聚类 - 4 - 层次聚类密度聚类(DBSCAN算法密度最大值聚类)
Posted 血影雪梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类 - 4 - 层次聚类密度聚类(DBSCAN算法密度最大值聚类)相关的知识,希望对你有一定的参考价值。
本总结是是个人为防止遗忘而作,不得转载和商用。
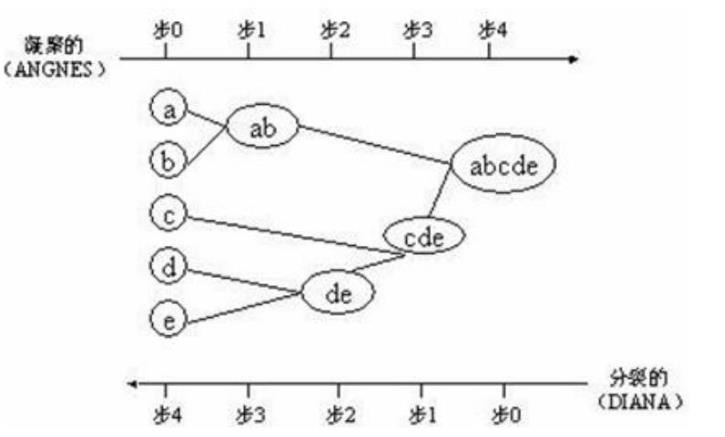
层次聚类:
层次聚类的思想有两种:凝聚的层次聚类、分裂的层次聚类。
以有A, B, C, D,E, F, G这7个样本为例。
凝聚的层次聚类
1, 将每个对象作为一个簇,这时就有7个簇。
2, 自底向上合并接近的簇,假设合并成了三个簇:AB,CDE,FG。
3, 重复第二步直到数量达到规定的簇的数量K。
分裂的层次聚类
1, 将所有的样本置于一个簇中。
2, 逐渐细分成越来越小的簇。
3, 重复第二步直到数量达到规定的簇的数量K。
用一幅图描述上面两种就是下图:
密度聚类
思想
密度聚类方法的指导思想是,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中。如:一个中国地图上标着每平方公里的人口密度,于是我们就可以通过这个密度进行聚类,某个地方很密,我就可以认为这个地方是个城市。
优点
这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。
缺点
计算密度单元的计算复杂度大,因此需要建立空间索引来降低计算量。
下面介绍两种密度聚类算法:DBSCAN算法、密度最大值算法。
DBSCAN算法
它将簇定义为密度相连的点的最大集合,于是能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。
DBSCAN算法的若干概念
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数目m,如果一个对象的ε-邻域至少包含m个对象,则称该对象为核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε-邻域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的。
密度可达:如果存在一个对象链p 1p 2 …p n ,p 1 =q,p n =p,对p i ∈D,(1≤i ≤n),p i+1 是从p i 关于ε和m直接密度可达的,则对象p是从对象q关于ε和m密度可达的。
密度相连:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε和m密度可达的,那么对象p和q是关于ε和m密度相连的。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
例子:如下图所示
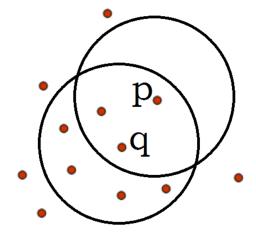
ε=1cm,m=5,q是一个核心对象,从对象q出发到对象p是直接密度可达的。但注意:从p到q不是直接密度可达,因为p都不是个核心对象。
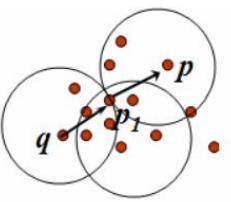
如上图所示,q直接密度可达p1,p1直接密度可达p,则q到p是密度可达。
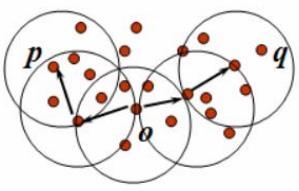
如上图所示,O密度可达p,O密度可达q,则p和q密度相连。
DBSCAN算法流程
1,如果一个点p的ε-邻域包含多于m个对象,则创建一个p作为核心对象的新簇;
2,寻找并合并核心对象直接密度可达的对象;
4, 没有新点可以更新簇时,算法结束。
由上述描述可知
每个簇至少包含一个核心对象;
非核心对象可以是簇的一部分,构成了簇的边缘(edge);
包含过少对象的簇被认为是噪声。
密度最大值聚类
我个人感觉这个是用于找聚类中心和异常值的。
密度最大值聚类是一种简洁优美的聚类算法, 可以识别各种形状的类簇, 并且参数很容易确定。
定义:局部密度ρi

dc是一个截断距离, ρi 即到对象i的距离小于dc 的对象的个数,即:ρi = 任何一个点以dc为半径的圆内的样本点的数量
由于该算法只对ρi 的相对值敏感, 所以对dc的选择是稳健的,一种推荐做法是选择dc ,使得平均每个点的邻居数为所有点的1%-2%
定义:高局部密度点距离δi(简称“高密距离”(注:该称呼不具代表性))
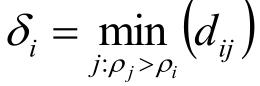
解释:
对第i个样本,我们可以算其局部密度ρi,第j个样本,我们可以算其局部密度ρj,其他样本点同理比如有:ρ1,ρ2,ρ3。
为了方便说明,假设:ρi= 8,ρ1=9,ρ2=10,ρ3=4,ρj=20.
然后对于第i个样本,将其局部密度和其他所有样本的局部密度作比较,于是乎:
因为ρi < ρ1,所以算算样本i和1之间的距离。
同理,算算i和2之间的距离,j和i之间的距离。
而因为ρi > ρ3,所以样本i和3之间的距离就不算了。
总之就是对于第i个样本,算算密度比它高的样本与其的距离。
最后,在这些距离中取最小的那个,就是高局部密度点距离。
一句话描述就是:
比我高的局部密度点到我的最小距离。(把这句话的黑体字连起来看看)
打个比方:
高局部密度点距离就是在做这个事:如果说局部密度是描述一个人有多少钱的话,那ρi = 8就是在说第i号人有8块钱,其他同理,于是高局部密度点距离就是在找“比我有钱的那个有钱人中离我最近的那个”(找到之后就方便抱大腿了啊)。
簇中心和异常点的识别
于是在上面的基础上,我们就可以选取簇中心和判断异常点了。
簇中心:
那些有着比较大的局部密度ρi和很大的高密距离δi 的点被认为是簇的中心。
什么意思?
如果用国民老公王思聪当做样本的话,那该样本一定有比较大的局部密度ρi,也就是他身边一定有很多人,但比他有钱的人可能离他很远,即有很大的高密距离δi,于是王思聪就是个簇中心。
异常点:
高密距离δi较大但局部密度ρi较小的点是异常点;
比如一个人:他身边没什么人,而且比他有钱的人离他也远,那这个人就有些不对劲了,这个人是隐士?还是离家出走到一个偏远地方?甚至被绑架了?!所以这个人就是个异常点。
其他:
对于密度最大的对象,设臵δi=max(dij )(即:该问题中的无穷大)
例子:
如下图所示:
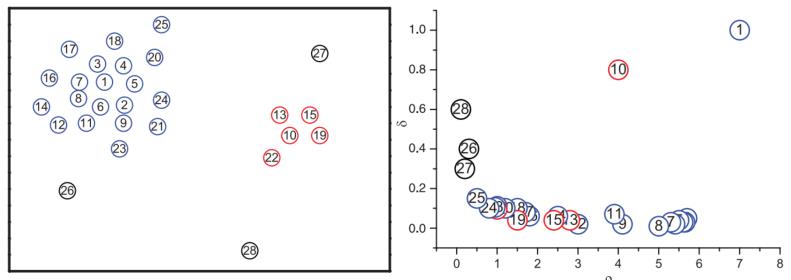
对于左图,计算每个样本的ρi和δi。
1,发现1号样本和10号样本的ρi和δi都大,那就可以怀疑:这两个点难道是聚类中心?答案很明显:是。这样一来就找到聚类中心了,之后用DBCSAN算法正常聚类就可以了。
2,样本28、26、27的ρi很小δi却很大,那就可以怀疑:这三个难道是异常点?答案也很明显:是。
以上是关于聚类 - 4 - 层次聚类密度聚类(DBSCAN算法密度最大值聚类)的主要内容,如果未能解决你的问题,请参考以下文章