里稍微多此一举了下,之所以用\\t重新连接是为了后面能够更高效地检查字符
content = ['\\t'.join(line.strip().split('\\t')[:-1]) for line in f.readlines()]
print(content[:5])
# ['Go.\\tVa !', 'Go.\\tMarche.', 'Go.\\tBouge !', 'Hi.\\tSalut !', 'Hi.\\tSalut.']
为剔除一些无关字符,我们需要查看这个数据集中所有可能的字符种类
print(set(''.join(content)) - set(string.ascii_letters) - set(string.digits)) # 作差集是因为排除掉普通字母和数字后方便我们观察
# 'É', 'ï', 'á', '-', '’', '\\xa0', 'Ô', ':', '…', 'À', 'œ', ' ', '°', 'º', 'ç', '‘', 'ê', ')', 'ö', 'û', '\\u2009', 'à', '»', '‽', '?', 'è', '/', '"', "'", 'â', '«', '\\xad', 'Â', '!', 'î', '%', ',', 'Ê', '\\u202f', '.', '(', '&', 'ù', 'ë', 'ô', '\\u200b', '+', ';', 'é', '—', 'Ç', 'ü', '–', '\\t', '₂', '$', '€', 'ú'
从输出结果可以看出有一些字符是需要剔除的:\\u200b、\\xad,还有一些特殊空格:\\u2009、\\u202f 和 \\xa0 需要替换为普通空格。
此外,我们还需要将文本全部小写化,以及在单词和标点符号之间插入空格(前提是没有):
def data_cleaning(content):
for i in range(len(content)):
# 剔除无用字符并替换空格
special_chars = ['\\u200b', '\\xad', '\\u2009', '\\u202f', '\\xa0']
for j, char in enumerate(special_chars):
content[i] = content[i].replace(char, ' ' if j > 1 else '')
content[i] = content[i].lower() # 小写
# 在单词和标点符号之间插入空格
content[i] = ''.join([
' ' + char if j > 0 and char in ',.!?' and content[i][j - 1] != ' ' else char
for j, char in enumerate(content[i])
])
return content
效果:
cleaned_content = data_cleaning(content)
for i in range(10):
print(cleaned_content[i])
# go . va !
# go . marche .
# go . bouge !
# hi . salut !
# hi . salut .
# run ! cours !
# run ! courez !
# run ! prenez vos jambes à vos cous !
# run ! file !
# run ! filez !
2.2 词元化
此处我们进行单词级词元化(标点符号也算作一个词元)。
def tokenize(cleaned_content):
# 分别存储源语言和目标语言的词元
src_tokens, tgt_tokens = [], []
for line in cleaned_content:
pair = line.split('\\t')
src_tokens.append(pair[0].split(' '))
tgt_tokens.append(pair[1].split(' '))
return src_tokens, tgt_tokens
效果:
src_tokens, tgt_tokens = tokenize(data_cleaning(content))
print(src_tokens[:6])
# [['go', '.'], ['go', '.'], ['go', '.'], ['hi', '.'], ['hi', '.'], ['run', '!']]
print(tgt_tokens[:6])
# [['va', '!'], ['marche', '.'], ['bouge', '!'], ['salut', '!'], ['salut', '.'], ['cours', '!']]
2.3 建立词表
接下来我们需要为两种语言分别建立词表,目的是为了统计词元以及建立词元与索引之间的映射。
class Vocab:
def __init__(self, tokens, min_freq=0):
self.tokens = tokens # 传入的tokens是二维列表
self.min_freq = min_freq # 词元频率低于min_freq时会被视为未知次元:<unk>
self.token2idx = '<unk>': 0, '<pad>': 1, '<bos>': 2, '<eos>': 3 # 先存好特殊词元
self.token2idx.update(
token: idx + 4
for idx, (token, freq) in enumerate(
sorted(Counter(_flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
if freq >= self.min_freq
) # 将统计结果更新到词典中
self.idx2token = idx: token for token, idx in self.token2idx.items()
def __getitem__(self, tokens_or_indices):
# 我们需要让Vocab支持正反向查找和序列索引
# 单个索引情形
if isinstance(tokens_or_indices, (str, int)):
# 找不到指定的键值时返回未知词元(索引)
return self.token2idx.get(tokens_or_indices, 0) if isinstance(
tokens_or_indices, str) else self.idx2token.get(tokens_or_indices, '<unk>')
# 多个索引情形
elif isinstance(tokens_or_indices, (list, tuple)):
return [self.__getitem__(item) for item in tokens_or_indices]
else:
raise TypeError
def __len__(self):
return len(self.idx2token)
假设词元出现次数低于 2 2 2 就丢弃,相应的效果:
src_vocab, tgt_vocab = Vocab(src_tokens, min_freq=2), Vocab(tgt_tokens, min_freq=2)
print(len(src_vocab))
# 11170
print(len(tgt_vocab))
# 19565
print(src_vocab.token2idx) # 仅展示前10行
# '<unk>': 0,
# '<pad>': 1,
# '<bos>': 2,
# '<eos>': 3,
# '.': 4,
# 'i': 5,
# 'you': 6,
# 'to': 7,
# 'the': 8,
# '?': 9,
print(src_vocab['the'])
# 8
print(src_vocab[['i', 'to', 'the']])
# [5, 7, 8]
print(tgt_vocab[66])
# pense
print(tgt_vocab[[66, 137, 218]])
# ['pense', 'là', 'simplement']
print(src_vocab[[3, 'love', 7]])
# ['<eos>', 146, 'to']
print(src_vocab['aaabbbccc'])
# 0
print(src_vocab[999999999])
# <unk>
2.4 数据加载
我们知道,送给 nn.Embedding 层的数据通常是词元在词表中的索引,并且是批量送入的,形状为 (batch_size, seq_len)。而 src_tokens 中的数据都是以词元的形式存在并且句子不等长,因此我们需要做些处理以让其能够批量加载。
将词元转化为索引非常简单,这里我们需要关注的是如何让句子等长。通常是设定一个长度,超过这个长度的句子进行截断,不到这个长度的句子用 <pad> 进行填充。
def truncate_pad(line, seq_len):
# 该函数针对单个句子进行处理
# 传入的句子是词元形式
return line[:seq_len] if len(line) > seq_len else line + ['<pad>'] * (seq_len - len(line))
效果:
sentence = src_tokens[2000]
print(sentence)
# ['i', 'made', 'tea', '.']
print(truncate_pad(sentence, 10))
# ['i', 'made', 'tea', '.', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
print(truncate_pad(sentence, 2))
# ['i', 'made']
接下来,我们需要在 src_tokens 和 tgt_tokens 中的所有句子的末尾添加 <eos> 以代表句子的结束,然后再将它们处理成等长的形式,之后将其中的词元转化为其在词表中的索引,最后以张量的形式返回。
这些操作仅需一行代码即可完成:
def build_data(tokens, vocab, seq_len):
return torch.tensor([vocab[truncate_pad(line + ['<eos>'], seq_len)] for line in tokens])
效果(仅展示源语言中的前八个句子):
src_data = build_data(src_tokens, src_vocab, 10)
print(src_data[:8])
# tensor([[ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1],
# [ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1],
# [ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1],
# [2427, 4, 3, 1, 1, 1, 1, 1, 1, 1],
# [2427, 4, 3, 1, 1, 1, 1, 1, 1, 1],
# [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1],
# [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1],
# [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1]])
2.5 构建数据集
经过计算可知,源语言中句子的最大长度为 51 51 51,目标语言中句子的最大长度为 59 59 59,我们选择 45 45 45 (大约为最大长度的 80 % ∼ 90 % 80\\%\\sim90\\% 80%∼90%)作为阈值进行截断或填充。
我们使用 TensorDataset 来构建数据集(不知道的读者可参考我的这篇文章)。为充分利用原有数据集不妨设训练集大小为
190
K
190\\textK
190K,测试集大小为
4
K
4\\textK
4K,并且两者没有交集。
# 参数设置
TRAIN_SIZE = 190000
TEST_SIZE = 4000
BATCH_SIZE = 512
SEQ_LEN = 45
# 将tokens转化成张量
src_data, tgt_data = build_data(src_tokens, src_vocab, SEQ_LEN), build_data(tgt_tokens, tgt_vocab, SEQ_LEN)
# 打乱数据以方便分割
indices = torch.randperm(len(src_data)) # 这样能够保证打乱后,句子是一一对应的关系
src_data, tgt_data = src_data[indices], tgt_data[indices]
# 划分出训练集和测试集(总数据量为194513)
src_train_data, src_test_data = src_data[:TRAIN_SIZE], src_data[-TEST_SIZE:]
tgt_train_data, tgt_test_data = tgt_data[:TRAIN_SIZE], tgt_data[-TEST_SIZE:]
train_data = TensorDataset(src_train_data, tgt_train_data)
test_data = TensorDataset(src_test_data, tgt_test_data)
# 设置DataLoader
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1)
三、模型搭建
3.1 Encoder-Decoder 架构
我们采用最简单的 Encoder-Decoder 架构(不包含注意力机制):
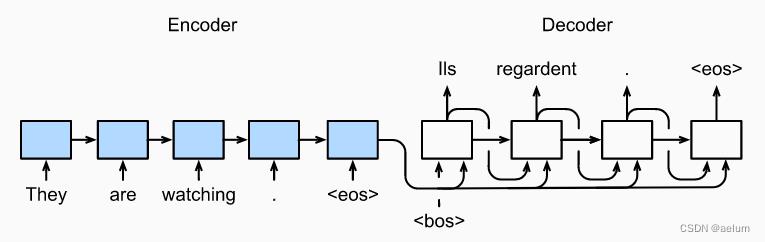
使用 Stacked GRU:
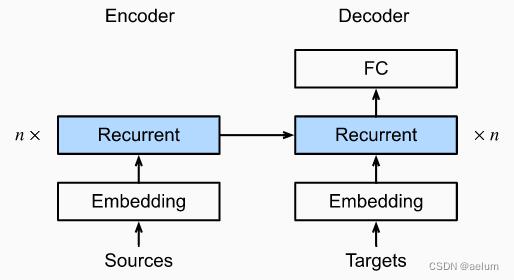
3.2 Encoder 部分
Encoder 的实现比较简单,不再过多介绍,具体请看注释
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.GRU(emb_size, hidden_size, num_layers=num_layers, dropout=dropout)
def forward(self, encoder_inputs):
# encoder_inputs 的初始形状为 (batch_size, seq_len)
# 形状的变化:(batch_size, seq_len) -> (batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)
encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)
output, h_n = self.rnn(encoder_inputs)
# h_n 的形状为 (num_layers, batch_size, hidden_size)
# 最后一个时刻最后一个隐层的输出的隐状态即为上下文向量,即h_n[-1],其形状为 (batch_size, hidden_size)
return h_n
3.3 Decoder 部分
Decoder 的实现要比 Encoder 略微复杂一点。
首先我们需要为 embedding 层指定 padding_idx,这样 <pad> 词元不会对梯度有任何贡献。
此外,我们将编码器在最后一个时刻的输出用作解码器的初始隐状态,编码器在最后一个时刻的最后一个隐藏层的输出用作上下文向量,它将和解码器的输入拼接起来作为 RNN 的输入。
具体请看注释。
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
# 务必设置padding_idx
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
# 之所以用cell是因为我们要一步一步地输出
# 之所以是emb_size + hidden_size是因为我们在每个时间步需要将当前的输入和编码器输出的上下文向量拼在一起
self.rnn = nn.GRU(emb_size + hidden_size, hidden_size, num_layers=num_layers, dropout=dropout)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, decoder_inputs, encoder_states):
# decoder_inputs 为目标序列偏移一位的结果
# decoder_inputs 的初始形状: (batch_size, seq_len)
# decoder_inputs 形状变化: (batch_size, seq_len) -> (batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)
decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2)
# encoder_states 为编码器在最后一个时刻所有隐藏层的隐状态,最后一个隐层的状态才是我们需要的context
context = encoder_states[-1]
# context 初始形状为 (batch_size, hidden_size),需要复制成 (seq_len, batch_size, hidden_size) 的形状才能连接
context = context.repeat(decoder_inputs.shape[0], 1, 1)
output, h_n = self.rnn(torch.cat((decoder_inputs, context), -1), encoder_states)
# logits 的形状为 (seq_len, batch_size, vocab_size)
logits = self.fc(output)
return logits, h_n
3.4 Seq2Seq 模型
只需将 Encoder 和 Decoder 拼接起来即可。
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_inputs, decoder_inputs):
return self.decoder(decoder_inputs, self.encoder(encoder_inputs))
四、模型训练
在训练阶段,我们不采用上一个时间步的输出作为下一个时间步的输入,而是将目标序列偏移一位作为输入,这被称为 Teacher-forcing。具体而言,设目标序列为(为简便起见不考虑 padding)
[ w 1 , w 2 , ⋯ , w T , <eos> ] (1) [w_1,w_2,\\cdots,w_T,\\text<eos>] \\tag1 [w1,w2,⋯,wT,<eos>](1)
我们将其偏移一位并在序列起始处加上 <bos> :
[
<bos>
,
w
1
,
w
2
,
⋯
,
w
T
]
(2)
[\\text<bos>,w_1,w_2,\\cdots,w_T]\\tag2
[<bos>,w1,w2,⋯,wT] 以上是关于基于双语数据集搭建seq2seq模型的主要内容,如果未能解决你的问题,请参考以下文章