语音通信语音通信系统包括语音硬件采样,抽样量化,PCM编码解码模块,FIR滤波,QPSK调制解调模块,语音增强模块以及语音信号还原
Posted fpga和matlab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音通信语音通信系统包括语音硬件采样,抽样量化,PCM编码解码模块,FIR滤波,QPSK调制解调模块,语音增强模块以及语音信号还原相关的知识,希望对你有一定的参考价值。
1.软件版本
matlab2013b
2.系统设计概述
通信通常是发信者与收信者之间消息的往来,数字语音通信则是指将语音(模拟)信号转换成数字电信号进行传输的过程,其基本结构和通信系统基本结构一致,主要包括信源、发送设备、信道、接收设、信宿等几部分,其原理框图如图1所示。
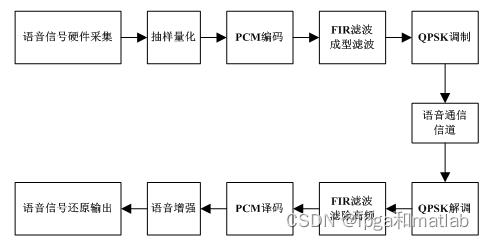
信道中的干扰主要分为:有源干扰( 噪声)、无源干扰(传输特性不良),信道中的噪声:信道中存在的不需要的电信号,又称加性干扰。噪声的种类有很多种,根据噪声的干扰特点,可以分为分为加性噪声和乘性噪声。加性噪声是一种表现为噪声信号对语音信号在时域进行相加的行为;而乘性噪声则反应了噪声和语音在频域是相乘的关系,在时域和语音则是卷积的关系。下面主要对周期性噪声干扰,脉冲噪声干扰以及宽带噪声干扰进行简介。
周期性噪声:周期性噪声周期性运转的机械设备。对于周期性噪声一般可以通过固定滤波器,自适应滤波器和傅里叶变换滤波器进行滤波,主要运用功率谱检测的方式,故周期性噪声对语音信号的影响很小。
脉冲噪声:脉冲信号是在时域波形中突然出现的窄脉冲的总称。在时域范围内滤除脉冲噪声的方法主要方法:根据预先计算好的语音信号的平均幅度值来计算判决门限值,当幅度超出预设门限值时,则认为该信号为脉冲噪声,随即对该信号进行衰减,直到完全消除为止。
带宽噪声:带宽噪声具有噪声频谱遍布于语音信号频谱之中的特点,可以假设其噪声为高斯噪声和白噪声。
语音信号的采样
根据实际的语音信号的分析可知,语音信号主要有下面两个特点:
第一,语音信号具有短时性特点,即语音信号的特征是随着时间的变化而变化,但是在短时间内,语音信号保持一定的平稳性。
第二,语音信号的频谱能量主要集中在300-3400Hz的范围内。
图2为语音信号的时域波形图和频域图:
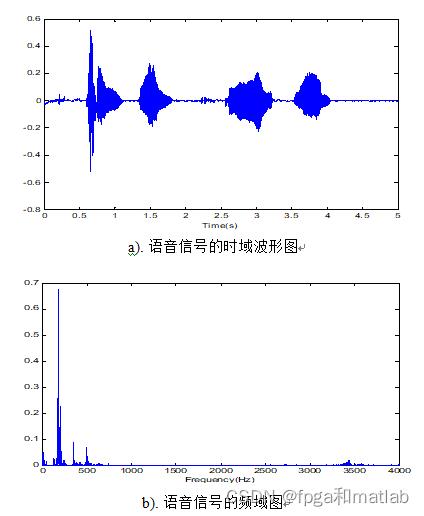
在将语音信号进行采集之前,先进行预滤波,预滤波的主要作用是对语音信号进行防混叠处理。预滤波主要作用有如下两点:
第一,抑制输入信号各领域分量中频率超出fs/2的所有分量(fs为采样频率),以防止混叠干扰。
第二,抑制50Hz的电源工频干扰。
语音信号的量化
语音信号的量化过程是将采样后的信号按整个声波的幅度划分成有限个区段的集合,把落入某个区段内的样值归为一类,并赋于相同的量化值。采取二进制的方式,以8位或16位的方式来划分纵轴。也就是说在一个以8位为记录模式的音效中,其纵轴将会被划分为个量化等级,用以记录其幅度大小。采样原理的示意图如图3所示:
通过对采集到的语音信号的量化,可以将语音信号转换为二进制数据。
PCM编解码原理
PCM 传输技术主要是对系统接收到的模拟信号进行数字化的过程[15],因为其内部的非均匀量化技术能有效改善信号的量噪比,其内部采用复用技术能有效的扩充通信容量而广泛应用在数字通信系统中时,因此本文的设计过程中采用 PCM 传输技术。
脉冲编码调制(pulse code modulation,PCM)是概念上最简单、理论上最完善的编码系统,是最早研制成功、使用最为广泛的编码系统,但也是数据量最大的编码系统。
PCM在通信系统中完成将语音信号数字化功能,它的实现主要包括三个步骤完成:抽样、量化、编码。根据CCITT的建议,为改善小信号量化性能,采用压扩非均匀量化,有两种建议方式,分别为A律和μ律方式,我国采用了A律方式,由于A律压缩实现复杂,常使用13 折线法编码,采用非均匀量化PCM编码。
下面,我们结合上一章节所介绍的A律量化过程,介绍PCM编码过程,目前国际上普遍采用8位非线性编码。例如PCM 30/32路终端机中最大输入信号幅度对应4096个量化单位,在4096单位的输入幅度范围内,被分成256个量化级,因此须用8位码表示每一个量化级。
语音信号的调制解调原理

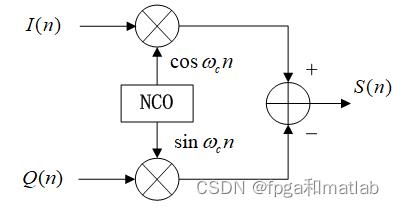
信号的解调是信号调制的逆过程,同时解调的方法因调试的方式不同而不一样,一般情况下,语音信号的解调可以分为相干解调与非相干解调。其中,相干解调性能比非相干解调性能要好,解调端结构如下图所示:
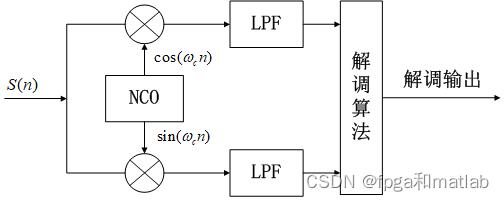
语音信号降噪模块原理
这里,我们使用基于VSLMS算法和子空间降噪算法的语音信号的降噪模块,降噪算法的基本结构如下图所示:
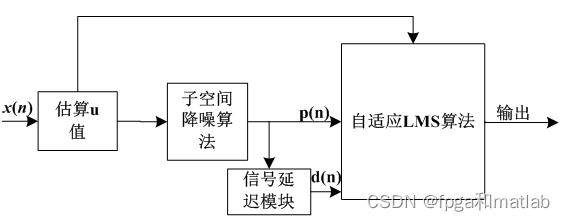
整体上分为二阶段处理,在此之前首先需要对估算因子进行估算,然后将一段带噪声的语音信号通过VSLMS进行滤波,再将滤波后的信号通过子空间降噪算法进行进一步滤波。这是因为,子空间降噪滤波算法在低信噪比下,性能较差,而对于信噪比较高的情况,则具有较佳的滤波效果;而VSLMS在处理有色噪声上不具有很好的效果。
子空间算法的主体思想是将语音信号分解成信号空间和噪声空间两个分立的空间,然后分别对这两个空间进行处理。本文采用时域范围内的子空间算法,在信噪分离上采用特征值分解,主要的执行过程为:
步骤1:计算带噪信号信号的协方差矩阵Ry,并对估计矩阵Σ采用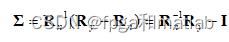 进行计算,对于噪声信号协方差矩阵Rn的估算则是在语音信号空闲阶段;
进行计算,对于噪声信号协方差矩阵Rn的估算则是在语音信号空闲阶段;
步骤2:采用特征值分解的方法来计算Σ;
步骤3:估算语音信号空间的范围M;
步骤4:估算μ值用于平衡算法效果;
步骤5:计算最优线性估计值Hopt;
步骤6:根据公式x=Hopt * y完成最终滤波。
结合VSLMS算法,权值W的更新优良将直接影响到算法的特性。为此,在新型算法中,本文增加并统一了μ值的估算,该μ值的引入使得步长变化更加具有合理性以及准确性,作为加权因子同时作用于子空间降噪算法,使得该算法在残余噪声和降噪效果上作出一个合理的平衡。
权值更新公式如下所示:
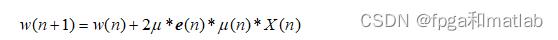 在低信噪比(-5dB)的情况下,由于噪声信号和语言信号有很大的相关性,子空间算法需要加强对噪声估计时,引入大的μ值将使得算法对噪声具有很强的抑制能力,使得残余噪声最小化,但与此同时则不可避免的使得语音信号失真,后续的VSLMS则弥补了子空间在的劣势,通过迭代的方式修正了语音信号;在高信噪比(20dB)的情况下,引入小的μ值将减小语音信号的失真,但是为此付出的代价则是高容量的残余噪声,VSLMS算法则具有减少残余噪声的能力。
在低信噪比(-5dB)的情况下,由于噪声信号和语言信号有很大的相关性,子空间算法需要加强对噪声估计时,引入大的μ值将使得算法对噪声具有很强的抑制能力,使得残余噪声最小化,但与此同时则不可避免的使得语音信号失真,后续的VSLMS则弥补了子空间在的劣势,通过迭代的方式修正了语音信号;在高信噪比(20dB)的情况下,引入小的μ值将减小语音信号的失真,但是为此付出的代价则是高容量的残余噪声,VSLMS算法则具有减少残余噪声的能力。
3.部分源码
语音信号的A律量化的PCM编译码设计与仿真
function ypcm=alaw(yn)
x=yn;
s=sign(x);
x=abs(x);
ypcm=zeros(length(x),1);
%进行基于13折线的分段映射
for i=1:length(x)
if x(i)<1/64 %序列值位于第1和第2折线
ypcm(i)=16*x(i);
elseif x(i)<1/32 %序列值位于第3折线
ypcm(i)=8*x(i)+1/8;
elseif x(i)<1/16 %序列值位于第4折线
ypcm(i)=4*x(i)+2/8;
elseif x(i)<1/8 %序列值位于第5折线
ypcm(i)=2*x(i)+3/8;
elseif x(i)<1/4 %序列值位于第6折线
ypcm(i)=x(i)+4/8;
elseif x(i)<1/2 %序列值位于第7折线
ypcm(i)=1/2*x(i)+5/8;
else %序列值位于第8折线
ypcm(i)=1/4*x(i)+6/8;
end
end
ypcm=ypcm.*(2^7);
ypcm=floor(ypcm);
ypcm=ypcm.*s;
function ypcm=unalaw(name)
x=name;
s=sign(x);
x=abs(x);
%归一化
x=x/128;
ypcm=zeros(length(x),1);
%基于13折线的分段解码映射
for i=1:length(x)
if x(i)<2/8 %序列值位于第1和第2折线
ypcm(i)=1/16*x(i);
elseif x(i)<3/8 %序列值位于第3折线
ypcm(i)=1/8*(x(i)-1/8);
elseif x(i)<4/8 %序列值位于第4折线
ypcm(i)=1/4*(x(i)-2/8);
elseif x(i)<5/8 %序列值位于第5折线
ypcm(i)=1/2*(x(i)-3/8);
elseif x(i)<6/8 %序列值位于第6折线
ypcm(i)=x(i)-4/8;
elseif x(i)<7/8 %序列值位于第7折线
ypcm(i)=2*(x(i)-5/8);
else %序列值位于第8折线
ypcm(i)=4*(x(i)-6/8);
end
end
ypcm=ypcm.*s;
%调制
function [I_Data,Q_Data] = QPSK_signal(len);
%QPSK信号源
%I_Data=randint(len,1)*2-1;
%Q_Data=randint(len,1)*2-1;
%s=I_Data + j*Q_Data;
I_Data = randint(len,1)*2-1;
Q_Data = randint(len,1)*2-1;
%解调
n=1000;
x = randint(n,1); %产生信源.
h = modem.pskmod (4); %产生调制句柄
y = modulate(h,x); %对信号进行调制
g = modem.pskdemod (h) %产生解调句柄
z = demodulate(g,y); %进行解调
4.仿真结论
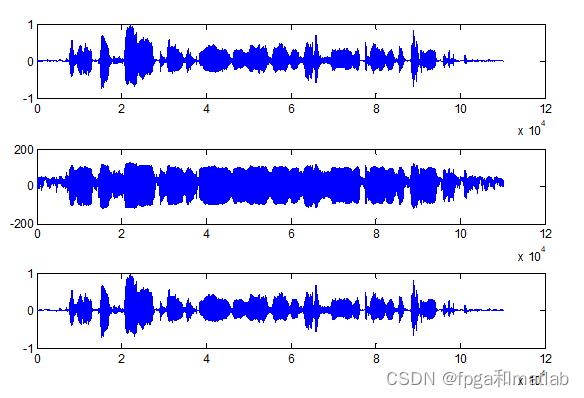
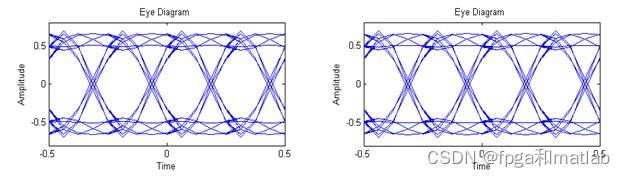
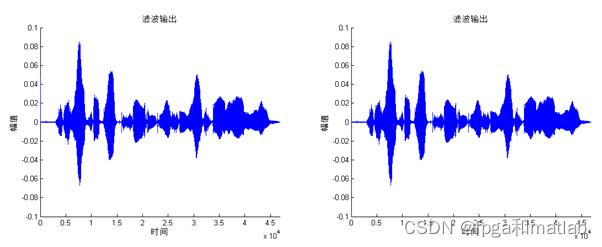
5.参考文献
[01]韩利竹,王华. MATLAB 电子仿真与应用[M] . 北京: 国防工业出版社, 2001.
[02]皇甫堪, 陈建文, 楼生强. 现代数字信号处理[M]. 北京: 电子工业出版社, 2003:38-45.
[03]Hu Yi, Loizou P C. Speech Enhancement Based on Wavelet Thresholding the Multitaper Spectrum[J]. IEEE Trans. on Speech and Audio Processing, 2004, 12(1): 59-67.
[06]Ephraim Y, Van Trees H L.A Signal Subspace Approach for Speech Enhancement [J]. IEEE Trans. Speech Audio Processing, 1995, 3(4):251-266.A03-10
以上是关于语音通信语音通信系统包括语音硬件采样,抽样量化,PCM编码解码模块,FIR滤波,QPSK调制解调模块,语音增强模块以及语音信号还原的主要内容,如果未能解决你的问题,请参考以下文章