TCP Delayed ACK 辩证考
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP Delayed ACK 辩证考相关的知识,希望对你有一定的参考价值。
TCP Delayed ACK 的 WiKi 解释:
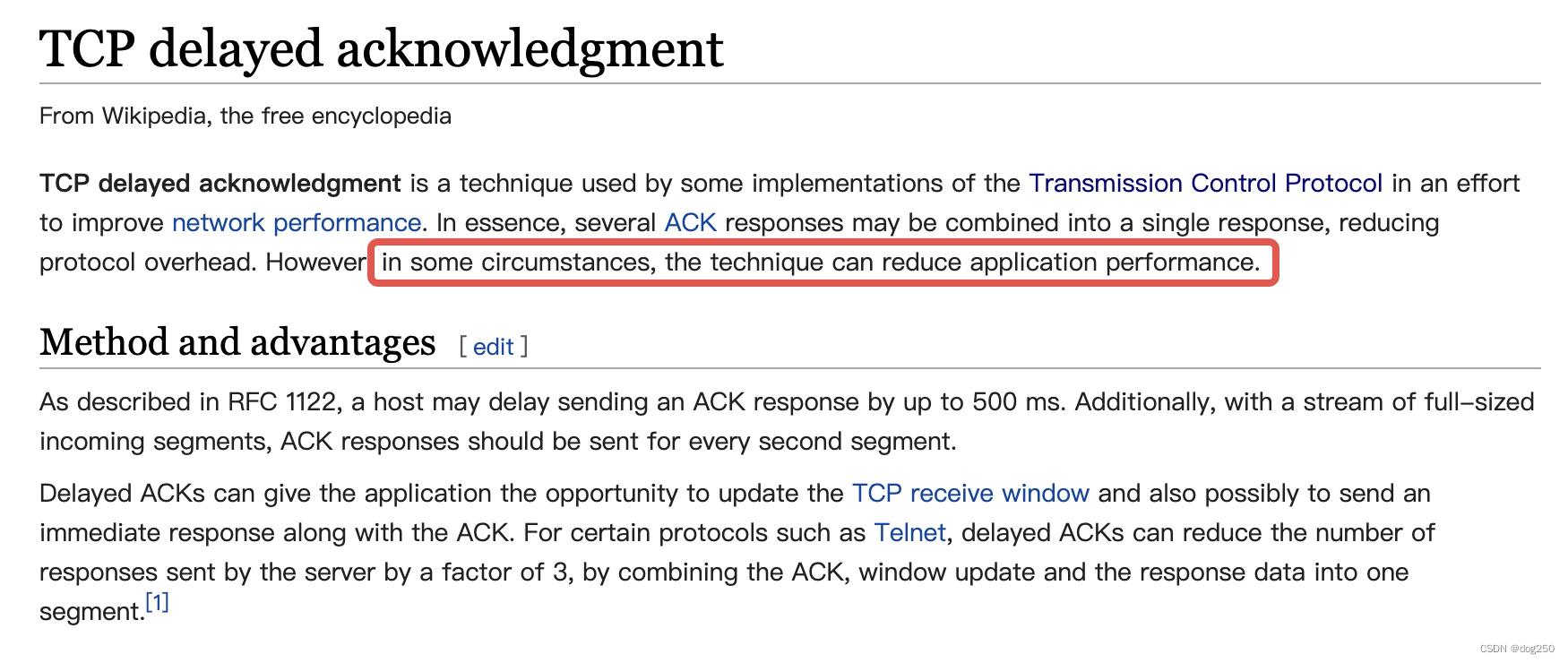
看下红框里说的“某些劣化性能的场景”:

是不是很复杂?特别是跟 Nagle 算法,糊涂窗口综合症揉在一起,需要理解各种情况如何组合这些配置。
复杂的根源在哪儿?
先看 Delayed ACK 的目标:减少 Pure ACK 数量,提升有效载荷率。
再看 Nagle 算法的目标:减少小包数量,提升有效载荷率。
二者的目标一致,为何会冲突?
根源在于 Delayed ACK 在接收端,Nagle 算法在发送端,不知道对端情况。两端对不齐,仅靠猜肯定不行。
TCP 在 1981 年被 RFC793 标准化,Delayed ACK 在 1989 年 RFC1122 中发布,Nagle 算法在 1984年 RFC896中发布,RFC793 定义的 TCP 头没有任何 Delayed ACK 和 Nagle 算法的表达能力,且 RFC1122 和 RFC896 未对 TCP 头进行任何修改。
找到了根源,解决方案就有了,两个配置统一由发送端决定。对 TCP 头进行扩展,增加其明确的表达能力:
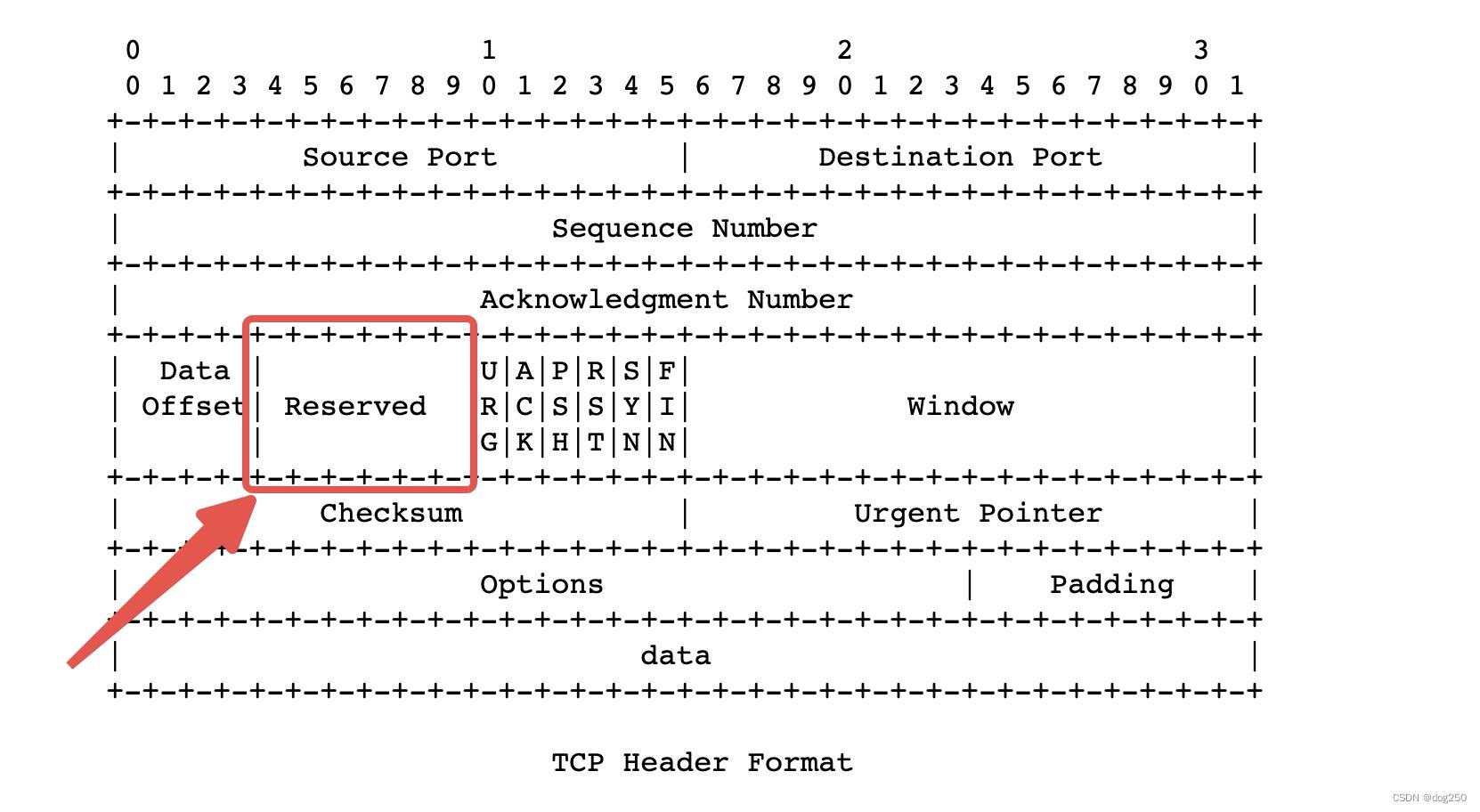
在这 6 bits 保留空间内找一个 bit,其意义是:
- b0:对端决定是否立即应答,保持兼容。
- b1:对端必须立即应答。
对启用 Nagle 算法的小包,设置上该标志即可。两端可分别升级协议,若其中一端不升级,失去该能力而已。
令人不解的是,为什么这么多年没有人做这个简单的扩展以提升协议表达能力,反而搞出那么多的原则:
- 如果服务端配置了xxx,客户端就必须配置xxx
- 如果服务端没有xxx,客户端就必须xxx
- …
接着看 Delayed ACK 和 Nagle 算法的共同目标,都为提升网络的载荷率。如果焦点集中在 Delayed ACK 和 Nagle 算法本身而不是它们的目标,很容易重新陷入复杂。
再小的包也要转发设备和端主机消耗资源来处理,如果 Delayed ACK 和 Nagle 算法只单纯减少了网络数据包数量而卸载了转发设备处理压力的话,那么 LRO/GRO 则同时减少了二者:
- LRO/GRO 聚合 Data 包减少了接收端需要处理数据包的数量。
- 聚合后的大块 Data 批量被应答,减少了 ACK 数量。
LRO/GRO 后的ACK 也可理解为 Delayed ACK,只是将 Delay 下放在批量收集 Data 的逻辑中。我之前也做实验验证过,开启和未开启 LRO/GRO ,吞吐性能相差近一倍,根源就是未开启 LRO/GRO 时过多的 Data 和 ACK 线性消耗了元数据处理开销。
一辆车运 100 千克,运 1 吨需要 10 辆车 10 个司机,一辆车运 1 吨,只需要 1 辆车 1 个司机。
LRO/GRO 的代价是需要增加一点聚合延时。
可无论再怎么聚合,一个 IP 包最大容量也就 64KB,Delayed ACK 也就能 skip 2*64KB 字节确认一回,但也仅此而已。最近的 BIG TCP patch 差不多就是优化这个问题的:
tcp: BIG TCP implementation
这些复杂的方案都没有从根源上解决问题,但好处是只需要修改两端中的一端就能有不错效果。
如何从根源解决问题,需要通过提升 TCP 协议表达能力最大化 Delayed ACK 收益。仍从 TCP 协议头入手,这次借用 2 个 bits,当然了,这 2bits 也可以在 option 中实现:
- b00:对端决定是否立即应答,保持兼容。
- b01:对端必须立即应答。
- b10:除非 RFC 要求必须立即应答的情况,建议对方不应答。
- b11:N/A
发送端统一决定 ACK 的频率,又不影响拥塞状态机。
发送端可如下决策,不影响采样的前提下,每间隔 10*64KB 的距离设置一次 b10 。这将使 Pure ACK 数量大大减少,达到 Data 和 ACK 的 640:1 的数量比,为网络设备和端主机减负。
同样令我不解,30年来没人改动过 TCP 的这些逻辑,倒也不是说不好升级,问题是 SACK,Timestamps,Fast Open 不都是后加进去的吗?考虑到兼容性,这些均通过 TCP option 协商决定。为什么 Delayed ACK 不呢?而且它可以天然兼容,甚至不必协商。
在我看来,数据包是否需要被 ACK 的标志位和 PSH 标志位没什么两样。
令人遗憾但却有趣的事是,QUIC 竟然继承了 TCP 关于什么时候发送 ACK 的机制,没有把该权力权力统一交给发送端。我想 QUIC 设计时并没有考虑单机性能问题吧,因为单机性能问题 TCP 也没多考虑。
最新的 RFC9114 还没细看,这里说一个三年前我做的一件事,典型的因 QUIC 表达能力不足把事情复杂化的有关单机性能的 case。
运行 QUIC 后 CPU 变高,发现 QUIC 的 Data/Pure ACK 数量比太高,ACK copy 到用户态以及上下文切换开销太大。TCP 那么多 ACK 没有表现出太大单机性能问题,部分原因是 ACK 不需要copy 到用户态处理。
我想了一个点子,内核 GRO 这个位置捕捉相同 UDP 五元组,尽可能将 UDP 报文聚合在一起,考虑到 QUIC 是加密的,不便在内核解密,将被聚合的 UDP Payload 用 TLV(Type-Length-Value) 分隔后拼接,最终加一个 UDP 头统一上送,待一个大 UDP 包收到用户态后,在库层面通过 TLV 分成原始的 QUIC Payload,交给程序处理。
CPU 降了,可 Delivery rate 相对不准了,这分明是聚合 UDP 小包时的额外延时引入的误差。总体看来,我的这番折腾其实就是 TCP LRO/GRO 在接收端做的那些事。
看起来做了一件足够复杂且有点技术含量的事,但并没从根本上解决问题。根本解法就是 QUIC 发送端根据数据采集需要以及资源能力,自己决定 Pure ACK 的频度。
有时候确实是没有消息就是好消息,TCP 的 ACK 自时钟被认为是理所当然的,但实际上那也只是一种手段。
…
考虑原始 TCP,接收端将为每一个 Data 包回送一个 ACK,若全世界的流量均是 TCP-Based,那么整个网络 50% 的数据包都是 ACK,50% 以数量记账的资源将被 ACK 消耗,因此减少 ACK 的数量,也是在为整个互联网减负。新生传输协议要多学好,不要比烂。
好了,这就是我今天要讲的故事。
想起了几年前做过的和单机性能有关的一例 case,结合 TCP Delayed ACK,写篇短文。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于TCP Delayed ACK 辩证考的主要内容,如果未能解决你的问题,请参考以下文章