物理内存是如何组织管理的
Posted Loopers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了物理内存是如何组织管理的相关的知识,希望对你有一定的参考价值。
内存管理,相比大家都听过。但是内存管理到底是做什么呢?这就得从计算机刚出来的时候说起。计算机刚出来的时候内存资源很紧张,只有几十K,后来慢慢的到几百K,到周后来的512M,再到现在的几个G。真是因为内存资源的不足,在计算机的整个过程中衍生出各种各样的内存管理方法。
而内存管理的终极目标就是合理的不浪费的使用物理内存。Linux针对如何合理的使用物理内存,软件上设计了多种的内存管理方法。今天我们就来讨论下Linux是如何组织物理内存的,通俗的说就是如何管理电脑的内存条的。
Linux使用节点(node),区域(zone),页(page)三级结构来描述整个物理内存。
node
目前计算机系统有两种体系结构:
- 非一致性内存访问 NUMA(Non-Uniform Memory Access)意思是内存被划分为各个node,访问一个node花费的时间取决于CPU离这个node的距离。每一个cpu内部有一个本地的node,访问本地node时间比访问其他node的速度快
- 一致性内存访问 UMA(Uniform Memory Access)也可以称为SMP(Symmetric Multi-Process)对称多处理器。意思是所有的处理器访问内存花费的时间是一样的。也可以理解整个内存只有一个node。
- NUMA通常用在服务器领域,可以通过CONFIG_NUMA来配置是否开启
zone
ZONE的意思是把整个物理内存划分为几个区域,每个区域有特殊的含义。
先来看下内核中对zone的定义
enum zone_type
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
;为了更好的解释各个ZONE的含义,比如上图。
32位系统:
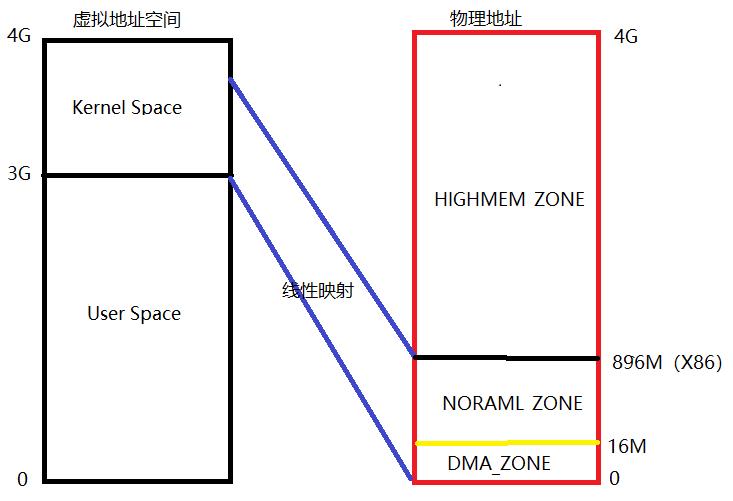
在32位系统中,假设我们物理内存是4G的。
- DMA_ZONE是因为在X86架构下,有些DMA设备只能访问16M以下的地址,所以设计出了DMA_ZONE,当DMA设备访问内存时,从DMA_ZONE去获取内存
- HIGHMEM_ZONE: HIGHMEM_ZONE是32位时代的产物。出现的原因是:32位系统中4G的虚拟地址空间划分为0-3G是用户空间,3-4G是内核空间。而内核为了方便操作,需要将物理地址和内核虚拟空间建立线性映射的,而就因为内核只有1G空间,而物理内存有4G,是完全不能够线性映射的。这时候就将内核3G-3G+896M的地址线性映射到物理内存0-896M的区域。而896-4G的不能映射的区域就叫highmem_zone了。此处896是经典的x86架构的值,arm架构的值没研究。
- NORAML_ZONE: 16M-896M的区域就称为NORAML_ZONE了。
- 通常将HIGHMEM_ZONE的内存区域称为高端内存,896M以下的内存称为低端内存,低端内存是线性映射的

可以看看我的32位ubuntu机器,存在Noraml zone,DMA zone,HighMem zone。
64位系统
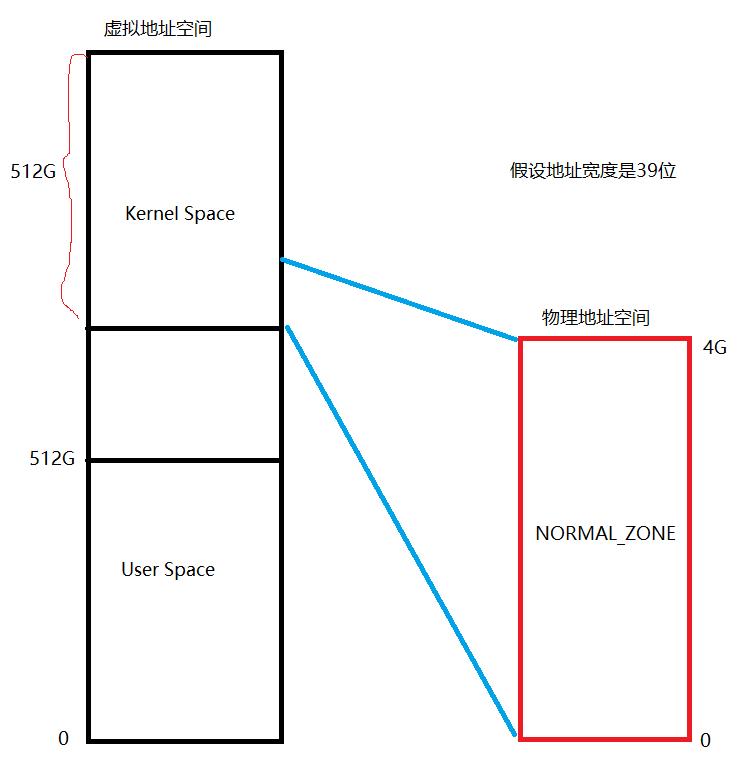
- 在64位系统上因为虚拟地址空间已经足够大了。比如当地址宽度的位数是39位的时候。用户空间和内核空间大小是一样大,大小是512G。
- 假设此时物理内存是4G,则整个4G都可以全部映射到内核虚拟地址区间的。所以说64位机器上已经不存在HIGHMEM_ZONE了。
- 而在x86的64位机器上还可能存在DMA,DMA_32的区域,用于DMA传输使用。
-
比如我的ubuntu机器,可以通过/proc/buddinfo看具体zone的信息
root@root-OptiPlex-7060:~$ cat /proc/buddyinfo
Node 0, zone DMA 3 3 1 1 3 2 0 0 1 1 3
Node 0, zone DMA32 4053 729 155 166 105 43 151 0 0 0 0
Node 0, zone Normal 33893 8921 6356 1472 1221 101 48 10 4 0 0 再比如看下我的一台ARm64的手机。
root:/ # cat /proc/buddyinfo
Node 0, zone Normal 12 7 148 52 114 39 16 8 5 5 117
Node 0, zone Movable 470 1135 880 340 35 8 4 2 3 0 653可以看到在64位机器上已经不存在HIGHMEM_ZONE了。只剩下一个NORAML_ZONE
ZONE_MOVABLE:用于内存碎片技术,意思就是当内存出现碎片的时候,为了调整出一个大得连续内存的时候,就需要将Moveablezone的内容做交换,换出一个大得连续的内存区域。
page
就是代表一个物理页,一个物理页用一个struct page在内核中表示。
struct page
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union
struct /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* zone_lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
;
struct /* slab, slob and slub */
union
struct list_head slab_list; /* uses lru */
struct /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
;
;
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
;
;
;
struct /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
;
struct /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
unsigned long _compound_pad_2;
struct list_head deferred_list;
;
struct /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
;
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
;
struct /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
unsigned long hmm_data;
unsigned long _zd_pad_1; /* uses mapping */
;
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
;
union /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
;
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
可以看到struct page结构体里面基本都是联合体,就是为了节省空间。因为物理页很多 ,则为了表示物理页就需要很多的page,而page是需要占用内存的。所以page结构体采用了联合体这种结构来组织。但是可读性很差。
Page Frame
为了描述一个物理page,内核使用struct page结构来表示一个物理页。假设一个page的大小是4K的,内核会将整个物理内存分割成一个一个4K大小的物理页,而4K大小物理页的区域我们称为page frame
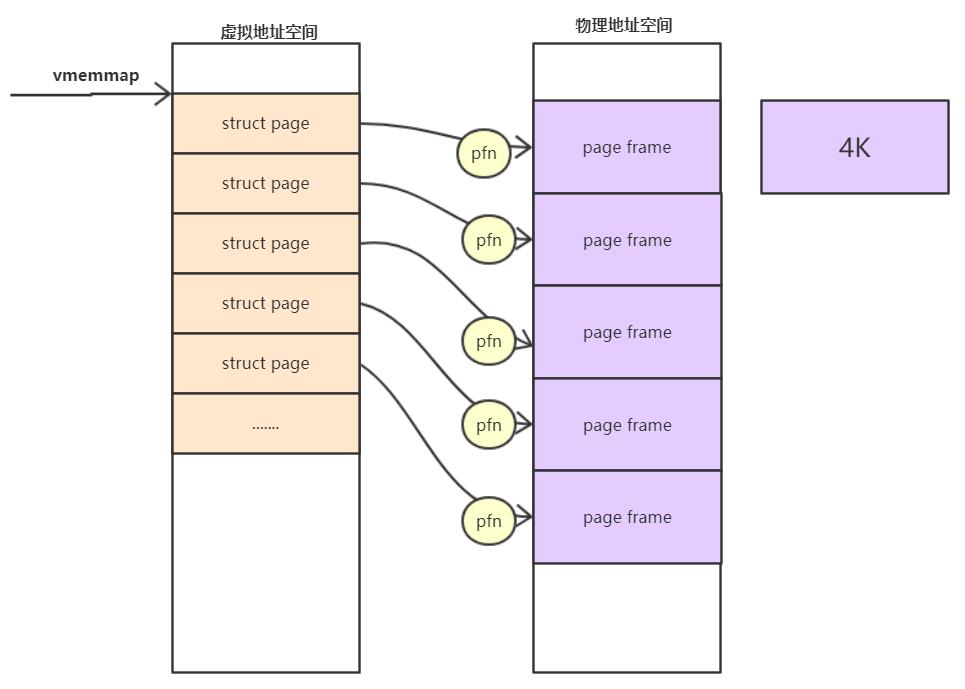
Page Frame Num(PFN)
将物理地址分成一块一块的大小,就比如大小是4K的话,将一个物理页的区域我们称为page frame, 而对每个page frame的编号就称为PFN.
物理地址和pfn的关系是:物理地址>>PAGE_SHIFT = pfn
pfn和page的关系:
内核中支持了好几个内存模型:CONFIG_FLATMEM(平坦内存模型)CONFIG_DISCONTIGMEM(不连续内存模型)CONFIG_SPARSEMEM_VMEMMAP(稀疏的内存模型)目前ARM64使用的稀疏的类型模式
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)刚开机的时候,内核会将整个struct page映射到内核虚拟地址空间vmemmap的区域,所以我们可以简单的认为struct page的基地址是vmemmap,则:
vmemmap+pfn的地址就是此struct page对应的地址.
总结:
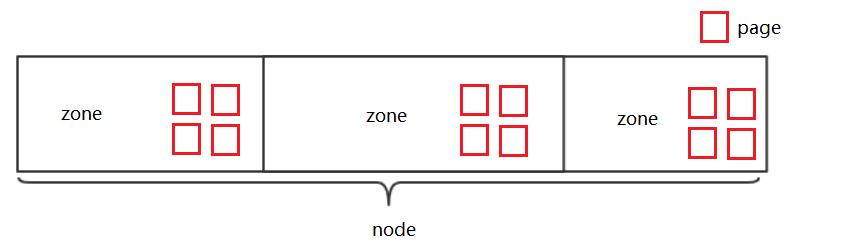
一个物理内存分为好几个node,每个node存在好几个zone,每个zone中细分为page大小。
以上是关于物理内存是如何组织管理的的主要内容,如果未能解决你的问题,请参考以下文章