Linux内核memcpy的不同实现
Posted smartvxworks
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内核memcpy的不同实现相关的知识,希望对你有一定的参考价值。
目录
1.概述
内存非cache区域拷贝速度很慢,严重影响了系统性能,因此采用多种方法进行优化,主要有对齐拷贝、批量拷贝、减少循环次数、NEON拷贝方法。
2.高级SIMD和浮点寄存器介绍
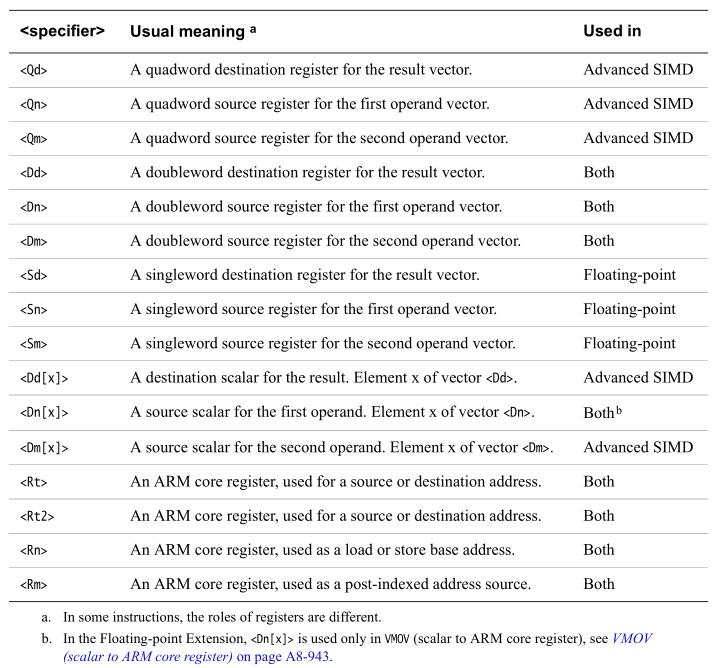
2.NEON指令
2.1 VLDR
VLDR指令可从内存中将数据加载到扩展寄存器中。
VLDR<c><q>.64 <Dd>, [<Rn> , #+/-<imm>] Encoding T1/A1, immediate form
VLDR<c><q>.64 <Dd>, <label> Encoding T1/A1, normal literal form
VLDR<c><q>.64 <Dd>, [PC, #+/-<imm>] Encoding T1/A1, alternative literal form
VLDR<c><q>.32 <Sd>, [<Rn> , #+/-<imm>] Encoding T2/A2, immediate form
VLDR<c><q>.32 <Sd>, <label> Encoding T2/A2, normal literal form
VLDR<c><q>.32 <Sd>, [PC, #+/-<imm>] Encoding T2/A2, alternative literal form <c>,<q>:是一个可选的条件代码。
.32,.64:是一个可选的数据大小说明符。如果是单精度VFP寄存器,则必须为32;否则必须为64。
Dd:双字(64位)加载的目标寄存器。对于NEON指令,它必须为D寄存器。对于VFP指令,它可以为D或S寄存器。
Sd:单字(32位)加载的目标寄存器。对于NEON指令,它必须为D寄存器。对于VFP指令,它可以为D或S寄存器。
Rn:存放要传送的基址的ARM寄存器,SP可使用。
+/-:偏移量相对于基地址的运算方式,+表示基地址和偏移量相加,-表示基地址和偏移量相减,+可以省略,#0和#-0生成不同的指令。
imm:是一个可选的数值表达式。在汇编时,该表达式的值必须为一个数字常数。 该值必须是4的倍数,并在0 - 1020的范围内。该值与基址相加得到用于传送的地址。
label:要加载数据项的标签。编译器自动计算指令的Align(PC, 4)值到此标签的偏移量。允许的值是4的倍数,在-1020到1020的范围内。
2.2 VLDM
VLDM指令可以将连续内存地址中的数据加载到扩展寄存器中。
VLDM<mode><c><q>.<size> <Rn>!, <list>
<mode>:IA Increment After,连续地址的起始地址在Rn寄存器中,先加载数据,然后Rn寄存器中的地址在增大,这是缺省的方式,DB Decrement Before,连续地址的起始地址在Rn寄存器中,Rn寄存器中的地址先减小,再加载数据
<c>,<q>:是一个可选的条件代码。
<size>:是一个可选的数据大小说明符。取32或64,和<list>中寄存器的位宽一致。
Rn:存放要传送的基址的ARM寄存器,由ARM指令设置,SP可使用。
!:表示Rn寄存器中的内容变化时要将变化的值写入Rn寄存器中。
<list>:加载的扩展寄存器列表。至少包含一个寄存器,如果包含了64位寄存器,最多不超过16个寄存器。
2.3 VSTR
VSTR指令将扩展寄存器中的数据保存到内存中。
VSTR<c><q>.64 <Dd>, [<Rn>, #+/-<imm>] Encoding T1/A1
VSTR<c><q>.32 <Sd>, [<Rn>, #+/-<imm>] Encoding T2/A2
<c>,<q>:是一个可选的条件代码。
.32,.64:是一个可选的数据大小说明符。如果是单精度VFP寄存器,则必须为32;否则必须为64。
Dd:双字(64位)加载的目标寄存器。对于NEON指令,它必须为D寄存器。对于VFP指令,它可以为D或S寄存器。
Sd:但字(32位)加载的目标寄存器。对于NEON指令,它必须为D寄存器。对于VFP指令,它可以为D或S寄存器。
Rn:存放要传送的基址的ARM寄存器,SP可使用。
+/-:偏移量相对于基地址的运算方式,+表示基地址和偏移量相加,-表示基地址和偏移量相减,+可以省略,#0和#-0生成不同的指令。
imm:是一个可选的数值表达式。在汇编时,该表达式的值必须为一个数字常数。 该值必须是4的倍数,并在0 - 1020的范围内。该值与基址相加得到用于传送的地址。
2.4 VSTM
VSTM指令可将扩展寄存器列表中的数据保存到连续的内存中。
<mode>:IA Increment After,连续地址的起始地址在Rn寄存器中,先保存数据,然后Rn寄存器中的地址在增大,这是缺省的方式,DB Decrement Before,连续地址的起始地址在Rn寄存器中,Rn寄存器中的地址先减小,再保存数据
<c>,<q>:是一个可选的条件代码。
<size>:是一个可选的数据大小说明符。取32或64,和<list>中寄存器的位宽一致。
Rn:存放要传送的基址的ARM寄存器,由ARM指令设置,SP可使用。
!:表示Rn寄存器中的内容变化时要将变化的值写入Rn寄存器中。
<list>:保存的扩展寄存器列表。至少包含一个寄存器,如果包含了64位寄存器,最多不超过16个寄存器。
3.ARM架构程序调用寄存器使用规则
3.1.ARM寄存器使用规则
(1)子程序间通过寄存器R0-R3传递参数,被调用的子程序在返回前无须恢复寄存器R0-R3的内容,参数多余4个时,使用栈传递,参数入栈的顺序与参数顺序相反。
(2)在子程序中,使用寄存器R4-R11保存局部变量,如果子程序中使用了R4-R11的寄存器,则必须在使用之前保存这些寄存器,子程序返回之前恢复这些寄存器,在子程序中没有使用这些寄存器,则无须保存。
(3)寄存器R12用作子程序间的scratch寄存器,记作IP,在子程序间的链接代码段中常有这种规则。
(4)寄存器R13用作数据栈指针,记作SP。在子程序中,寄存器R13不能用作其它用途。
(5)寄存器R14用作连接寄存器,记作IR。用于保存子程序的返回地址,如果在子程序中保存了返回地址,寄存器R14可用于其他用途。
(6)寄存器R15是程序计数器,记作PC。不能用作其他用途。
3.2.NEON寄存器使用规则
(1)NEON S16-S31(D8-D15,Q4-Q7)寄存器在子程序中必须保存,S0-S15(D0-D7,Q4-Q7)和Q8-Q15在子程序中无须保存
3.3.子程序返回寄存器使用规则
(1)结果为一个32位整数时,可以通过寄存器R0返回。
(2)结果为一个64位整数时,可通过寄存器R0和R1返回,依次类推。
(3)结果为一个浮点数时,可以通过浮点运算部件的寄存器F0、D0或者S0来返回。
(4)结果为复合型的浮点数时,可以通过寄存器F0-Fn或者D0-Dn返回。
(5)对于位数更多的结果,需要内存来传递。
3.优化代码
PLD为arm预加载执行的宏定义,下面汇编编写的函数中都使用到了。
#if 1
#define PLD(code...) code
#else
#define PLD(code...)
#endif
3.1.memcpy_libc
memcpy_libc为libc的库函数memcpy。
3.2.memcpy_1
一次循环只拷贝一个字节,可用于对齐拷贝和非对齐拷贝。
void *memcpy_1(void *dest, const void *src, size_t count)
char *tmp = dest;
const char *s = src;
while (count--)
*tmp++ = *s++;
return dest;
3.3.memcpy_32
memcpy_32一次循环拷贝32字节,适用于32字节对齐拷贝。
@ void* memcpy_32(void*, const void*, size_t);
@ 声明符号为全局作用域
.global memcpy_32
@ 4字节对齐
.align 4
@ 声明memcpy_32类型为函数
.type memcpy_32, %function
memcpy_32:
@ r4-r12, lr寄存器入栈
push r4-r11, lr
@ memcpy的返回值为目标存储区域的首地址,即第一个参数值,将返回值保存到r3寄存器中
mov r3, r0
0:
@ 数据预取指令,会将数据提前加载到cache中
PLD( pld [r1, #128] )
@ r2为memcpy的第3个参数,表示拷贝多少个字节数,首先减去32,
@ s:决定指令的操作是否影响CPSR的值
subs r2, r2, #32
@ r1为memcpy的第2个参数,表示源数据的地址,将源地址中的数据加载到r4-r11寄存器中
@ 每加载一个寄存器,r1中的地址增加4,总共8个寄存器,共32字节数据
ldmia r1!, r4-r11
@ 将r4-r11中保存的源数据加载到r1寄存器指向的内存地址,每加载一个寄存器,r1指向的地址加4
stmia r0!, r4-r11
@stmia r0!, r8-r11
@ gt为条件码,带符号数大于,Z=0且N=V
bgt 0b
@ 函数退出时将返回值保存到r0中
mov r0, r3
pop r4-r11, pc
.type memcpy_32, %function
@函数体的大小,.-memcpy_32中的.代表当前指令的地址,
@即点.减去标号memcpy_32,标号代表当前指令的地址
.size memcpy_32, .-memcpy_32
3.4.memcpy_64
memcpy_64一次循环拷贝64字节,适用于64字节对齐拷贝。
@ void* memcpy_64(void*, const void*, size_t);
.global memcpy_64
.align 4
.type memcpy_64, %function
memcpy_64:
push r4-r11, lr
mov r3, r0
0:
PLD( pld [r1, #256] )
subs r2, r2, #64
ldmia r1!, r4-r11
PLD( pld [r1, #256] )
stmia r0!, r4-r7
stmia r0!, r8-r11
ldmia r1!, r4-r11
stmia r0!, r4-r7
stmia r0!, r8-r11
bgt 0b
mov r0, r3
pop r4-r11, pc
.type memcpy_64, %function
.size memcpy_64, .-memcpy_64
3.5.memcpy_gen
memcpy_gen是通用的内存拷贝函数,可根据源地址和目的地址是否对齐,采用不同的拷贝方法,适用于对齐和非对齐拷贝。此代码参考自Linux内核。
(1)判断拷贝的字节数是否小于4字节,若小于4字节,则直接进行单字节拷贝
(2)判断目的地址是否时按4字节对齐,若没有,则进入目的地址未对齐的处理逻辑
(3)判断源地址是否按4字节对齐,若没有,则进入源地址未对齐的处理逻辑
(4)若目的地址和源地址按4字节对齐,则进入目的地址和源地址对齐的处理逻辑
目的地址和源地址对齐的处理逻辑:
(1)若拷贝的字节数大于等于32字节,则将超过32字节的数据进行批量拷贝,每次拷贝32字节
(2)若剩下的数据小于32字节,则进行4字节拷贝
(3)若剩下的数据小于4字节,则进行单字节拷贝
目的地址未对齐的处理逻辑:
(1)先将未对齐的字节进行单字节拷贝,使目的地址按4字节对齐
(2)若剩余的数据小于4字节,则进行单字节拷贝
(3)此时若源地址也按4字节对齐,则进入目的地址和源地址对齐的处理逻辑
(4)若源地址未按4字节对齐,则进入源地址未对齐的处理逻辑
源地址未对齐的处理逻辑:
(1)将源地址中的数据加载的寄存器中,进行逻辑移位
(2)将低地址的源数据逻辑左移,移到寄存器的低位,将高地址的数据逻辑右移,移到寄存器的高位
(3)将两个寄存器的数据进行或操作,实现了低地址和高地址数据在寄存器中的拼接
(4)将拼接的数据加载到目的地址中
#define LDR1W_SHIFT 0
#define STR1W_SHIFT 0
#if __BYTE_ORDER == __BIG_ENDIAN
// 大端
#define lspull lsl
#define lspush lsr
#elif __BYTE_ORDER == __LITTLE_ENDIAN
// 小端,一般都是小端
#define lspull lsr
#define lspush lsl
#else
#error "unknow byte order"
#endif
.macro ldr1w ptr reg abort
ldr \\reg, [\\ptr], #4
.endm
.macro ldr4w ptr reg1 reg2 reg3 reg4 abort
ldmia \\ptr!, \\reg1, \\reg2, \\reg3, \\reg4
.endm
.macro ldr8w ptr reg1 reg2 reg3 reg4 reg5 reg6 reg7 reg8 abort
ldmia \\ptr!, \\reg1, \\reg2, \\reg3, \\reg4, \\reg5, \\reg6, \\reg7, \\reg8
.endm
.macro ldr1b ptr reg cond=al abort
ldr\\cond\\()b \\reg, [\\ptr], #1
.endm
.macro str1w ptr reg abort
str \\reg, [\\ptr], #4
.endm
.macro str8w ptr reg1 reg2 reg3 reg4 reg5 reg6 reg7 reg8 abort
stmia \\ptr!, \\reg1, \\reg2, \\reg3, \\reg4, \\reg5, \\reg6, \\reg7, \\reg8
.endm
.macro str1b ptr reg cond=al abort
str\\cond\\()b \\reg, [\\ptr], #1
.endm
.macro enter reg1 reg2
stmdb sp!, r0, \\reg1, \\reg2
.endm
.macro exit reg1 reg2
ldmfd sp!, r0, \\reg1, \\reg2
.endm
@ void* memcpy_gen(void*, const void*, size_t);
@ 声明符号为全局作用域
.global memcpy_gen
@ 4字节对齐
.align 4
@ 声明memcpy_gen类型为函数
.type memcpy_gen, %function
memcpy_gen:
@ 将r0 r4 lr寄存器保存到栈中,r0是函数的返回值
enter r4, lr
@ 拷贝的字节数减4并保存到r2中,运算结果影响CPSR中的标志位
subs r2, r2, #4
@ blt:带符号数小于
@ 如果拷贝的字节数小于4,则跳转到标号8处
blt 8f
@ r0保存的是目的地址,r0和3与,判断r0的低两位是否是0,不是0,则是未对齐的地址
@ s:决定指令的操作是否影响CPSR的值
ands ip, r0, #3 @ 测试目的地址是否是按4字节对齐
PLD( pld [r1, #0] )
bne 9f @ 目的地址没有按4字节对齐,则跳转到标号9处
ands ip, r1, #3 @ 测试源地址是否是按4字节对齐
bne 10f @ 源地址没有按4字节对齐,则跳转到标号10处
1: subs r2, r2, #(28)
stmfd sp!, r5 - r8
blt 5f
PLD( pld [r1, #0] )
2: subs r2, r2, #96
PLD( pld [r1, #28] )
blt 4f
PLD( pld [r1, #60] )
PLD( pld [r1, #92] )
3: PLD( pld [r1, #124] )
4: ldr8w r1, r3, r4, r5, r6, r7, r8, ip, lr, abort=20f
subs r2, r2, #32
str8w r0, r3, r4, r5, r6, r7, r8, ip, lr, abort=20f
bge 3b
cmn r2, #96
bge 4b
5: ands ip, r2, #28
rsb ip, ip, #32
#if LDR1W_SHIFT > 0
lsl ip, ip, #LDR1W_SHIFT
#endif
addne pc, pc, ip @ C is always clear here
b 7f
6:
@ .rept:重复定义伪操作, 格式如下:
@ .rept 重复次数
@ 数据定义
@ .endr 结束重复定义
@ 例如:
@ .rept 3
@ .byte 0x23
@ .endr
.rept (1 << LDR1W_SHIFT)
nop
.endr
ldr1w r1, r3, abort=20f
ldr1w r1, r4, abort=20f
ldr1w r1, r5, abort=20f
ldr1w r1, r6, abort=20f
ldr1w r1, r7, abort=20f
ldr1w r1, r8, abort=20f
ldr1w r1, lr, abort=20f
#if LDR1W_SHIFT < STR1W_SHIFT
lsl ip, ip, #STR1W_SHIFT - LDR1W_SHIFT
#elif LDR1W_SHIFT > STR1W_SHIFT
lsr ip, ip, #LDR1W_SHIFT - STR1W_SHIFT
#endif
add pc, pc, ip
nop
.rept (1 << STR1W_SHIFT)
nop
.endr
str1w r0, r3, abort=20f
str1w r0, r4, abort=20f
str1w r0, r5, abort=20f
str1w r0, r6, abort=20f
str1w r0, r7, abort=20f
str1w r0, r8, abort=20f
str1w r0, lr, abort=20f
7: ldmfd sp!, r5 - r8
8: @ 处理拷贝的字节数小于4字节,此时r2中的值为负数,可能取值为-1 -2 -3
@ lsl 逻辑左移,将r2左移31位保存带r2中
movs r2, r2, lsl #31
@ ne 不相等,Z=0,r2为-1或-3时拷贝数据
ldr1b r1, r3, ne, abort=21f
@ cs 无符号数大于等于,C=1
@ 对于包含移位操作的非加/减法运算指令,C中包含最后一次被溢出的位的数值
ldr1b r1, r4, cs, abort=21f
ldr1b r1, ip, cs, abort=21f
str1b r0, r3, ne, abort=21f
str1b r0, r4, cs, abort=21f
str1b r0, ip, cs, abort=21f
exit r4, pc
9: @ 处理目的地址未按4字节对齐的情况
@ rsb 逆向减法指令,等价于ip=4-ip,同时根据操作结果更新CPSR中相应的条件标志
@ 当rsb的运算结果为负数时,N=1,为正数或0时,N=0
@ 当rsb的运算结果符号位溢出时,V=1
rsb ip, ip, #4 @ 当地址不按4字节对齐的时候,ip的值取值可能为1、2、3
@ 对于cmp指令,Z=1表示进行比较的两个数大小相等
cmp ip, #2 @ cmp影响
@ gt:带符号数大于,Z=0且N=V
ldr1b r1, r3, gt, abort=21f @ ip为3时将数据加载到r3寄存器中,同时r1=r1+1
@ ge:带符号数大于等于,N=1且V=1或N=0且V=0
ldr1b r1, r4, ge, abort=21f @ ip为2时将数据加载到r4寄存器中,同时r1=r1+1
ldr1b r1, lr, abort=21f @ ip为1时将数据加载到lr寄存器中,同时r1=r1+1
str1b r0, r3, gt, abort=21f
str1b r0, r4, ge, abort=21f
subs r2, r2, ip @ 更新拷贝的字节数
str1b r0, lr, abort=21f
@ 带符号数小于,N=1且V=0或N=0且V=1
blt 8b
ands ip, r1, #3 @ 测试源地址是否是4字节对齐的情况
@ eq 相等,Z=1,r1中的地址已按4字节对齐,则跳转到标号1处,否则继续向下执行
beq 1b
10: @ 处理源地址未按4字节对齐的情况
@ bic指令用于清除操作数1的某些位,并把结果放置到目的寄存器中
@ 将r1的低2位清0
bic r1, r1, #3
@ ip保存了r1的低两位,源地址的低2位与2比较
cmp ip, #2
@ 无条件执行,将r1寄存器指向的4字节数据加载到lr寄存器中,拷贝完r1=r1+4
ldr1w r1, lr, abort=21f
@ eq 相等,Z=1
@ ip寄存器和2相等
beq 17f
@ gt:带符号数大于,Z=0且N=V
@ ip寄存器大于2
bgt 18f
.macro forward_copy_shift pull push
@ r2寄存器减去28
subs r2, r2, #28
@ 带符号数小于,N=1且V=0或N=0且V=1,r2小于28跳转到14处
blt 14f
11: @ 保存r5-r9寄存器,同时更新sp寄存器,fd:满递减
stmfd sp!, r5 - r9
PLD( pld [r1, #0] )
subs r2, r2, #96 @ r2减去96
PLD( pld [r1, #28] )
blt 13f @ 带符号数小于,N=1且V=0或N=0且V=1,r2小于96跳转到13处
PLD( pld [r1, #60] )
PLD( pld [r1, #92] )
12: PLD( pld [r1, #124] )
13: @ lspull(小端) = lsr:逻辑右移
@ lspush(小端) = lsr:逻辑左移
ldr4w r1, r4, r5, r6, r7, abort=19f
@ lr逻辑右移pull位并存储到r3寄存器中
mov r3, lr, lspull #\\pull
subs r2, r2, #32
ldr4w r1, r8, r9, ip, lr, abort=19f
@ r4逻辑左移push位,然后和r3或,最后将结果保存到r3中
@ 将r4的push位保存到r3的(32-push)位
orr r3, r3, r4, lspush #\\push
mov r4, r4, lspull #\\pull
orr r4, r4, r5, lspush #\\push
mov r5, r5, lspull #\\pull
orr r5, r5, r6, lspush #\\push
mov r6, r6, lspull #\\pull
orr r6, r6, r7, lspush #\\push
mov r7, r7, lspull #\\pull
orr r7, r7, r8, lspush #\\push
mov r8, r8, lspull #\\pull
orr r8, r8, r9, lspush #\\push
mov r9, r9, lspull #\\pull
orr r9, r9, ip, lspush #\\push
mov ip, ip, lspull #\\pull
orr ip, ip, lr, lspush #\\push
str8w r0, r3, r4, r5, r6, r7, r8, r9, ip, , abort=19f
bge 12b
cmn r2, #96
bge 13b
ldmfd sp!, r5 - r9
14: ands ip, r2, #28
beq 16f
15: mov r3, lr, lspull #\\pull
ldr1w r1, lr, abort=21f
subs ip, ip, #4
orr r3, r3, lr, lspush #\\push
str1w r0, r3, abort=21f
bgt 15b
16: sub r1, r1, #(\\push / 8)
b 8b
.endm
forward_copy_shift pull=8 push=24
17: forward_copy_shift pull=16 push=16
18: forward_copy_shift pull=24 push=8
.macro copy_abort_preamble
19: ldmfd sp!, r5 - r9
b 21f
20: ldmfd sp!, r5 - r8
21:
.endm
.macro copy_abort_end
ldmfd sp!, r4, pc
.endm
.type memcpy_gen, %function
@函数体的大小,.-memcpy_gen中的.代表当前指令的地址,
@即点.减去标号memcpy_gen,标号代表当前指令的地址
.size memcpy_gen, .-memcpy_gen
3.7.memcpy_neon_128
memcpy_neon_128使用NEON寄存器进行加速拷贝,一次拷贝128字节,适用于128字节的对齐拷贝。
@ void* memcpy_neon_128(void*, const void*, size_t);
@ 声明符号为全局作用域
.global memcpy_neon_128
@ 4字节对齐
.align 4
@ 声明memcpy_neno类型为函数
.type memcpy_neon_128, %function
memcpy_neon_128:
@ 保存neon寄存器
vpush.64 d8-d15
@ 保存返回值
mov r3, r0
0:
PLD( pld [r1, #512] )
subs r2, r2, #128
vldmia.64 r1!, d0-d15
vstmia.64 r0!, d0-d15
bgt 0b
@ 函数退出时将返回值保存到r0中
mov r0, r3
vpop.64 d8-d15
@ 将函数的返回地址保存搭配pc中,退出函数
mov pc, lr
.type memcpy_neon_128, %function
@函数体的大小,.-memcpy_neon_128中的.代表当前指令的地址,
@即点.减去标号memcpy_neon_128,标号代表当前指令的地址
.size memcpy_neon_128, .-memcpy_neon_128
3.速度测试
3.1.对齐拷贝测试(单位:MiB/s)
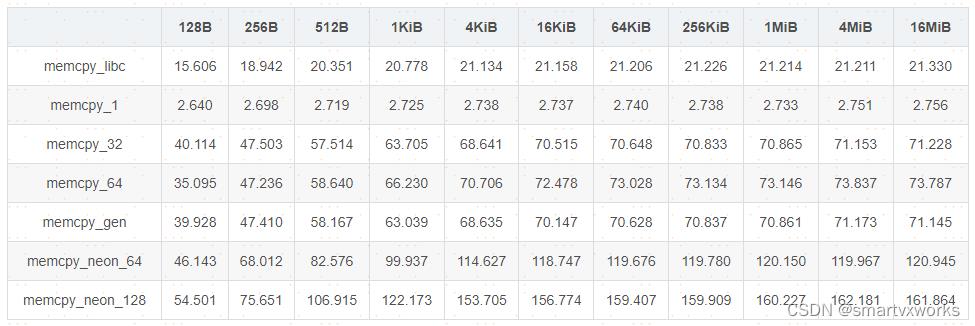
3.2.非对齐拷贝测试(单位:MiB/s)



4.影响拷贝速度的因素
(1)一次循环拷贝数据的字节数
(2)地址是否对齐
(3)pld预取对uncache拷贝影响很小
5.结论
(1)大批量数据拷贝时,应将源地址和目的地址按32字节、64字节或128字节对齐
(2)按32字节、64字节或128字节对齐的数据,使用neon寄存器进行批量拷贝,若无neon寄存器,则使用arm寄存器进行批量拷贝
(3)若拷贝的字节数小于要求的字节数,则使用通用的方法进行拷贝
(4)uncache区域拷贝,预加载pld指令对拷贝速度的提升有限
以上是关于Linux内核memcpy的不同实现的主要内容,如果未能解决你的问题,请参考以下文章