SLUB分配一个object的流程分析
Posted Loopers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SLUB分配一个object的流程分析相关的知识,希望对你有一定的参考价值。
在上一节 我们清晰的知道了当调用kmem_cache_create之后系统会为我们分配一个名为slub_test的一个slab。这时候只是分配了kmem_cache,kmem_cache_cpu,kmem_cache_node结构,同时设置针对此object需要多少个page之类。
我们这节将分析当申请一个object的时候,应该是如何的分配。还是之前的例子,继续来分析当调用kmem_cache_alloc函数之后,代码的关键流程。
zhangsan = kmem_cache_alloc(slub_test, GFP_KERNEL);
if(zhangsan != NULL)
printk("alloc object success!\\n");
ret = 0;
通过kmem_cache_alloc函数最终会调用到slab_alloc函数
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr);
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
void *ret = slab_alloc(s, gfpflags, _RET_IP_);
trace_kmem_cache_alloc(_RET_IP_, ret, s->object_size,
s->size, gfpflags);
return ret;
- 参数s:就是我们创建好的slab
- gfpflasg: 就是分配内存时的一些掩码,比如我们kmalloc经常使用的是GFP_KERNEL
static __always_inline void *slab_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr)
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
redo:
do
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node)))
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
else
void *next_object = get_freepointer_safe(s, object);
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid))))
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
- 这个函数分为快车道和慢车道。快车道就是当前cpu上的kmem_cache_cpu里的freelist有可用的object,有的话直接分配此object。慢车道就是:当前cpu的freelist中没有可用的object。我们第一次申请object则进入的就是慢车道、
- 快车道很简单:直接从kmem_cache_cpu的freelist中获取一个object返回即可。慢车道就比较麻烦,需要申请page,然后根据page大小设置freelist的指针等。重点关注下慢车道。
- 确保当前在同一个cpu上操作,在开启抢占的情况下。
- 获取当前cpu的freelist链表,以及page。当第一次分配object的时候这两值都为null,则就进入到__slab_alloc函数中。设置状态为ALLOC_SLOWPATH慢速分配。
- 如果是快速分配,则通过get_freepointer_safe下一个object的指针next_object
- 通过this_cpu_cmpxchg_double函数重新设置freelist的指针,以及tid
- 如果flag存在__GFP_ZERO,则将此object清为0即可。
我们现在总结下分配一个object需要经历的4中选择:
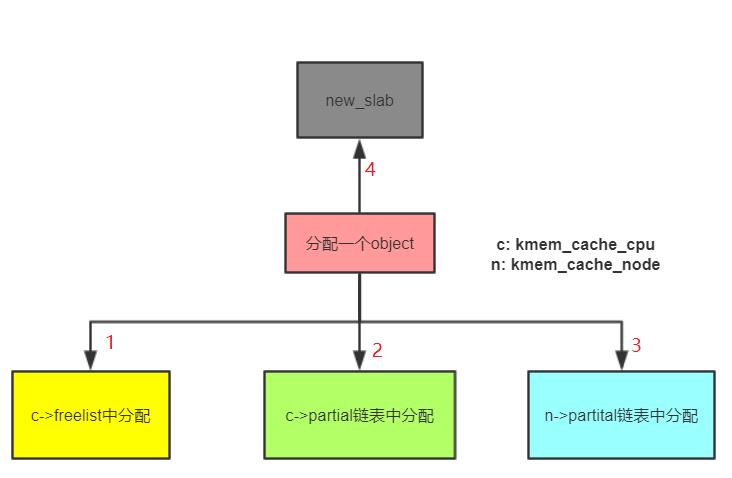
- 先从kmem_cache_cpu→ freelist中分配,如果freelist为null
- 接着去kmem_cache_cpu→partital链表中分配,如果此链表为null
- 接着去kmem_cache_node→partital链表分配,如果此链表为null
- 这就需要重新分配一个slab了。
接下来分为四个步骤去分析各个情况下的分配object
从kmem_cache_cpu→freelist中分配
这种分配就是我们前面提到的快车道分配,操作很简单,直接获取freelist所指的object,然后计算下一个object。重新设置freelist和tid的值即可。
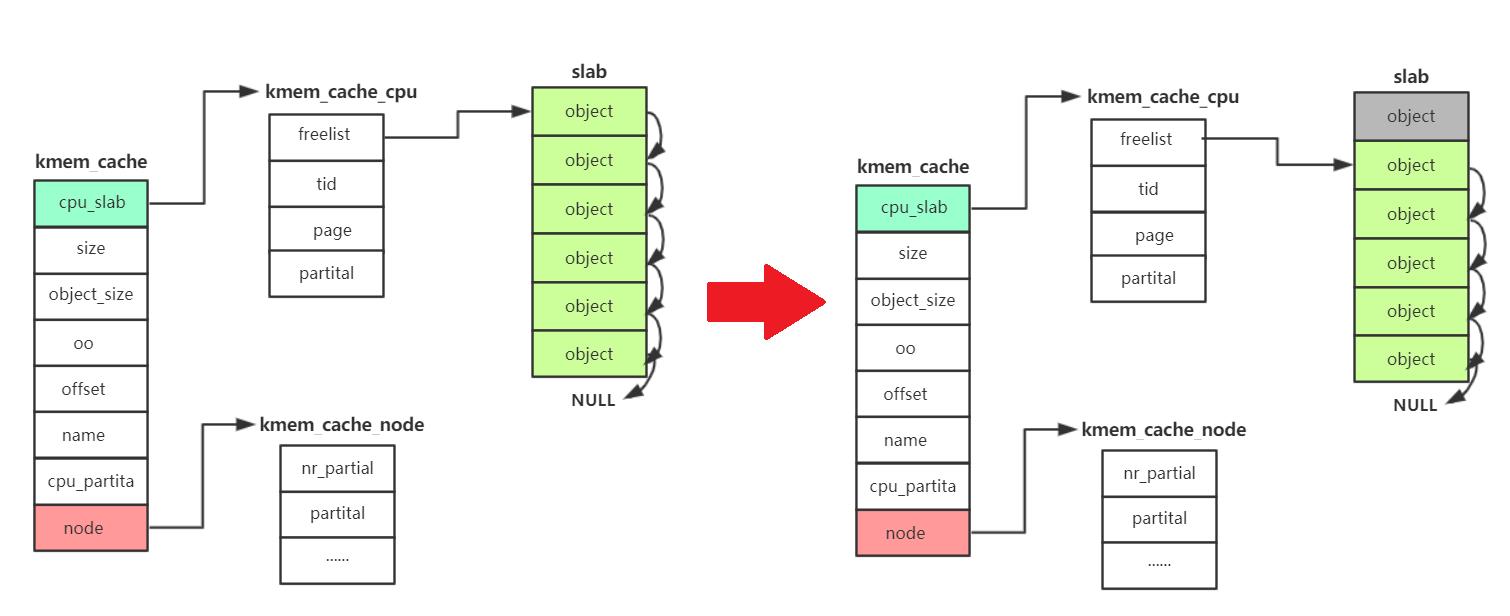
从kmem_cache_cpu→partital中分配
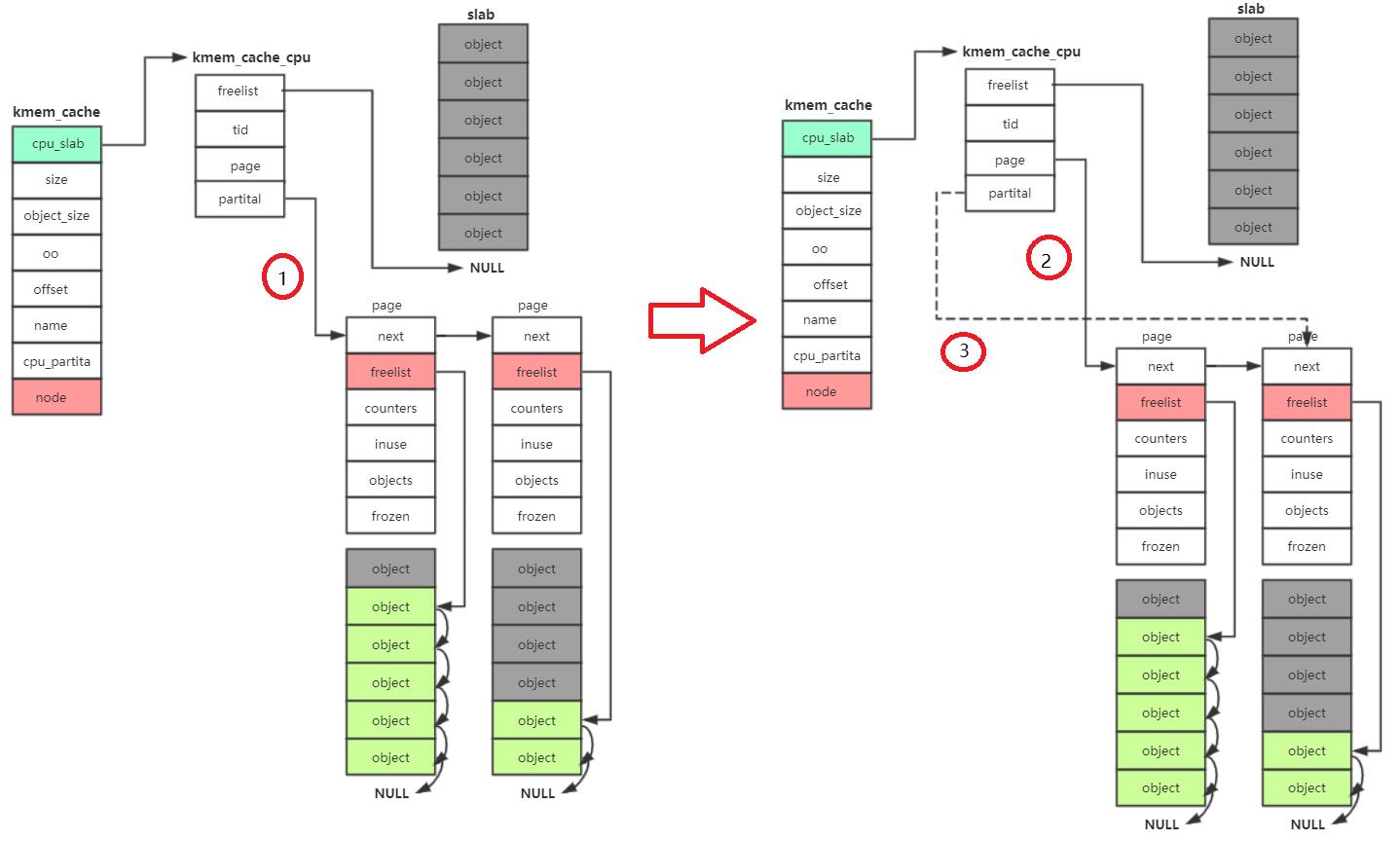
- 第一步将kmem_cache_cpu->partital赋值给kmem_cache_cpu→page节点
- 第二步kmem_cache_cpu→partial = kmem_cache_cpu→page->next,这样一来partital就指向下一个page
- 对应的代码如下
#define slub_percpu_partial(c) ((c)->partial)
#define slub_set_percpu_partial(c, p) \\
( \\
slub_percpu_partial(c) = (p)->next; \\
)
if (slub_percpu_partial(c))
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;

- 将page中的freelist设置给kmem_cache_cpu的freelist
- 将page→freelist设置为NULL
- 然后和快速车道一样,设置下一个freelist的指针,以及tid,返回当前的object
- 代码如下:
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
struct page new;
unsigned long counters;
void *freelist;
do
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
VM_BUG_ON(!new.frozen);
new.inuse = page->objects;
new.frozen = freelist != NULL;
while (!__cmpxchg_double_slab(s, page,
freelist, counters,
NULL, new.counters,
"get_freelist"));
return freelist;
load_freelist:
VM_BUG_ON(!c->page->frozen);
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;至此从kmem_cache_cpu的partial链表中获取object完毕了。
从kmem_cache_node→partital中分配
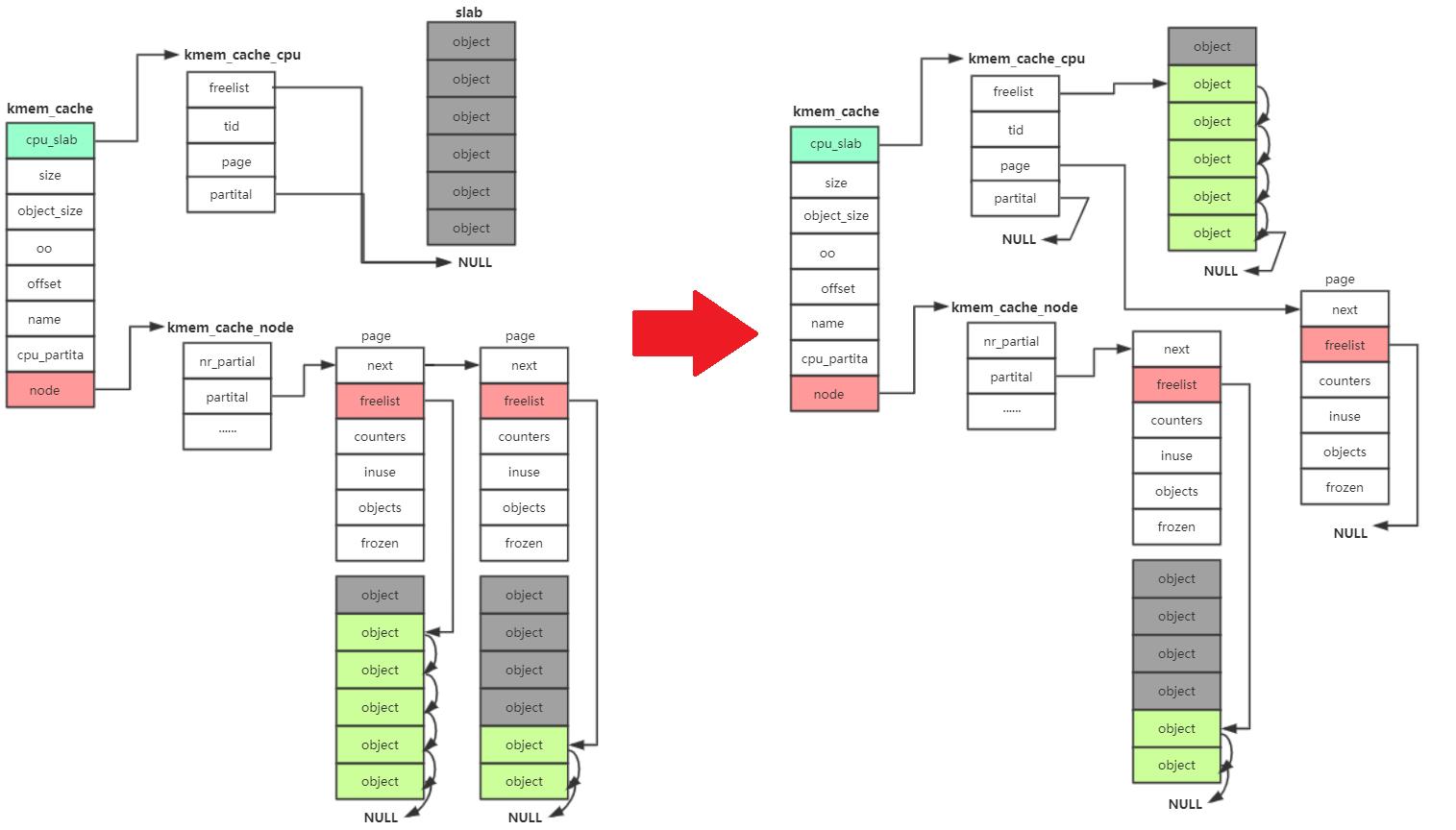
- 当kmem_cache_cpu的freelist和partital链表都没有可用的object的时候,就去kmem_cache_node去寻找可用的object
- 将kmem_cache_node中的page→freelist设置为null,然后将此page从lru链表去remove掉
- 将remove掉的page设置到kmem_cache_cpu的page中
- 设置kmem_cache_cpu的freelist到当前从kmem_cache_node remove的freelist中去
- 涉及的代码如下:
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
struct page *page, *page2;
void *object = NULL;
unsigned int available = 0;
int objects;
/*
* Racy check. If we mistakenly see no partial slabs then we
* just allocate an empty slab. If we mistakenly try to get a
* partial slab and there is none available then get_partials()
* will return NULL.
*/
if (!n || !n->nr_partial)
return NULL;
spin_lock(&n->list_lock);
list_for_each_entry_safe(page, page2, &n->partial, lru)
void *t;
if (!pfmemalloc_match(page, flags))
continue;
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object)
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
else
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break;
spin_unlock(&n->list_lock);
return object;
重新分配一个slab
终于经过了千方百计的救援,依旧没有找到可用的slab,则就通过new_slab函数重新分配一个新的slab。
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
if (gfpflags_allow_blocking(flags))
local_irq_enable();
flags |= s->allocflags;
/*
* Let the initial higher-order allocation fail under memory pressure
* so we fall-back to the minimum order allocation.
*/
alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min))
alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~(__GFP_RECLAIM|__GFP_NOFAIL);
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
goto out;
stat(s, ORDER_FALLBACK);
page->objects = oo_objects(oo);
order = compound_order(page);
page->slab_cache = s;
start = page_address(page);
if (unlikely(s->flags & SLAB_POISON))
memset(start, POISON_INUSE, PAGE_SIZE << order);
shuffle = shuffle_freelist(s, page);
if (!shuffle)
for_each_object_idx(p, idx, s, start, page->objects)
setup_object(s, page, p);
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
page->freelist = fixup_red_left(s, start);
page->inuse = page->objects;
page->frozen = 1;
return page;
- 通过设置flag去申请page,同时要根据object的需要的order去申请page
- 调用此函数alloc_slab_page去申请一页,至于怎么申请的我们在后面的buddy内容里详细描述
- 假如现在申请失败了,看看他还是不放弃,还要在尝试一次,去更低的order去申请page,如果再次失败,则宣布退出。如果申请成功,我们就拿到这一页page
- 获取到slab的object数,以及设置当前page对应的kmem_cache,获取到page的开始地址,然后如果开机SLAB_POISON flasg,则设置申请的page内容初始化为0x5a, 用于debug使用
- 如果开启了随机的的freelist,随机的freelist的意思就是下一个object的地址是随机的。则会进到shuffle_freelist设置各个object的地址,形成一个单链表
- 如果没有开启的,则会通过外面的一个for循环,设置下一个object的地址,下一个object的地址就等于curr+object_size
- page->inuse = page→objects; 就是我们在第一节的时候说刚开始创建的object insue=objects的
- 返回当前申请好的page
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO));
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page)
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
else
freelist = NULL;
return freelist;
- 将申请好的page的freelist给返回去给kmem_cache_cpu的freelist,设置当前page的freelist为NULL
- 然后将当前page设置给kmem_cache_cpu的page
- 至此当申请一个page的时候 各个情况就说明完了
以上是关于SLUB分配一个object的流程分析的主要内容,如果未能解决你的问题,请参考以下文章