论文笔记:Hierarchical Deep Reinforcement Learning:Integrating Temporal Abstraction and Intrinsic
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Hierarchical Deep Reinforcement Learning:Integrating Temporal Abstraction and Intrinsic相关的知识,希望对你有一定的参考价值。
2016 nips
1 abstract & introduction
在反馈稀疏的环境中学习目标导向的行为是强化学习算法面临的主要挑战。主要困难之一是探索不足,导致智能体无法学习稳健的策略。而具有内在动机的智能体可以为了自己的利益而探索新的行为,而不是直接解决外部目标。这种内在行为最终可以帮助智能体解决环境提出的任务。
这篇论文提出了分层 DQN (h-DQN),这是一个集成分层动作价值函数的框架,在不同的时间尺度上运行,具有目标驱动的内在动机深度强化学习。
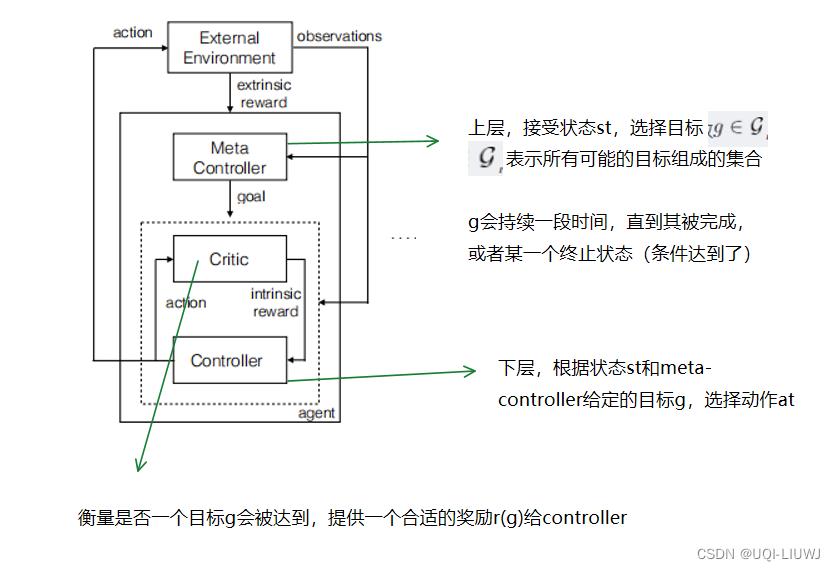
论文的模型分为两个层级:
- 顶级 q 值函数(meta-controller)学习内在目标的策略(类比成option级别的策略)
- 输入state,然后输出一个goal
- extrinsic reward
- 较低级别的函数(controller)学习原子动作的策略以满足给定目标(类比成option内部的策略)。
- 输入state和goal,来选择action
- ——>一直选择action,直到goal达到/episode终止
- ——>然后meta-controller然后再选择另外的一个goal,controller继续选择action
- intrinsic reward
- 还有一点需要注意的时,这篇paper的模型对于不同的option,没有使用不同的Q-function。他们把option视为Q-function的一个input,用统一的Q-function来计算和训练
- 这样会有两个好处:
- 在不同的option之前有共享的learning
- 模型在option的数量上是可扩展的
在这篇论文中,价值函数被表示为V(s,g),来反映状态s完成给定目标g的能力。他可以表示一个策略的回报,这个策略在达到目标g时结束。
一系列由V(s,g)决定的策略可以拼接在一起,形成最终的策略。【半马尔可夫性】
2 模型部分
对于一个马尔可夫决策过程,有状态s,工作a,状态转移方程
记外部奖励函数(extrinsic reward function)为
同时设置内部奖励函数
,智能体需要设置&训练策略
完成一系列的内部奖励g,以最大化累计外部奖励
为了学习每个
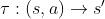
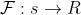
对于下层reward,论文用简单的0-1进行设置(1表示目标达成,0表示目标未达成)
于是controller的累计intrinsic reward函数为
,controller的目标是最大化这个reward【个人理解是越快完成goal越好,因为这样γ的衰减越少】注意这里的reward函数r是一个和goal相关的函数。
相似地,meta-controller的累计extrinsic reward函数为
,其中ft是在相邻两次goal选择之间的累计外部奖励
注意intrinsic和extrinsic的这个t是不一样的:intrinsic是每选择一个action衰减γ,extrinsic是每切换一个goal衰减γ

2.1 深度强化学习
根据上面,有如下的Q-value function
内层 controller:
其中g是这个智能体的目标,
是策略 【这里使用的是DQN,所以应该就是找最大的Q-value对应的action】

外层meta-controller
这里N表示了目标g持续的步数。在t+N的时候g完成,切换到目标g’

2.1.1 训练过程
使用神经网络Q1,Q2来近似Q1*和Q2*,记他们的损失函数分别为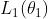 ,
,
将Q1和Q2的transition  分别记录到经验回放D1和D2中
分别记录到经验回放D1和D2中
记第i次训练迭代(epoch)的参数为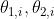 。
。
Q1的损失函数记为
TD loss+target network
Q2同理
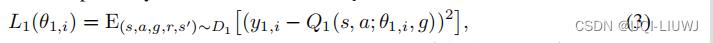
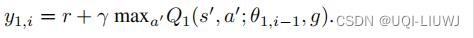

2.1.2 整体算法流程

3 实验部分
3.1 带延迟奖励的离散随机决策过程
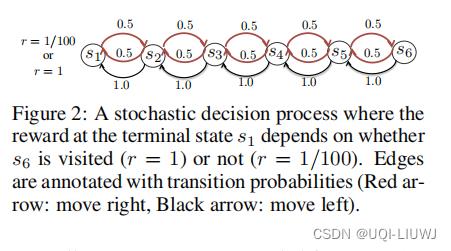
这里有六个可能的状态,agent始终从s2起步。s1是终止状态。当agent选择向左走时,铁定向左走,但是选择向右走时,只有50%的概率向右走,剩下50%的概率向左走
如果先到达s6再s1,那么奖励为1;如果没到达过s6,直接到达s1了,那么奖励为0.01.
论文将到达每一个状态作为候选的goal【确定目标集合】。
对每一个目标,当且仅当它到达了相对应的state,才会有正向的intrinsic reward.
3.1.1 结果
比较了论文的方法(由于这边只有六个状态,所以没有用DQN,直接Q-table)和Q-learning。
这里ε会在50,000步内慢慢从1降低到0.1.学习率为2.5*10^-4

从3a可以发现论文方法的有效性;从3b可以发现,随着training的进行,到达s3,s4,s5,s6的次数增加(表示的是上1000个episode中,每个episode平均到达相对应状态的次数)
3.2 ATARI 游戏
这是一张steam的截图,大致意思和论文描述的是一样的

游戏要求玩家在收集宝藏的同时导航探险家(红色)穿过几个房间。 为了通过门(在图的右上角和左上角),玩家必须首先拿起钥匙。 然后玩家必须爬下右边的梯子,然后向左移动到钥匙,导致在收到奖励(+100)收集钥匙之前执行很长的动作序列。
在此之后,导航到门并打开它会导致另一个奖励(+300)。
基本 DQN [16] 得分为 0,而即使是性能最好的系统 Gorila DQN [18],平均也只有 4.16 分。
3.2.1 架构
在这里,controller和meta-controller一开始都是CNN,来从原始的像素数据中学习表征

论文使用场景i中的实体来表征目标(“门”,“钥匙”)
在训练方法上,一开始论文设置meta-controller的ε为1(随即查找),然后训练controller。这相当于预训练controller,让他首先可以解决一部分的目标;然后再统一联合训练controller和meta-controller
3.2.2 结果
每张controller图的下表表示了时间的先后顺序。这也是联合训练的过程:
首先meta-controller定“钥匙”为目标,于是controller执行一些action,但是它到达了骷髅处(失败的termination state)【1,2,3】
于是meta-controller重新选择目标,这次选择“右边的梯子”,于是controller执行一些acton,完成了这个goal【4,5,6】
meta-controller再选择goal,这次选择的是“钥匙”,于是controller执行一些acton,完成了这个goal【7,8,9】
以此类推

以上是关于论文笔记:Hierarchical Deep Reinforcement Learning:Integrating Temporal Abstraction and Intrinsic的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记之:Deep Attributes Driven Multi-Camera Person Re-identification
论文笔记:FeUdal Networks for Hierarchical Reinforcement Learning
[论文阅读笔记] HARP Hierarchical Representation Learning for Networks
论文笔记 Hierarchical Reinforcement Learning for Scarce Medical Resource Allocation
论文笔记之: Hierarchical Convolutional Features for Visual Tracking