深度学习系列40:cogview生成模型
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习系列40:cogview生成模型相关的知识,希望对你有一定的参考价值。
1. 模型介绍
开源地址见:https://github.com/THUDM/CogView
demo地址:https://agc.platform.baai.ac.cn/CogView/index.html
特点:基于中文
效果展示如下。在生成人像时,四肢细节有时会有些问题。
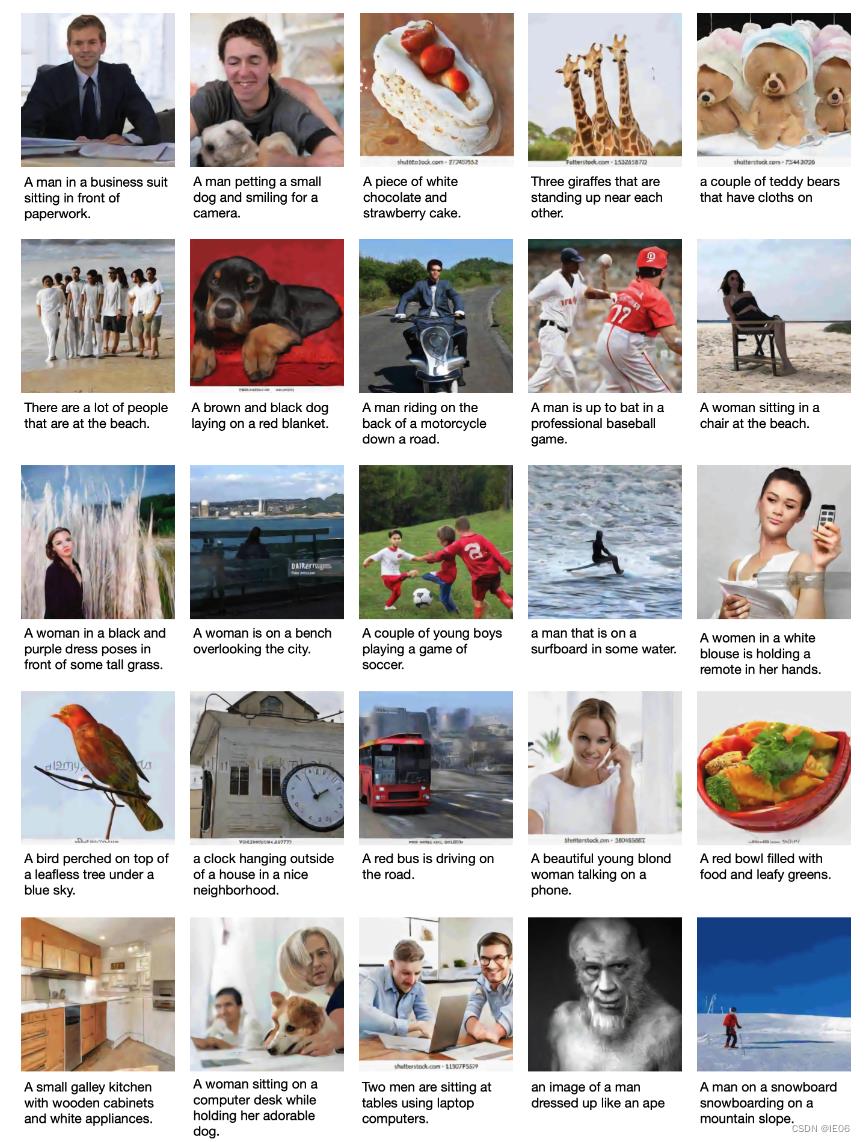
2. 快速上手
在gpu机器上拉取镜像:
docker pull cogview/cuda111_torch181_deepspeed040
./env/start_docker.sh && docker exec -it bg-cogview bash
cd /root/cogview # in the container
在pretrained/vqvae目录下,下载图像tokenizer:vqvae_hard_biggerset_011.pt:
wget https://cloud.tsinghua.edu.cn/f/71607a5dca69417baa8c/?dl=1 -O pretrained/vqvae/vqvae_hard_biggerset_011.pt
在pretrained/cogview/下,从https://resource.wudaoai.cn/home?ind=2&name=WuDao%20WenHui&id=1399364355975327744下载cogview模型并解压:

接下来就可以运行啦:
-
文本生成图像:在input.txt中输入文字,然后执行
./scripts/text2image.sh --debug
结果在samples_text2image/目录下 -
超分
对上面生成的图片image_path执行:
./scripts/super_resolution.sh text\\timage_path -
图像转文本
./scripts/image2text.sh imagepath
3. 模型介绍
模型如下:
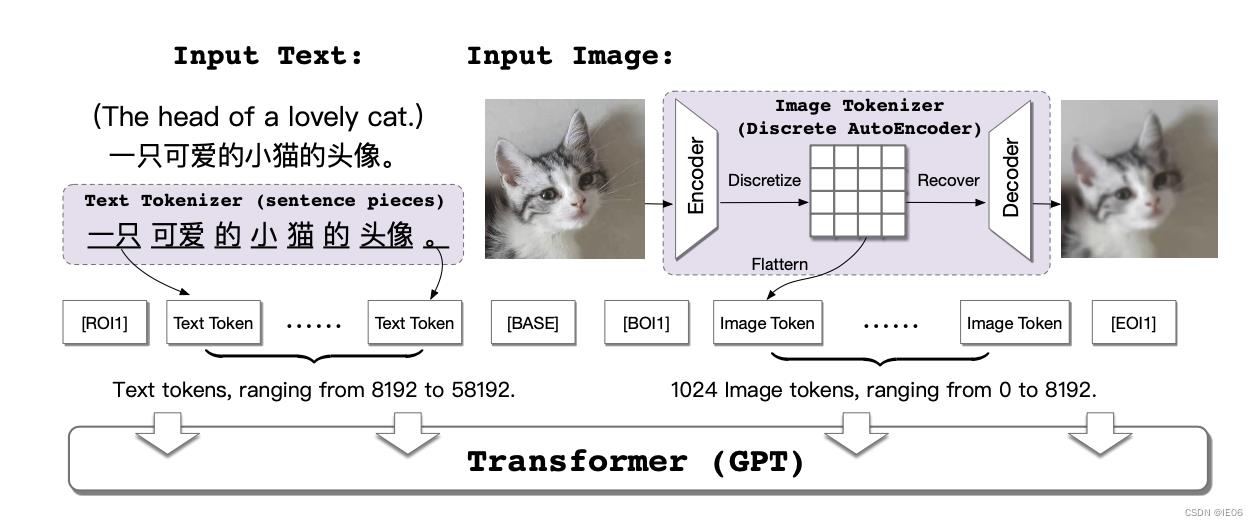
cogview的思想和dalle近似,将文本token和图像token输入transformer
- 文本token使用的是SentencePiece,token size为50000。
- 图像token使用的是VQVAE, ∣ V ∣ = 8192 , d = 256 , H = W = 256 , h = w = 32 ∣ V ∣ = 8192 , d = 256 , H= W = 256 , h = w = 32 ∣V∣=8192,d=256,H=W=256,h=w=32,需要提前学习编码器和解码器参数。
- 将文本和图像tokens进行拼接,四个Seperator字符,[ROI1](reference text of image),[ B A S E ] [BASE],[BOI1](beginning of image),[EOI1](end of image)被添加到每个序列中以指示文字和图像的边界。所有序列裁剪或补全到1088的长度的sequence上。
- 主网络使用单向Transformer(GPT)。Transformer有48层,隐藏的大小为2560,40个注意力头和40亿个参数。损失函数为交叉熵损失。
- 每个batch包含6144个sequence,在512台V100机器上训练144000步。
以上是关于深度学习系列40:cogview生成模型的主要内容,如果未能解决你的问题,请参考以下文章
深度学习100例-生成对抗网络(DCGAN)生成动漫小姐姐 | 第20天
深度学习100例-生成对抗网络(DCGAN)手写数字生成 | 第19天
深度学习100例-生成对抗网络(DCGAN)手写数字生成 | 第19天