WAX云钱包Cloudflare反爬虫突破(SSL指纹识别)
Posted encoderlee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WAX云钱包Cloudflare反爬虫突破(SSL指纹识别)相关的知识,希望对你有一定的参考价值。
WAX云钱包
在之前的多篇文章中,我们使用【Python】+【Selenium】来实现WAX链游脚本,主要是因为很多玩家一开始都是用WAX云钱包注册的账号,而WAX云钱包的私钥托管在云端,我们没法拿到私钥放到【eosjs】中去直接调用智能合约,所以最终的脚本需要借助【Selenium】和【Chrome】浏览器来运行,因为我们需要在【Chrome】中注入javascript去调用WAX云钱包提供的SDK【waxjs】,这个【waxjs】有一个【login】方法和一个【api.transact】方法,调用的时候会弹出一个授权窗口,来完成交易签署和提交。
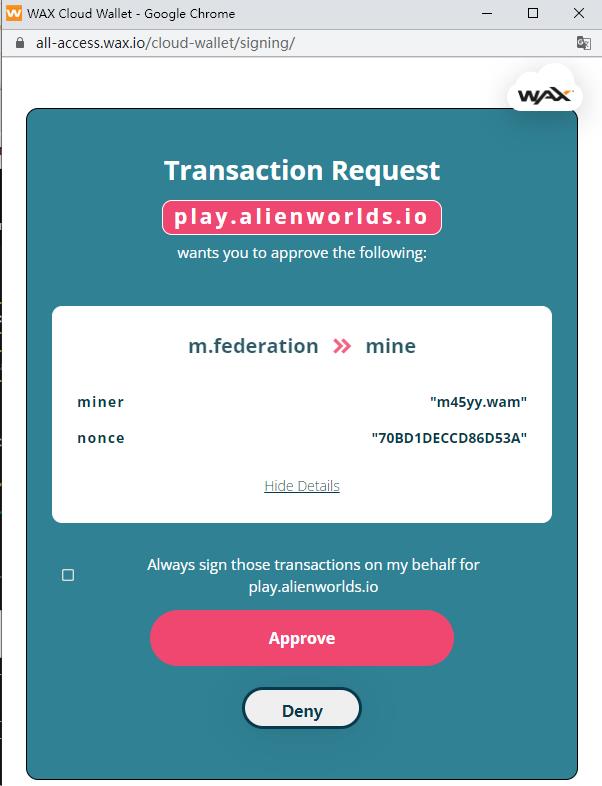
正是由于这个小小的弹窗,【waxjs】没法直接脱离浏览器,在【Python】的【js2py】或【nodejs】中执行,自然就背上了【Chrome】这个沉重的玩意,使得一台电脑多开的数量大大减少。
为了无窗口、静默的运行脚本,我们当然可以使用【Anchor】钱包创建WAX原生账号,私钥拿在手里,就可以为所欲为,但是对于只支持WAX云钱包的链游,以及已有的WAX云钱包账号,还是得想办法来解决。
那么一个思路就是阅读【waxjs】的源代码,搞清楚它的【login】和【api.transact】方法,通过抓包和调试js搞清楚这个小弹窗做了什么事情,然后直接通过【Python】去发送HTTP请求来实现登录和签署交易的操作,也可以脱离【Chrome】来运行。
我们最近就在做这个事情,但是遇到了一些问题。
Sorry, you have been blocked
我们使用【Python】+【resquests】学着浏览器的样子给WAX云钱包服务端发送HTTP请求的时候,出现了【403 Forbidden】的错误,以下面简单的代码为例:
import requests
resp = requests.get("https://public-wax-on.wax.io/wam/sign")
print(resp.text)
正常情况下,这个GET请求应该返回一个json,可以在【Chrome】浏览器中或【Postman】中直接请求这个地址以验证这一点。

但是我们使用【Python】发送请求后,却收到了【403 Forbidden】错误,并且返回一个这样的页面:
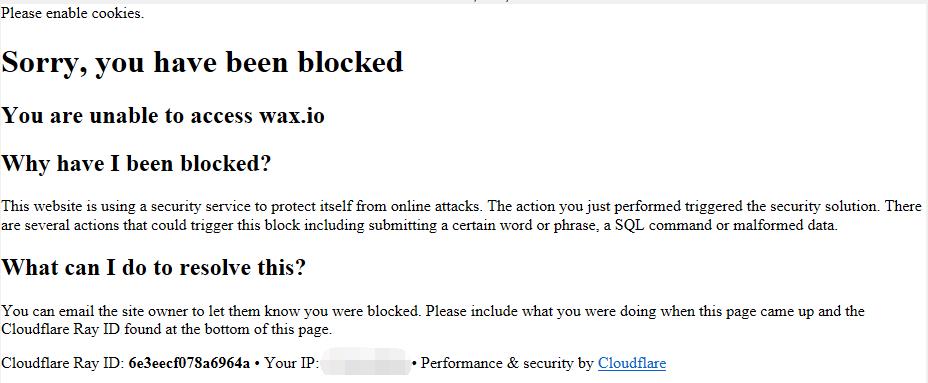
Please enable cookies.
Sorry, you have been blocked
You are unable to access wax.io
Why have I been blocked?
This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
What can I do to resolve this?
You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
Cloudflare Ray ID: 711e5eaf6819980c • Your IP: * • Performance & security by Cloudflare
显然,WAX云钱包使用了Cloudflare做CDN加速,而我们被Cloudflare的反爬虫机制制裁了。
这种情况很常见,我们第一时间想到的就是【Python】发出的HTTP请求头和【Chrome】发出的请求头内容有差异,尤其是【User-Agent】,于是我们修改代码来模拟这个请求头:
import requests
client = requests.Session()
client.headers["User-Agent"] = "Mozilla/5.0"
resp = client.get("https://public-wax-on.wax.io/wam/sign")
print(resp.text)
但无济于事,还是被【403 Forbidden】制裁
于是我们直接上【Fiddler】抓包,分别用【Python】和【Chrome】发送请求,仔细检查每一个请求头的差异,并且不断的修改【Python】代码,让【Python】代码发出的HTTP请求和【Chrome】发出的请求完全一致,一个字符都不差,通常这种方法可以解决大部分的此类问题。
但奇怪的是,当我们开启【Fiddler】的HTTPS解密功能,并让【Python】代码走【Fiddler】代理访问后,居然就正常了!
import requests
client = requests.Session()
client.headers["User-Agent"] = "Mozilla/5.0"
client.proxies =
"http": "http://127.0.0.1:8888",
"https": "http://127.0.0.1:8888",
resp = client.get("https://public-wax-on.wax.io/wam/sign",verify=False)
print(resp.text)
此时【Python】代码发送的HTTP请求,正常拿到了json内容,而没有被【Cloudflare】用【403 Forbidden】拦截
What!难道是【Fiddler】作为中间人代理,修改了我HTTP请求的内容?或是调整了一些Header的顺序?或是修改了Header的内容?多年的经验告诉我,不应该呀,【Fiddler】代理默认是不可能修改HTTP请求中的任何内容的。
为了验证这一点,我们用【Python】写了一个简单的https server,来对比【Python】直接发HTTP请求与通过【Fiddler】发送HTTP请求的内容,究竟有什么差异。
import ssl
import socket
import hashlib
context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
context.load_cert_chain('test.pypig.com.pem', 'test.pypig.com.key')
with socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) as sock:
sock.bind(('0.0.0.0', 443))
sock.listen(5)
with context.wrap_socket(sock, server_side=True) as ssock:
while True:
conn, addr = ssock.accept()
data = conn.read()
print(data)
md5 = hashlib.md5()
md5.update(data)
print(md5.hexdigest())
conn.send("HTTP/1.1 200 OK\\r\\nContent-Type: text/plain\\r\\n\\r\\nHello, world!\\r\\n".encode())
conn.close()
这个https server直接用ssl socket来写,打印出每个HTTP请求最原始的请求内容,同时给出md5值,以确定两次http请求的内容是否一个字节都不差。
然后用【Python】+【resquests】发起请求,先直接请求:
import requests
client = requests.Session()
client.headers["User-Agent"] = "Mozilla/5.0"
resp = client.get("https://test.pypig.com/sign")
print(resp.text)
然后挂【Fiddler】代理来请求:
import requests
client = requests.Session()
client.headers["User-Agent"] = "Mozilla/5.0"
client.proxies =
"http": "http://127.0.0.1:8888",
"https": "http://127.0.0.1:8888",
resp = client.get("https://test.pypig.com/sign", verify=False)
print(resp.text)

结果我们的微型https server告诉我们,挂不挂【Fiddler】代理,服务端收到的HTTP请求,一个字节都不差。
What! 那为什么挂上【Fiddler】代理,Cloudflare就不拦截我们了,直接访问,Cloudflare就要拦截我们?
在排除IP问题以后,我们可以确定我们发给Cloudflare的数据包,在HTTP协议层上的数据一个字节都不差,那么有可能的,就是HTTP协议层下面的数据包的差异了。
SSL指纹识别
经过一番搜索,我们发现了Cloudflare很有可能是通过SSL指纹识别来认定我们的HTTP请求,不是从正常的浏览器发出的,而是Python之类的脚本程序,从而拦截了我们。
SSL指纹是什么呢?简单来说,客户端发起https的请求的第一步就是向服务器发送tls握手请求,这其中就包含了客户端的一些特征,比如:
SSLVersion,Cipher,SSLExtension,EllipticCurve,EllipticCurvePointFormat
我们使用【Wireshark】来抓包看看究竟是什么特征:
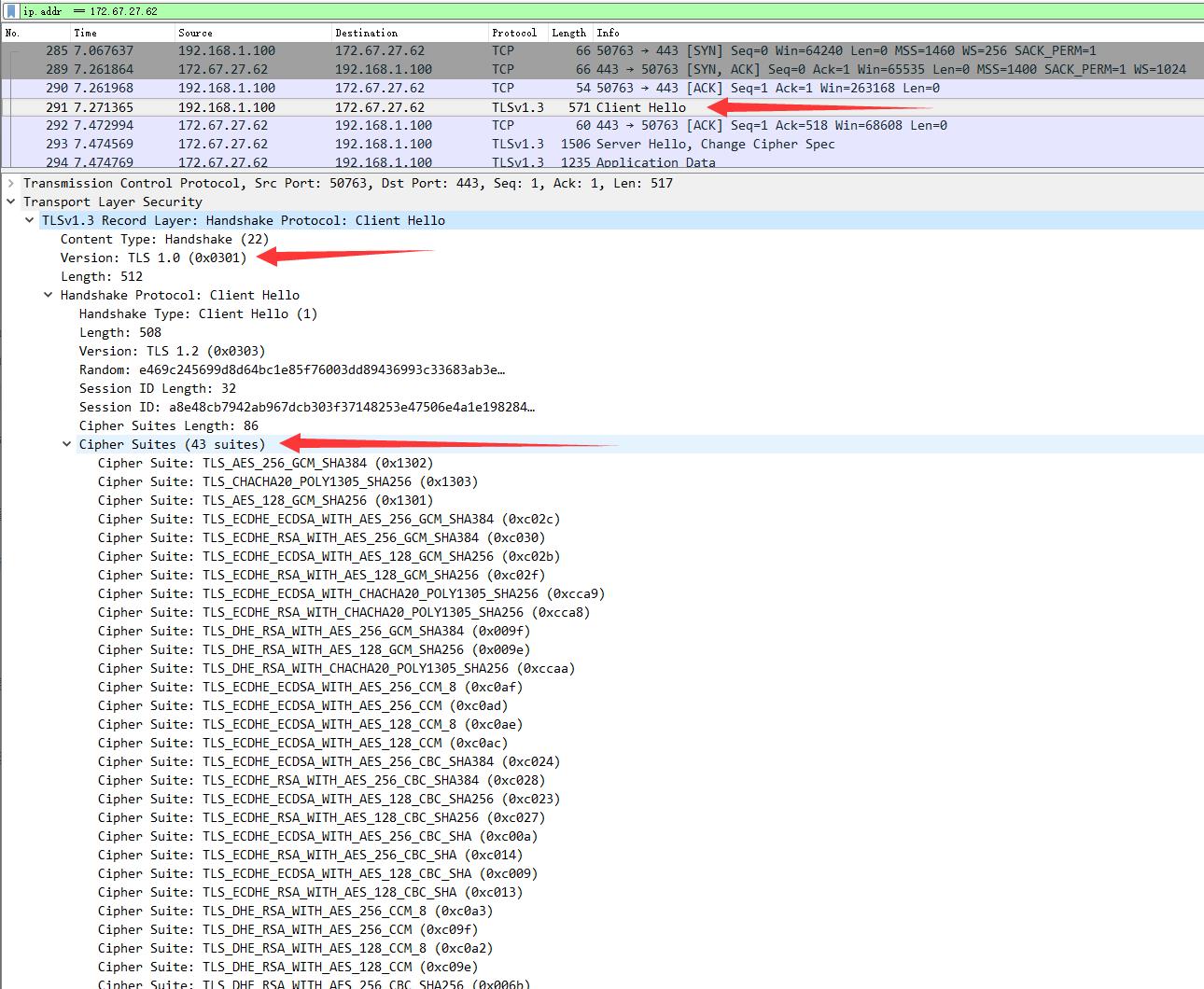
我们可以看到,TLS握手阶段的【Client Hello】中包含了一些我们客户端SSL Library的特征,这取决于我们客户端用的openssl版本,编译openssl的时候选择支持的Cipher suite等信息。Cloudflare有一个SSL指纹特征库,再结合【User-Agent】很容易判断出你的这个HTTP请求,根本不是来自于【Chome】或【Firefox】浏览器,于是把你拒绝。
其实Cloudflare已经公开了他们的SSL指纹识别工具及特征库:
https://github.com/cloudflare/mitmengine
关于SSL指纹识别,这里有一些好的资料可以参考:
https://blog.cloudflare.com/monsters-in-the-middleboxes
https://github.com/salesforce/ja3
https://www.buaq.net/go-69547.html
https://ares-x.com/2021/04/18/SSL-%E6%8C%87%E7%BA%B9%E8%AF%86%E5%88%AB%E5%92%8C%E7%BB%95%E8%BF%87/
修改特征
很显然,我们的【Python】+【resquests】发起的HTTP请求被Cloudflare拦截就是因为Cloudflare已经记录了常见【Python】版本自带的【openssl】的特征。但由于我们下载使用的都是【Python】官方编译好的Release版本,我们已经没法去修改替换【Python】自带的的ssl library,一种可行的办法就是自己从源码重新编译【Python】,编译的时候自行调整【openssl】的版本和编译参数,但显然都太麻烦了,而且不利于代码的分发。
但我们找到了一些偏门的方法,间接的影响【Python】发出的HTTPS请求中的TLS握手特征,从而逃过Cloudflare的特征库识别。
方法一:
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.ssl_ import create_urllib3_context
class CipherAdapter(HTTPAdapter):
def init_poolmanager(self, *args, **kwargs):
context = create_urllib3_context(ciphers='DEFAULT:@SECLEVEL=2')
kwargs['ssl_context'] = context
return super(CipherAdapter, self).init_poolmanager(*args, **kwargs)
def proxy_manager_for(self, *args, **kwargs):
context = create_urllib3_context(ciphers='DEFAULT:@SECLEVEL=2')
kwargs['ssl_context'] = context
return super(CipherAdapter, self).proxy_manager_for(*args, **kwargs)
client = requests.Session()
client.mount('https://public-wax-on.wax.io', CipherAdapter())
client.headers["User-Agent"] = "Mozilla/5.0"
resp = client.get("https://public-wax-on.wax.io/wam/sign")
print(resp.text)
我们可以指定不同的SSL安全级别,来影响TLS握手【Client Hello】中的内容,从而改变特征。
使用上面的代码以不同的SSL安全级别来发送HTTP请求,然后用【Wireshark】来抓包对比观察差异:

分析两次TLS握手【Client Hello】中的内容,可以看到,修改了SSL安全级别后,很多特征发生了变化,尤其是密码套件【Cipher Suite】的数量都发生了变化,而【Cipher Suite】的特征,正是Cloudflare记录的特征之一,另外一些【SSLExtension】也发生了变化,这讲导致我们修改后的SSL指纹特征发生较大变化,和Cloudflare的指纹库匹配不上,自然就把我们放过了。
方法二:
import requests
import cloudscraper
scraper = cloudscraper.create_scraper(browser='browser': 'firefox', 'platform': 'windows', 'mobile': False)
resp = scraper.get("https://public-wax-on.wax.io/wam/sign")
print(resp.text)
另一种方法是直接使用别人写好的反检测对抗库
【cloudscraper】:https://github.com/VeNoMouS/cloudscraper
使用前需要先安装:
pip install cloudscraper
另外,还有一个类似的开源库也是做这个事情的:
【cloudflare-scrape】:https://github.com/Anorov/cloudflare-scrape
这两个库都很强大,他们最有用的部分还不只是过SSL指纹识别检测,而是处理一些需要执行JavaScript的反机器人页面,以及一些识别人类还是机器人的验证码。
顺利进行
至此,我们脱离【waxjs】直接和WAX云钱包服务端交互来登录和签署交易的脚本得以顺利进行,成功脱离【Chrome】等浏览器,直接使用WAX云钱包账号来签署交易。提高了脚本运行效率,降低了内存占用,使得一台电脑上的多开数量大大增加。
交流讨论

以上是关于WAX云钱包Cloudflare反爬虫突破(SSL指纹识别)的主要内容,如果未能解决你的问题,请参考以下文章