PyTorch实战用PyTorch实现基于神经网络的图像风格迁移
Posted 镰刀韭菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch实战用PyTorch实现基于神经网络的图像风格迁移相关的知识,希望对你有一定的参考价值。
用PyTorch实现基于神经网络的图像风格迁移
风格迁移,又称为风格转换。只需要给定原始图片,并选择艺术家的风格图片,就能把原始图片转换成具有相应艺术家风格的图片。图像的风格迁移始于2015年Gatys的论文“Image Style Transfer Using Convolutional Neural Networks”,所做的工作就是由一张内容图片和一张风格图片进行融合之后,得到经风格渲染之后的合成图片。示例如下:

1. 风格迁移原理介绍
风格迁移中有两类图片:一类是风格图片,通常是一些艺术家的作品,往往具有明显的艺术家风格,包括色彩、线条、轮廓等;另一类是内容图片,这些图片往往来自现实世界,如个人摄影等。利用风格迁移能够将内容图片转换成具有艺术家风格的图片。
Gatys等人提出的方法被称为Neural Style,但是他们在实现上过于复杂。Justin Johnson等提出了一种快速实现风格迁移的算法,称为Fast Neural Style。当用Fast Neural Style训练好一个风格的模型之后,通常只需要GPU运行几秒,就能生成对应的风格迁移效果。
Fast Neural Style 和Neural Style主要有以下两点区别:
(1)Fast Neural Style针对每一个风格图片训练一个模型,而后可以反复使用,进行快速风格迁移。Neural Style不需要专门训练模型,只需要从噪声中不断地调整图像的像素值,指导最后得到结构,速度较慢,需要十几分钟到几十分钟不等。
(2)普遍认为Neural Style生成的图片的效果会比Fast Neural Style的效果好。
这里主要介绍Fast Neural Style的实现。
要产生效果逼真的风格迁移图片,有两个要求:
- 要生成的图片在内容、细节上尽可能地与输入的内容图片相似;
- 要生成的图片在风格上尽可能地与风格图片相似。
相应地,定义两个损失content loss和style loss,分别用来衡量上述两个指标。
- content loss 比较常用的做法是采用逐像素计算差值,又称pixel-wise loss,追求生成的图片和原始图片逐像素的差值尽可能小。但是这种方法有诸多不合理之处,Justin提出了一种更好的计算content loss的方法,称为perceptual loss。不同于pixel-wise loss计算像素层面的差异,perceptual loss计算的是图像在更高层语义层次上的差异。使用预训练好的神经网络的高层作为图片的知觉特征,进而计算二者的差异值作为perceptual loss。
在进行风格迁移时,并不要求生成图片的像素和原始图片中的每一个像素都一样,追求的是生成图片和原图片具有相同的特征。
一般使用Gram矩阵来表示图像的风格特征。对于每一张图片,卷积层的输出形状为
C
×
H
×
W
C\\times H\\times W
C×H×W,C是卷积核的通道数,一般称为有C个卷积核,每个卷积核学习图像的不同特征。每一个卷积核输出的
H
×
W
H\\times W
H×W代表这张图像的一个feature map,可以认为是一张特殊的图像——原始彩色图像可以看作RGB三个feature map拼接组成的特殊feature map。通过计算每个feature map之间的相似性,就可以得到图像的风格特征。对于一个
C
×
H
×
W
C\\times H\\times W
C×H×W的feature maps
F
F
F,Gram Matrix的形状为
C
×
C
C\\times C
C×C,其第
i
,
j
i,j
i,j个元素
G
i
,
j
G_i,j
Gi,j的计算方式如下:
G
i
,
j
=
∑
k
F
i
k
F
j
k
G_i,j=\\sum_kF_ikF_jk
Gi,j=k∑FikFjk
其中
F
i
k
F_ik
Fik代表第i个feature map的第k个像素点。
需要注意的是:
- Gram Matrix的计算采用了累加的形式,抛弃了空间信息。
- Gram Matrix的结果与feature maps F的尺度无关,只与通道数有关。无论H,W的大小如何,最后Gram Matrix的形状都是C×C。
- 对于一个 C × H × W C\\times H\\times W C×H×W的feature maps,可以通过调整形状和矩阵乘法快速计算它的Gram Matrix,即先将F调整为 C × ( H W ) C\\times (HW) C×(HW)的二维矩阵,然后再计算 F ⋅ F T F\\cdot F^T F⋅FT,结果就是Gram Matrix。
实践证明利用Gram Matrix表征图像的风格特征在风格迁移、纹理合成等任务中表现十分出众。总之:
- 神经网络的高层输出可以作为图像的知觉特征描述
- 神经网络的高层输出的Gram Matrix可以作为图像的风格特征描述。
- 风格迁移的目标是使生成图片和原图片的知觉特征尽可能相似,并且和风格图片的风格特征尽可能地相似。
2. Fast Neural Style网络结构
Fast Neural Style专门涉及了一个网络用来进行风格迁移,输入原图片,网络将自动生成目标图片。如下图所示:
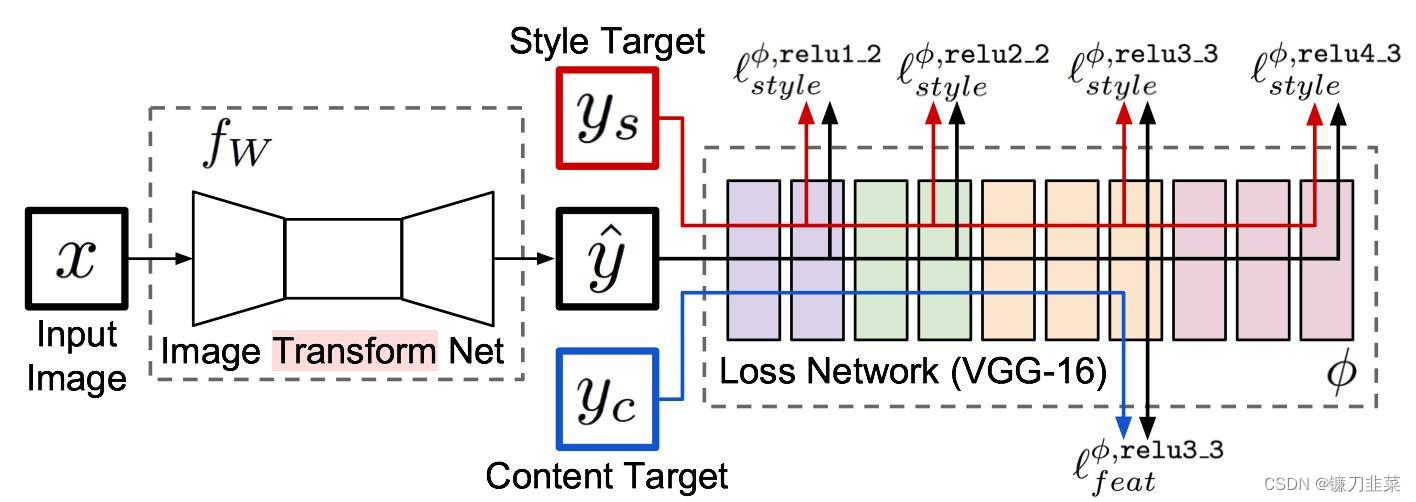
整个网络是由两部分组成:Image transformation network、 Loss Netwrok;
- Image Transformation network是一个deep residual conv netwrok,用来将输入图像(content image)直接transform为带有style的图像;
- 而loss network参数是fixed的,这里的loss network和 A Neural Algorithm of Artistic Style 中的网络结构一致,只是参数不做更新(neural style的weight也是常数,不同的是像素级loss和per loss的区别,neural style里面是更新像素,得到最后的合成后的照片),只用来做content loss 和style loss的计算,这个就是所谓的perceptual loss,
一个是生成图片的网络,就是图片中前面那个,主要用来生成图片,其后面的是一个VGG网络,主要是提取特征,其实就是用这些特征计算损失的,我们训练的时候只训练前面这个网络,后面的使用基于ImageNet训练好的模型,直接做特征提取。
如上图所示,
x
x
x是输入图像,在风格迁移任务中
y
c
=
x
y_c=x
yc=x,
y
s
y_s
ys是风格图片,Image Transform Net
f
W
f_W
fW是我们涉及的风格迁移网络,针对输入的图像
x
x
x,能够返回一张新的图像
y
^
\\haty
y^,
y
^
\\haty
y^在图像内容上与
y
c
y_c
yc相似,但在风格上与
y
s
y_s
ys相似。损失网络(loss network)不用训练,只是用来计算知觉特征和风格特征。损失网络采用ImageNet上预训练好的VGG-16。
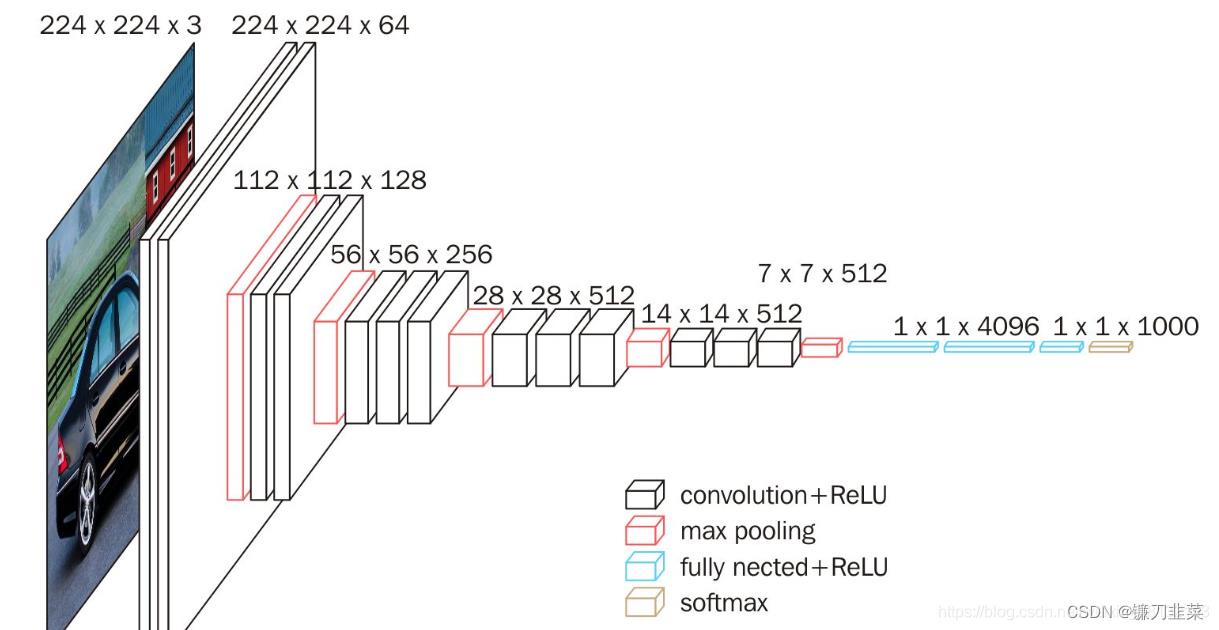
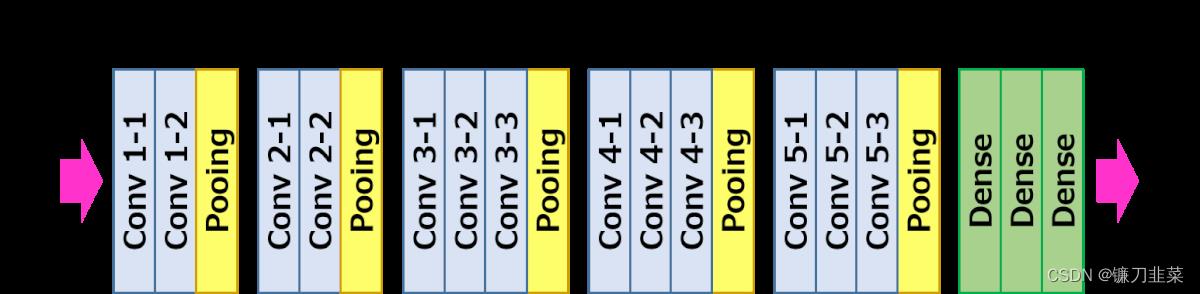
网络从左到右有5个卷积块,两个卷积块之间通过MaxPooling层区分,每个卷积块有2~3个卷积层,每一个卷积层后面都跟着一个ReLU激活曾。其中relu2_2表示第2个卷积块的第2个卷积层的激活层(ReLU)输出。
Fast Neural Style的训练步骤如下:
(1)输入一张图片x到
f
W
f_W
fW中,得到结果
y
^
\\haty
y^;
(2)将
y
^
\\haty
y^和
y
c
y_c
yc(其实就是x)输入到loss network(VGG-16)中,计算它在relu3_3的输出,并计算它们之间的均方误差作为content loss。
(3)将
y
^
\\haty
y^和
y
s
y_s
ys(风格图片)输入到loss network中,计算它在relu1_2,relu2_2,relu3_3和relu4_3的输出,再计算它们的Gram Matrix的均方误差作为style loss。
(4)两个损失相加,并反向传播。更新
f
W
f_W
fW的参数,固定loss network不动。
(5)跳回第一步,继续训练
f
W
f_W
fW。
先了解全卷积网络的结构。输入是图片,输出也是图片,对这种网络一般实现为一个全部都是卷积层而没有全连接层的网络结构。对于卷积层,当输入feature map(或者图片)的尺寸为
C
i
n
×
H
i
n
×
W
i
n
C_in\\times H_in\\times W_in
Cin×Hin×Win,卷积核有
C
o
u
t
C_out
Cout个,卷积核尺寸为
K
K
K,padding大小为
P
P
P、步长为
S
S
S时,输出的feature maps的形状为
C
o
u
t
×
H
o
u
t
×
W
o
u
t
C_out\\times H_out\\times W_out
Cout×Hout×Wout,其中
H
o
u
t
=
f
l
o
o
r
(
H
i
n
+
2
∗
P
−
K
)
/
S
+
1
H_out=floor(H_in+2\\ast P-K)/S+1
Hout=floor(Hin+2∗P−K)/S+1
W
o
u
t
=
f
l
o
o
r
(
W
i
n
+
2
∗
P
−
K
)
/
S
+
1
W_out=floor(W_in+2\\ast P-K)/S+1
Wout=floor(Win+2∗P−K)/S+1
如果输入图片的尺寸是3×256×256,第一层卷积的卷积核大小为3,padding为1,步长为2,通道数为128,那么输出的feature map形状,按照上述公式计算结果就是:
H
o
u
t
=
f
l
o
o
r
(
256
+
2
∗
1
−
3
)
/
2
+
1
=
128
H_out = floor(256+2\\ast 1-3)/2+1=128
Hout=floor(256+2∗1−3)/2+1=128
W
o
u
t
=
f
l
o
o
r
(
256
+
2
∗
1
−
3
)
/
2
+
1
=
128
W_out =floor(256+2\\ast 1-3)/2+1=128
Wout=以上是关于PyTorch实战用PyTorch实现基于神经网络的图像风格迁移的主要内容,如果未能解决你的问题,请参考以下文章