关于强化学习优化粒子群算法的论文解读
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于强化学习优化粒子群算法的论文解读相关的知识,希望对你有一定的参考价值。
文章目录
前言
本片博文主要讲解一下一篇关于使用DDPG神经网络去优化粒子群算法的一篇文章。文章名为:
《Reinforcement learning based parameters adaption method for particleswarm optimization》
TIPS:本文的顺序和那篇论文的是不一样的,我将挑选重点的来说明。
本文主要分四步:
- 背景知识 (快速上手)
- 相关研究(大致过一下)
- 具体如何使用强化学习
- 更多细节
- 思考与假设
版权
郑重提示:本文版权归本人所有,任何人不得抄袭,搬运,使用需征得本人同意!
2022.6.25
日期:2022.6.25 DAY 6
背景知识
传统PSO算法
1995年,受到鸟群觅食行为的规律性启发,James Kennedy和Russell Eberhart建立了一个简化算法模型,经过多年改进最终形成了粒子群优化算法(Particle Swarm Optimization, PSO) ,也可称为粒子群算法。
粒子群算法的思想源于对鸟群觅食行为的研究,鸟群通过集体的信息共享使群体找到最优的目的地。如下图,设想这样一个场景:鸟群在森林中随机搜索食物,它们想要找到食物量最多的位置。但是所有的鸟都不知道食物具体在哪个位置,只能感受到食物大概在哪个方向。每只鸟沿着自己判定的方向进行搜索,并在搜索的过程中记录自己曾经找到过食物且量最多的位置,同时所有的鸟都共享自己每一次发现食物的位置以及食物的量,这样鸟群就知道当前在哪个位置食物的量最多。在搜索的过程中每只鸟都会根据自己记忆中食物量最多的位置和当前鸟群记录的食物量最多的位置调整自己接下来搜索的方向。鸟群经过一段时间的搜索后就可以找到森林中哪个位置的食物量最多(全局最优解)。
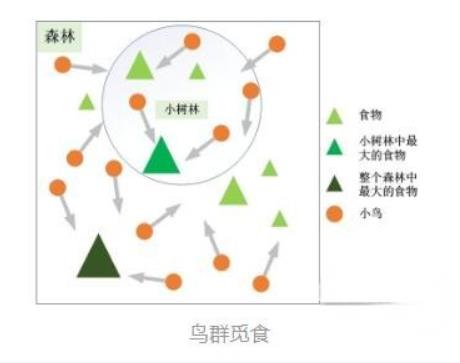
这里主要是通过两个方程来实现对粒子的控制,以此来实现让粒子实现全局的搜索。
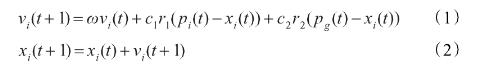
强化学习
强化学习是机器学习领域之一,受到行为心理学的启发,主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。
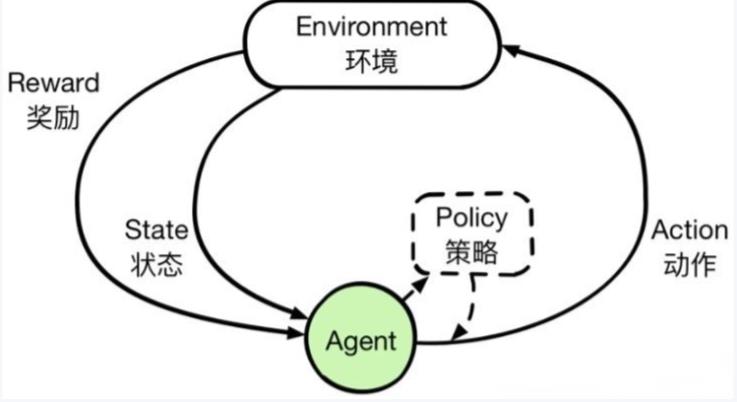
关键概念
关于强化学习这里面主要有几个概念。
智能体
强化学习的本体,作为学习者或者决策者。环境
强化学习智能体以外的一切,主要由状态集合组成。状态
一个表示环境的数据,状态集则是环境中所有可能的状态。动作
智能体可以做出的动作,动作集则是智能体可以做出的所有动作。奖励
智能体在执行一个动作后,获得的正/负反馈信号,奖励集则是智能体可以获得的所有反馈信息。策略
强化学习是从环境状态到动作的映射学习,称该映射关系为策略。通俗的理解,即智能体如何选择动作的思考过程称为策略。目标
智能体自动寻找在连续时间序列里的最优策略,而最优策略通常指最大化长期累积奖励。
因此,强化学习实际上是智能体在与环境进行交互的过程中,学会最佳决策序列。
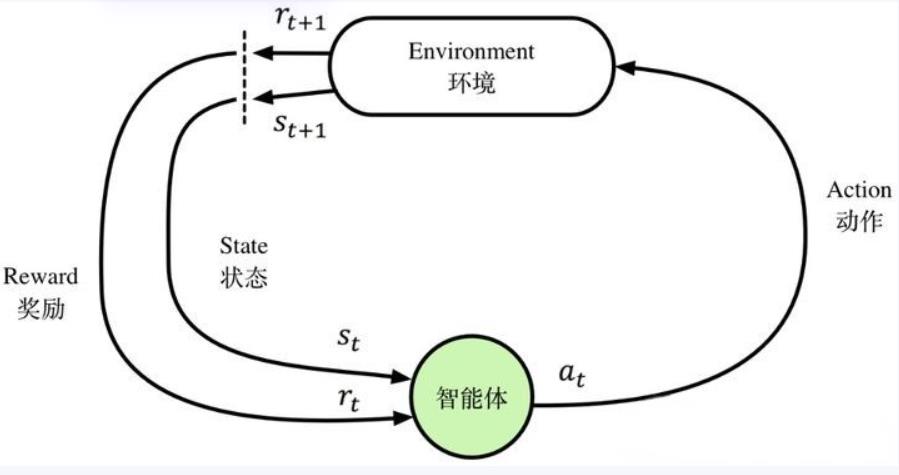
基本框架
强化学习主要由智能体和环境组成。由于智能体与环境的交互方式与生物跟环境的交互方式类似,因此可以认为强化学习是一套通用的学习框架,是通用人工智能算法的未来。
强化学习的基本框架如图所示,智能体通过状态、动作、奖励与环境进行交互。
在线学习(简述)
这里先做一个简述,后面我们会进行深入一点的探讨。
关于强化学习呢,还可以划分:在线学习和离线学习。在论文当中使用的DDPG,使用的是在线学习策略,所以本文也是简单说一下在线学习和离线学习。
这里以QLearn 为代表

离线学习(简述)
离线学习其实和在线学习类似,区别在于选择动作的时候,离线学习单纯按照价值最大的去现在。而在线学习的话还是有一定概率来选择并不是当前价值最大的动作。

实际核心代码的区别:
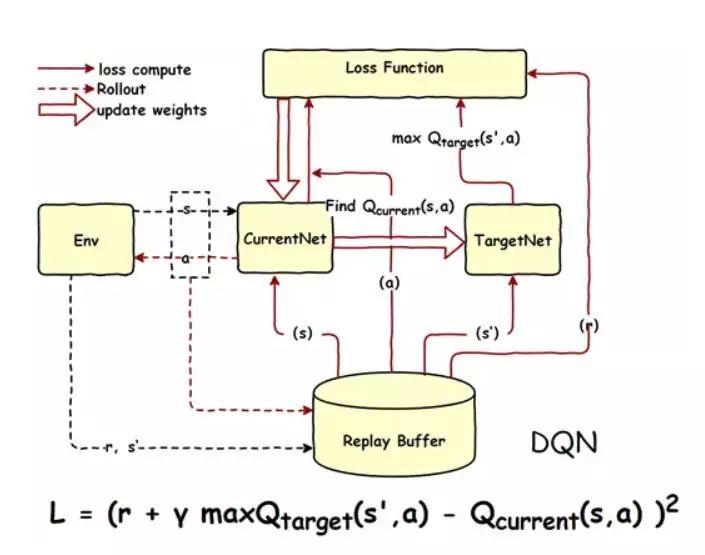
Q Learn
def QLearning():
QTable = Init(N_STATES, ACTIONS)
for ecpho in range(ECPHOS):
step_counter = 0
S = 0
# 是否回合结束
isWin = False
updateEnvShow(S, ecpho, step_counter)
while not isWin:
#选择行为
A = ChoseAction(S, QTable)
# 得到当前行为会得到的Reward,以及下一步的情况
S_, R = GetReward(S, A)
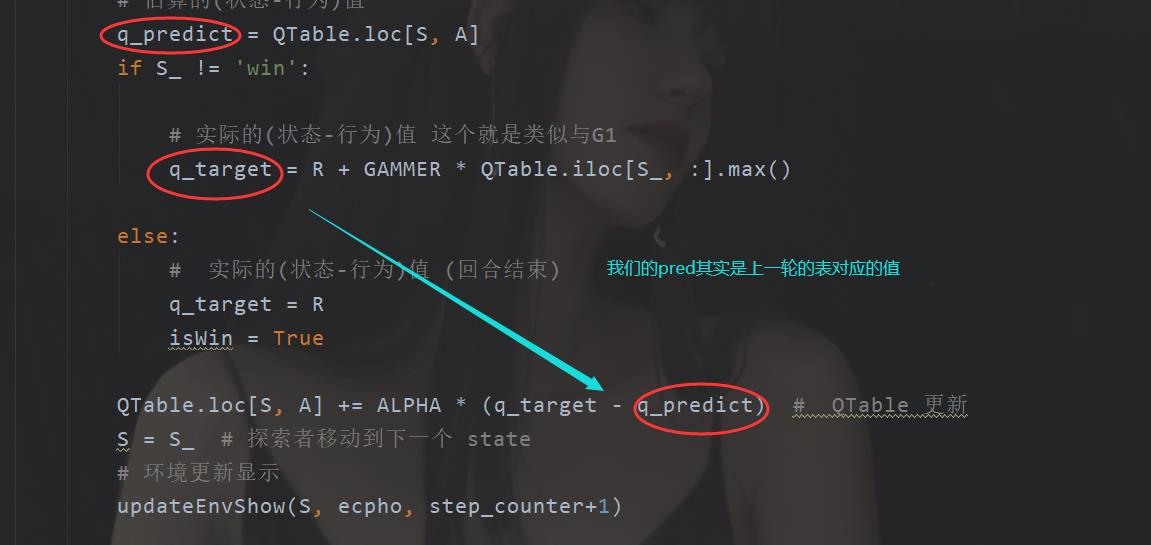
# 估算的(状态-行为)值
q_predict = QTable.loc[S, A]
if S_ != 'win':
# 实际的(状态-行为)值 这个就是类似与G1
q_target = R + GAMMER * QTable.iloc[S_, :].max()
else:
# 实际的(状态-行为)值 (回合结束)
q_target = R
isWin = True
QTable.loc[S, A] += ALPHA * (q_target - q_predict) # QTable 更新
S = S_ # 探索者移动到下一个 state
# 环境更新显示
updateEnvShow(S, ecpho, step_counter+1)
step_counter += 1
return QTable
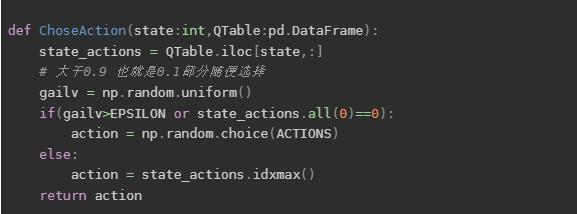
Sarsa 离线学习
def SARSA():
QTable = Init(N_STATES, ACTIONS)
for ecpho in range(ECPHOS):
step_counter = 0
S = 0
# 是否回合结束
isWin = False
updateEnvShow(S, ecpho, step_counter)
A = ChoseAction(S, QTable) # 先初始化选择行为
while not isWin:
S_, R = GetReward(S, A)
try:
A_ = ChoseAction(S_, QTable)
except:
# 这里说明已经到了终点(如果报错)
pass
q_predict = QTable.loc[S, A]
if S_ != 'win':
q_target = R + GAMMER * QTable.iloc[S_, :].max()
else:
q_target = R
isWin = True
QTable.loc[S, A] += ALPHA * (q_target - q_predict) # QTable 更新
S = S_
A = A_
updateEnvShow(S, ecpho, step_counter+1)
step_counter += 1
return QTable
对于离线学习而言,如果从上面的代码来改的话,那么只需要把动作选择函数的概率调整为1,并且先提前选择一个价值最大的动作即可。
无论是对于在线学习还是离线学习,其目的都是需要得到这样一张表:
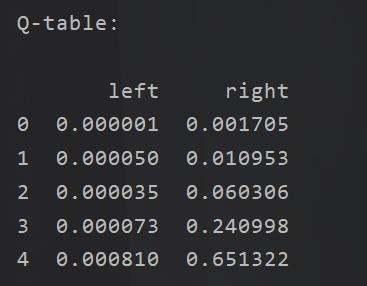
Qlearn
现在我们来好好的聊了里面的一些大体的细节。
马尔可夫决策
我们这里只讲大概几个和QLearn 关系比较紧密的东西。
里面比较详细的关于这个的是 概率论 这里面有提到。
这个是强化学习的一个理论支撑,类似于梯度下降,微分对神经网络
马尔科夫链
那么首先我们的第一点是马尔可夫链:这个东西就是一系列可能发生的状态。
例如:一个人刚起床,他有可能先刷牙,然后洗脸,然后上课。
或者这个人 起床,洗澡,刷牙,然后上课。
用一条链来表示就是:
刷牙-洗脸-上课
洗澡-刷牙-上课
策略

累计回报

这个主要是看到马尔可夫链,当前的状态对后面是有关联的。
值函数

他们之间的对应关系大致如下图:
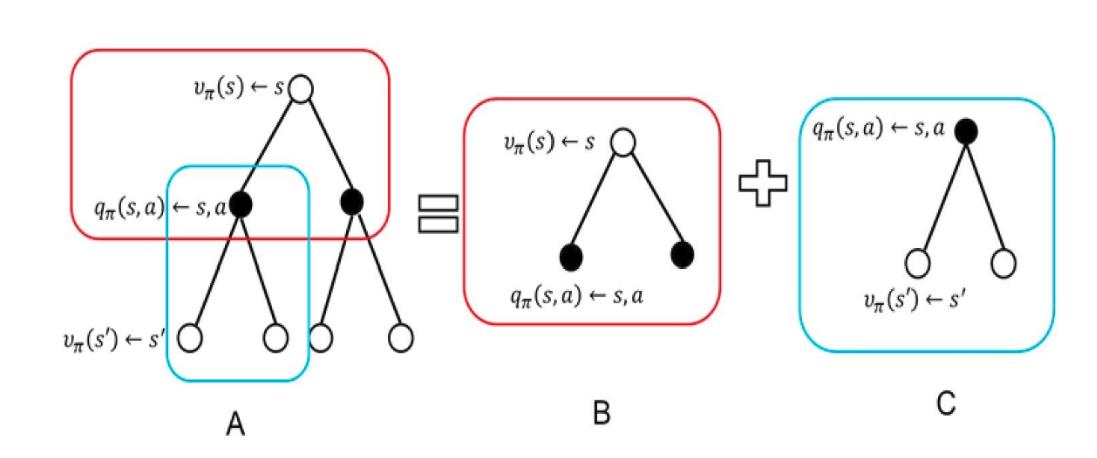
具体表现
强化学习就是数学原理是基于马尔可夫来的,那么在实际的表现当中的目的是为了求取一个表格Q。
这个表格Q,其实就是:
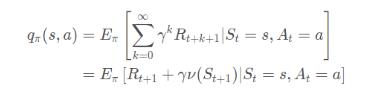
按照前面的粒子就是这个玩意:
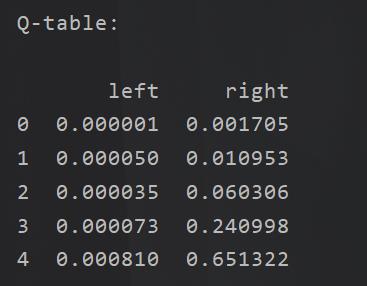
在我们实际上开始的时候Q表我们是不知道的,所以我们会有一个初始化,之后输入当前的状态和下一步的动作,会得到当前如果选择了这个动作,那么将得到的奖励,以及下一个状态,我们先通过q(s,a)可以得到。但是除此之外,由于我们实际上Q表一开始是随机的,所以是需要进行不断完善,收敛的,所以我们还需要不断更新我们的Q表。
所以在我们的实际代码里面还是有不一样的。
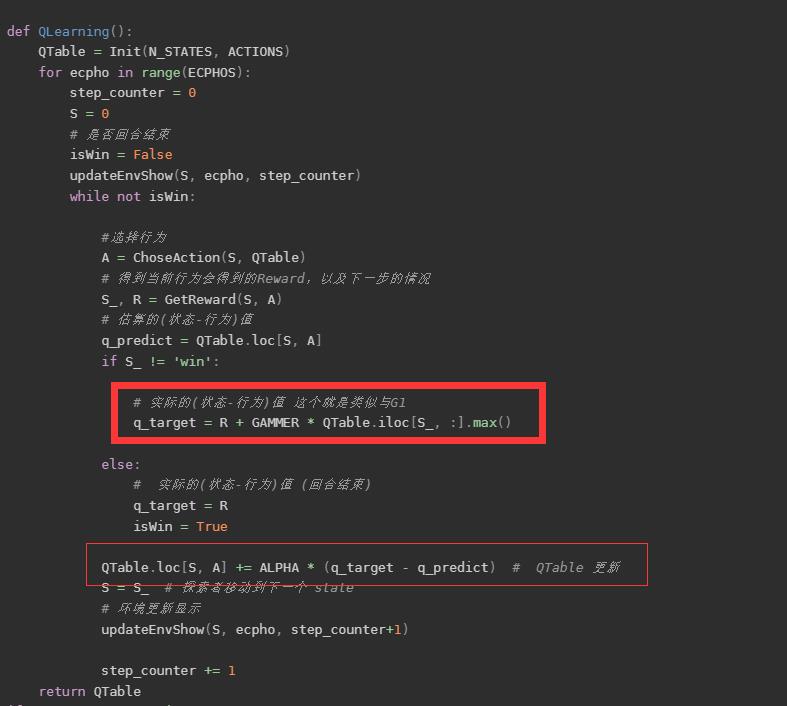
DQN神经网络
这个主要是因为论文中提到了DDPG,如果不说这个DQN 的话,这个DDPG很难说下去,那么论文也很难讲下去,这篇论文的难点在于知识面较广,实际算法其实不难。
DQN 其实和QLearn是一样的,区别在于,原来的Q表从一个表,一个有实体的表,变成了一个神经网络。目的是为了,通过神经网络去拟合那个Q表,因为在实际过程当中,如果需要将所有的状态和动作价值存起来是不可能的如果它的状态很多的话。所以需要一个神经网络来做拟合。
伪代码如下:

编码细节
在我们原来的时候,使用Q表
但是现在的话,由于我们是直接使用了这种“特殊的表”所以我们可以单独使用两个神经网络去分别代表实际和估计(预测)

而我们的损失函数就是让q_eval 和 q_target 变小
于是:

这里的loss_func 是nn.MSELoss()
DDPG
从上面的内容,你会发现,这个玩意和传统的Qlearn没太大区别只是很巧妙地使用了神经网络,最终还是要得到一个关于每一个动作的打分,然后去按照那个得分去选择分高的动作,换一句话说是,这个神经网络还是只能得到对应动作的价值,例如 上下左右,然后选价值最大的,如 上 这个动作。
但是在我实际的PSO问题当中,我想要的是一组解,也就是你直接告诉我w c1 c2 取哪些值?
所以现在直接使用DQN 就很难了,显然这玩意貌似只能选择出一个动作,而我的w c1 c2 不可能是一个动作,如果把他看作是一个动作的话,那么你将有 无穷个动作选择,假定有范围,那就是可数无穷个动作。
为了解决那个问题,于是有了DDGP,也就是我想要直接得到一组动作,你直接告诉我 w c1 c2取得哪些值?
怎么做,没错,再来一个神经网络。
具体怎么做,如下图:
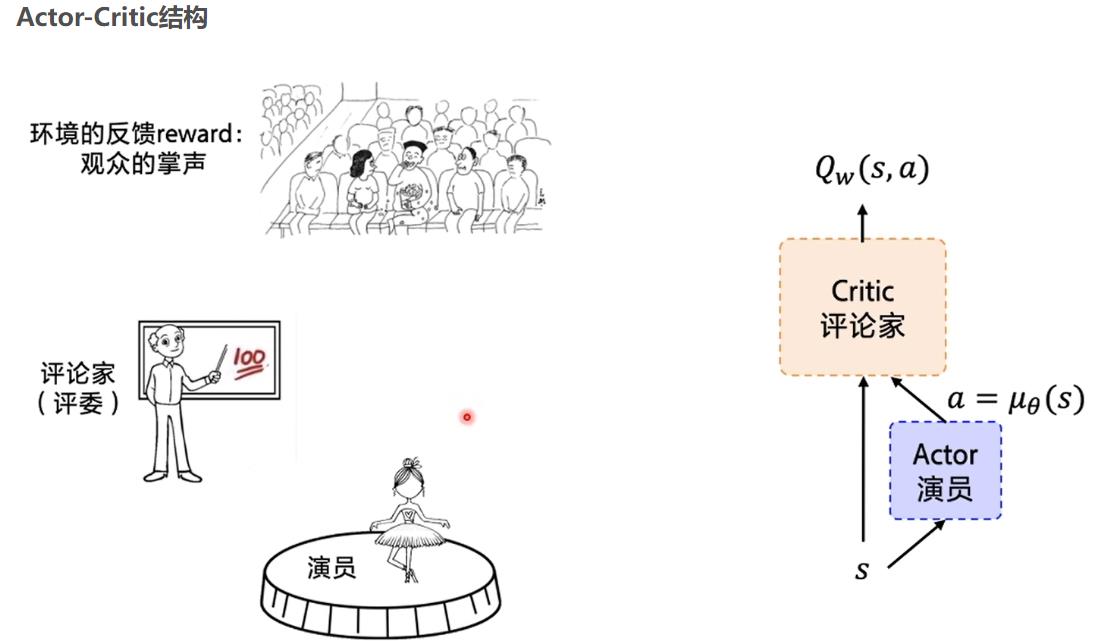
Actor 网络直接生成一个动作,然后 原来在DQN的那个网络在这里是Critic 网络 去评价,这个评价其实就是在DQN里面的那个网络,输入一个S,和 A 得到一个价值,现在这个价值变成了评分。
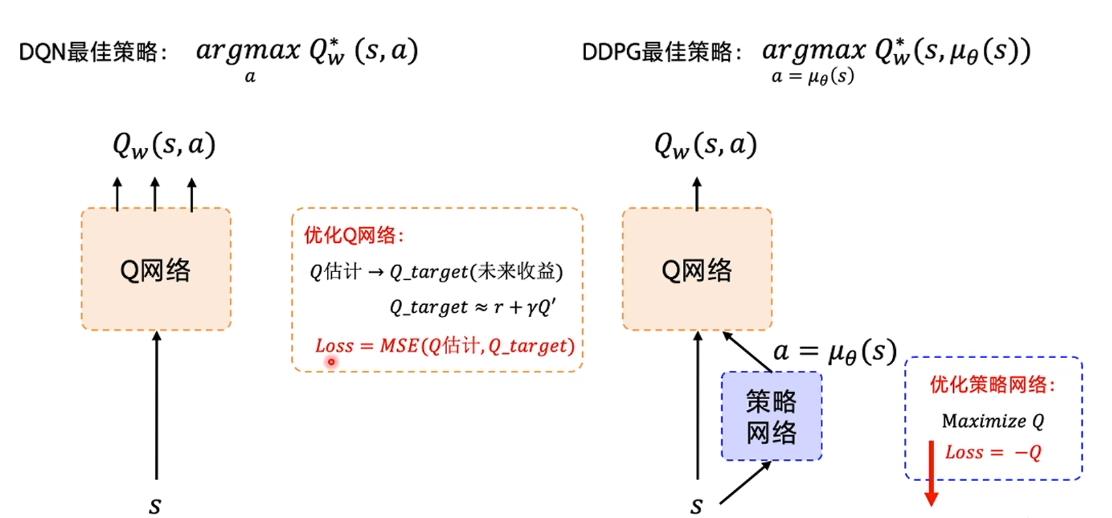
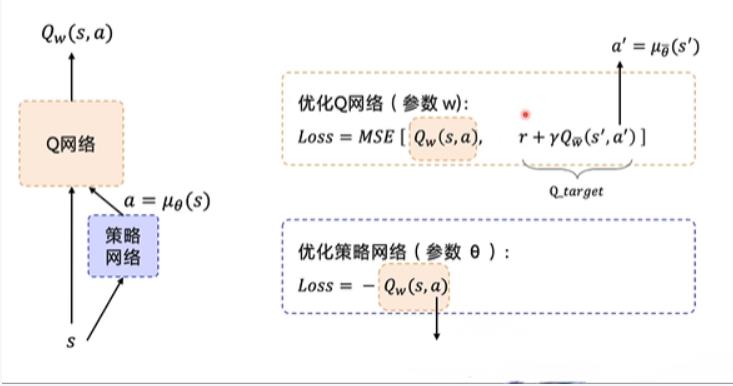
损失函数就是这样:
GAN对抗神经网络(拓展)
这个是我接下来要干的事情,基于GAN来优化PSO,因为从流程和建模的角度来看,使用DDPG是使用GAN区别不大,只是一个建模将直接通过适应值来,一个是可以通过参数本身进行建模。
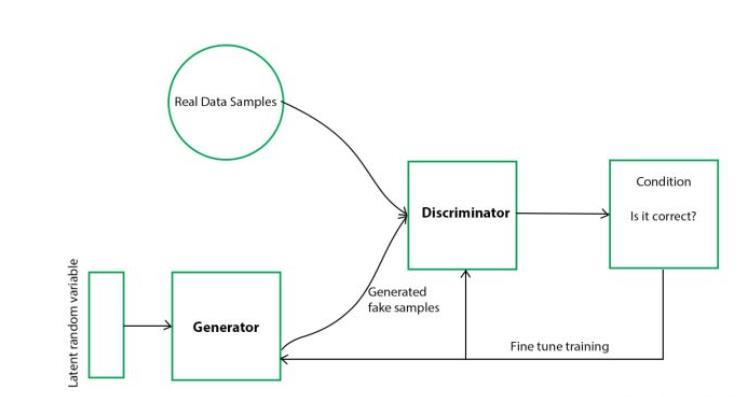
异同
现在我们再来对比一下DDPG神经网络。
首先Actor 在这里相当于Generator
评委还是评委,这两个网络都是要训练的网络。
这个判断器,就好比那个Cirtic,区别是啥?强化学习有个环境,这个DQN里面,或者DDPG里面那个评分怎么来的,还不是按照环境来给的,你把DDPG里面的Critic换成Q表一样跑,只是内存要炸,而且效果可能还要好,一方面精准记录,一方面只有一个网络。
而我们的GAN 是现有一个专家,这个专家不就也相当于环境嘛?
此外损失函数不同。
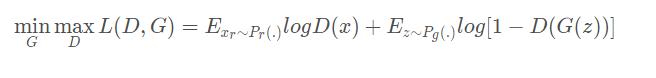
相关研究
这篇论文的话,有相当大的部分再绪论这个。我们这里简单挑选几个。
Linear strategies 线性策略
这个是我们经常使用的一个优化。

下面的一些描述都是相关论文有关于线性策略的一个优化

History based

有的论文在运行过程中将整个运行过程划分为许多小的过程。在每一个小过程中使用不同的参数或策略,并根据小阶段最后的算法性能来判断参数或策略是否足够好。足够好的策略或参数将在后续运行中被更多地选择。在论文[29]中,作者建立了一个参数存储器。每次运行时,将所有运行粒子分配不同的参数组,小段运行完成后,将一些性能较好的粒子使用的参数保存在参数存储器中。后续粒子选择的参数将趋向于接近参数记忆的平均值。在[30]中,作者根据以往一些优秀的粒子群算法设计了5种粒子群操作策略,并记录了每种策略的成功率。在初始状态,所有成功率设置为50%,然后在每个小过程中,根据过去成功率的权重,随机选择一个策略执行。有多少粒子被提升了,这是基于记忆的成功率更新。在论文[31]中,作者对原EPSo进行了改进,更新了设计的策略,将粒子群划分为多个子群,并对策略进行单独评估,进一步提高了算法的性能。
强化学习优化
关于其他的方法的话,实在是在论文里面提到的不少,但是都还不是主角,所以我们重点来到这里。
这个部分的话,还不是这篇论文当中所使用到的策略,还是在介绍相关的研究。
这里论文中给了一张表:

这里是其他使用强化学习的童鞋,他们使用这个强化学习输入输出得到的东西在PSO的运用。
如[40] 它输入的参数的当前位置,gbest,输出c1 c2 通过 gbest 设计奖励,是直接作用在单个粒子的,使用的算法是PG(DDPG)
然后下面是关于强化学习的介绍了,这个在我们的背景知识里面有提到。我感觉是至少要比论文更加详细的。
Comprehensive learning particle swarm optimizer(CLPSO)
这个也是一个对粒子群进行优化的一个算法,我个人觉得比较有意思,所以这里也是单独讲一下。
原文是这样的:

我这大概说一下人话就是:
首先是这个速度方程:
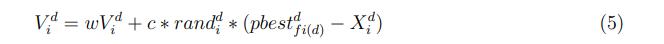
简单描述就是:对每一个粒子,在整个种群中随机选取两个粒子,比较两个粒子适应度并取较优的一个作为待选(对比pbest),然后依据交叉概率Pc来按维度将待选粒子与该粒子的历史最有进行交叉,以生成综合学习因子,即公式中的
。同时在迭代过程中记录粒子没有变化的迭代停滞次数(注意源代码中并未将变化的粒子停滞次数归零),当某个粒子的停滞次数大于阈值,则重新为其生成综合学习因子。
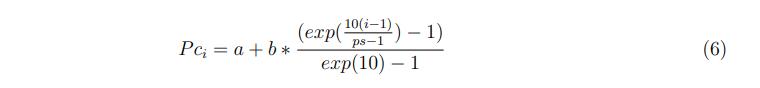
这里ps为种群大小,a = 0.05,b = 0.45。当粒子更新其一维速度时,会生成一个随机值[0,1],并与Pc进行比较。如果随机值大于Pc,该维度的粒子将遵循自己的pbest。否则,它会跟随另一个粒子的最佳值。CLPSo将采用锦标赛选择来选择目标粒子。此外,为了避免在错误的方向上浪费函数的计算,CLPSO将一定次数的计算定义为刷新间隙m。在粒子跟随目标粒子的过程中,将粒子停止改进的次数记录为flag,如果flag大于m,则粒子将再次采用竟赛选择的方式获得新的目标粒子。
那么这里就是相关研究了,我这里先粗略带过,因为重点还是这篇论文的实际运用。
具体如何使用强化学习
这个就是在论文当中如何具体使用了。
这里我们首先需要先看到它的一个神经网络结构。
网络结构
Actor 网络
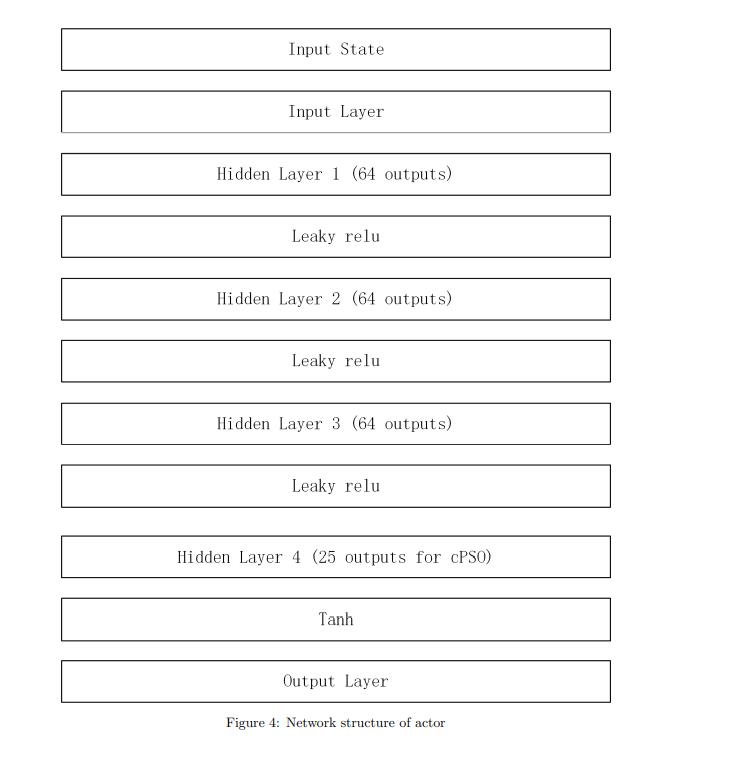
Critic 网络

在这里的话,我感觉这个论文有点问题不知道是不是写错了,它输出的(Actor)是25维度的,但是他后面的那个方程又说他是20个维度的,不知道是不是这个图搞错了(吐槽一波,这个图其实也是可以使用工具生成的,画的那么丑,还不准)
输入
首先是对Actor网络的输入,这个玩意的话是话是需要三个玩意的。
第一个是当前的迭代状态,也就是迭代了几轮。

不过这里都是做了归一化的,范围压缩在0-1之间
第二个就是当前粒子之间的一个离散度

很简单就是每一个粒子的每一个维度减去平均值,开根号,然后求和取平均。
其实这一部分我觉得他很大程度是按照:(HCLPSO)参考了一下的。
第三个就是,当前粒子的持续不再增长时间

这个很好理解。就是假设迭代200次,第50次的时候发现Gbest不变了,然后现在执行到100次了
这个算的话就是:100-50=50 50/200 = 0.25
最后是对这个输入做0-1归一化。
用的是这个玩意:

这里我稍微解释一下,就是我们这里要求是三个参数输入,但是这个还不够,所以呢,使用这个方法来进行感知和扩充,也就是例如计算出分散度是5 那么 就要得到 sin(51),sin(52),sin(54),sin(58),sin(5*16)
然后这样扩充之后得到的输入是15维。
然后这个划分5组的在论文这部分的开头和后面说了。


输入参数的映射
看到刚刚那一段话:

这也是我觉得那个图有问题的地方,他这里说了是20维度,结果图上给我说25。
这个映射就是这样的。分了5组嘛,对于第一组也就是编号0的就是这样的。
值得一提是下面的:
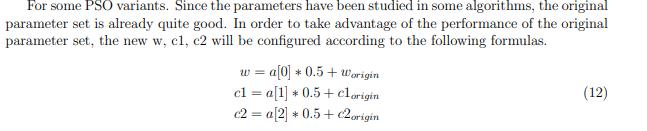
这个是人家用来做对比实验的时候用的,在别人的算法里面套强化学习,套他的策略。
不是他自己提出的算法。
之后是速度方程的更新:这里它借用了CLPSO。

这里他又改了,加了个C3,其实也就是利用了a[3]。
Critic的输入
这个网络其实就是和DQN那个网络训练是类似的。
然后这里的输入的是这个玩意
然后对输入的动作做了一个扰动
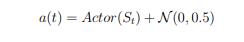
训练过程
环境的编写
这个对环境的编写就很简单了,在当前的状态下采用这个动作下,获取的环境奖励。这个奖励直接参考这个:
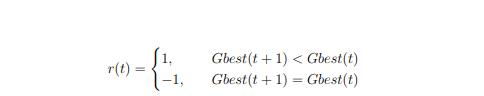
这里我再说一遍,这个哥们是没有使用多种群的,人家只是划分了一下组别,不同的组对应不同的参数,这个参数是一次性已经产生了的。
损失函数
这个没啥好说的,套DDPG的就完了。
这里我再重复一下就完了。
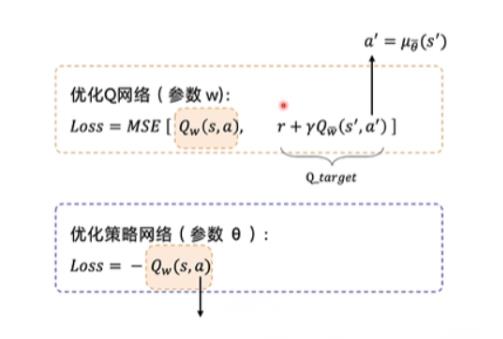
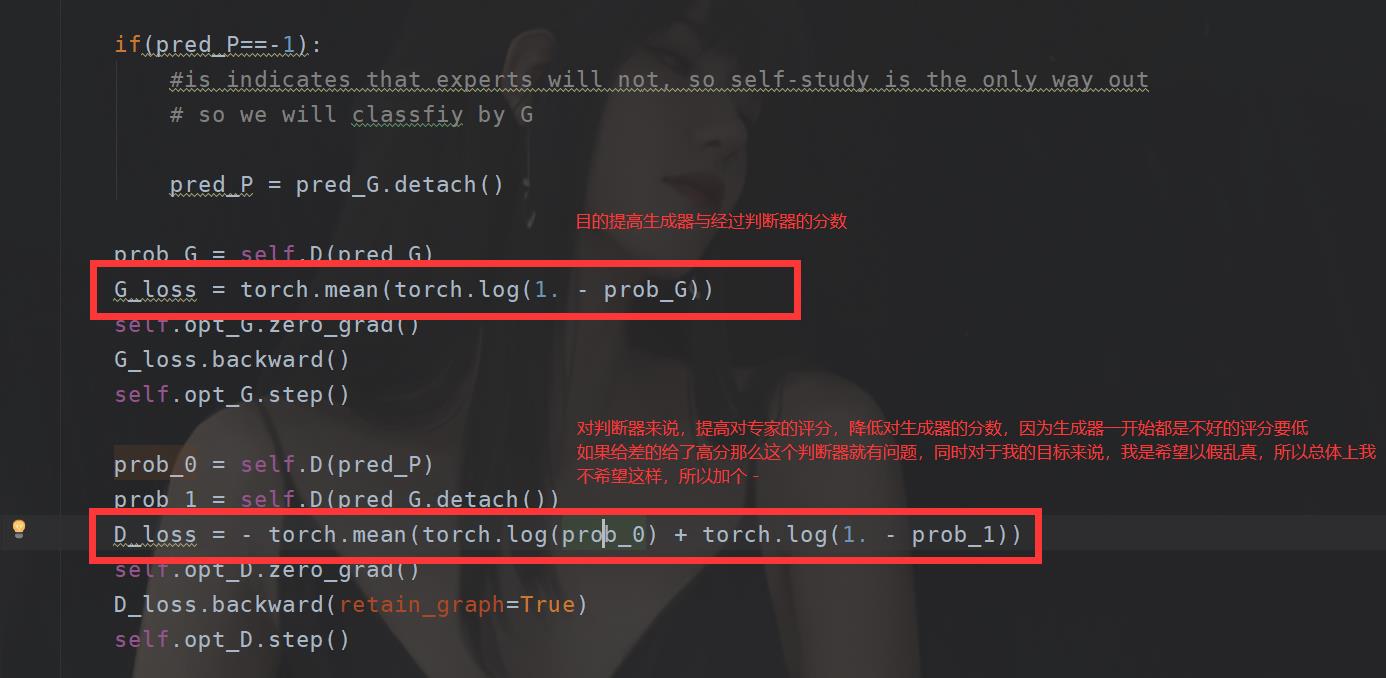
这里解释一下为啥那个Actor网络 loss = -Qw(s,a)
因为对于这个来说,我希望的是我的动作价值越大越好,如果Qw(s,a)的值越大,那么说明损失越小,反正损失越大。我的目的是让损失越来越小,所以一开始损失肯定是大的,我要让他越来越小所以,需要加个负号。
流程的话论文有描述:
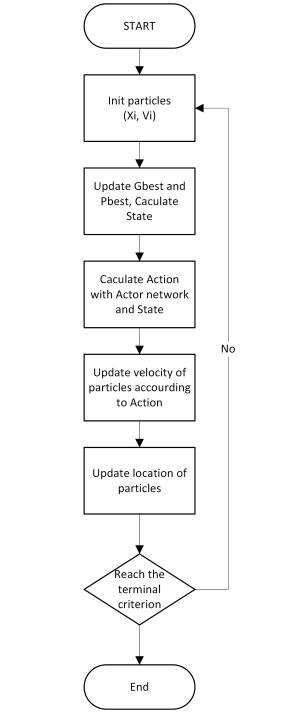
调用过程
这个就是训练完后如何使用这个东西了。

主要是按照原来的结构去直接调用Actor网络即可。
后面我会有具体的复现讲解。
更多细节
这部分其实就是后面的实验部分等等,这部分还是看具体论文描述吧。
思考与假设
这里我就打算把那个ENV换成“专家”,然后基于这个强化学习的框架去用GAN网络。
想怎么样,我感觉可能和强化学习类似,不过使用GAN建模的时候专家系统将会有点区别,它生成的将不是一个参数,如果套用这个算法框架的话,而是直接生成评分,这样的话建模方便,而且我觉得可以加快评委网络的收敛。不过损失函数还是类似的。不过这里可能已经在某种程度上属于强化学习了,只是对DQN那部分也就是cirtic网络和损失函数套用了GAN,至于Actor还是一样的。
不过如果对PSO算法或者进化算法的话,我感觉还是使用多策略,平衡开采和局部的关系才是不错的选择,在这片论文我觉得收获最大的还是CLSPO,这种类型的算法,以及这里提到的离散度的概念,我感觉很适合用来做感知器,也许可以把强化学习或者GAN网络用在神经网络最擅长的感知方面。
以上是关于关于强化学习优化粒子群算法的论文解读的主要内容,如果未能解决你的问题,请参考以下文章