备战数学建模29 & 科研必备 Python之pandas时间序列
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了备战数学建模29 & 科研必备 Python之pandas时间序列相关的知识,希望对你有一定的参考价值。
目录
1-pandas与时间序列
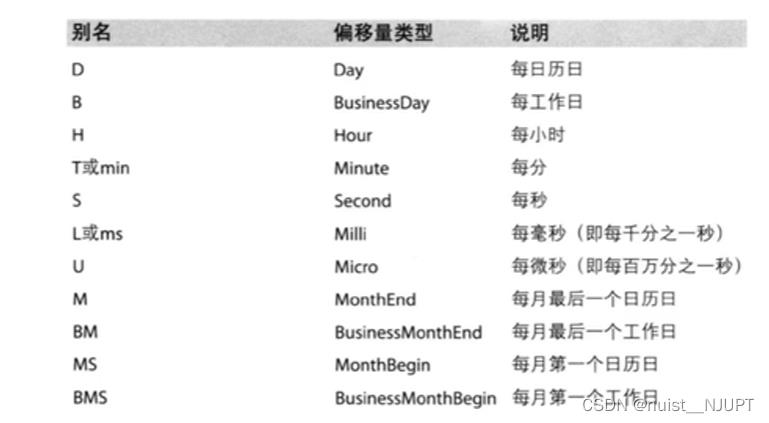
无论在什么行业,时间序列都是一种十分重要的数据形式,很多统计数据以及数据规律也都和时间序列有着十分重要的关系,而且pandas在处理时间序列是非常简单的。下面我们看下生成时间序列的方法:
生成一段时间的python代码如下:
import pandas as pd
#生成一段时间范围
t = pd.date_range(start="20211230",end="20220131",freq="D") #D代表天,每隔1天取一个
t1 = pd.date_range(start="20211230",end="20220131",freq="10D")#每隔10天取一个
t2 = pd.date_range(start="20211230",periods=10,freq="D") #生成10个天
t3 = pd.date_range(start="20211231",periods=10,freq="M") #生成10个月份
t4 = pd.date_range(start="20211231",periods=10,freq="H") #生成10个小时得时间
print(t)
print(t1)
print(t2)
print(t3)
print(t4)
print("*" * 100)
pandas重采样:将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据称为降采样,将低频率数据转化为高频率数据为升采样。pandas提供一个resample()方法来帮助我们实现频率转化。
那么下面我们假设有911数据,现在想完成如下两个问题:
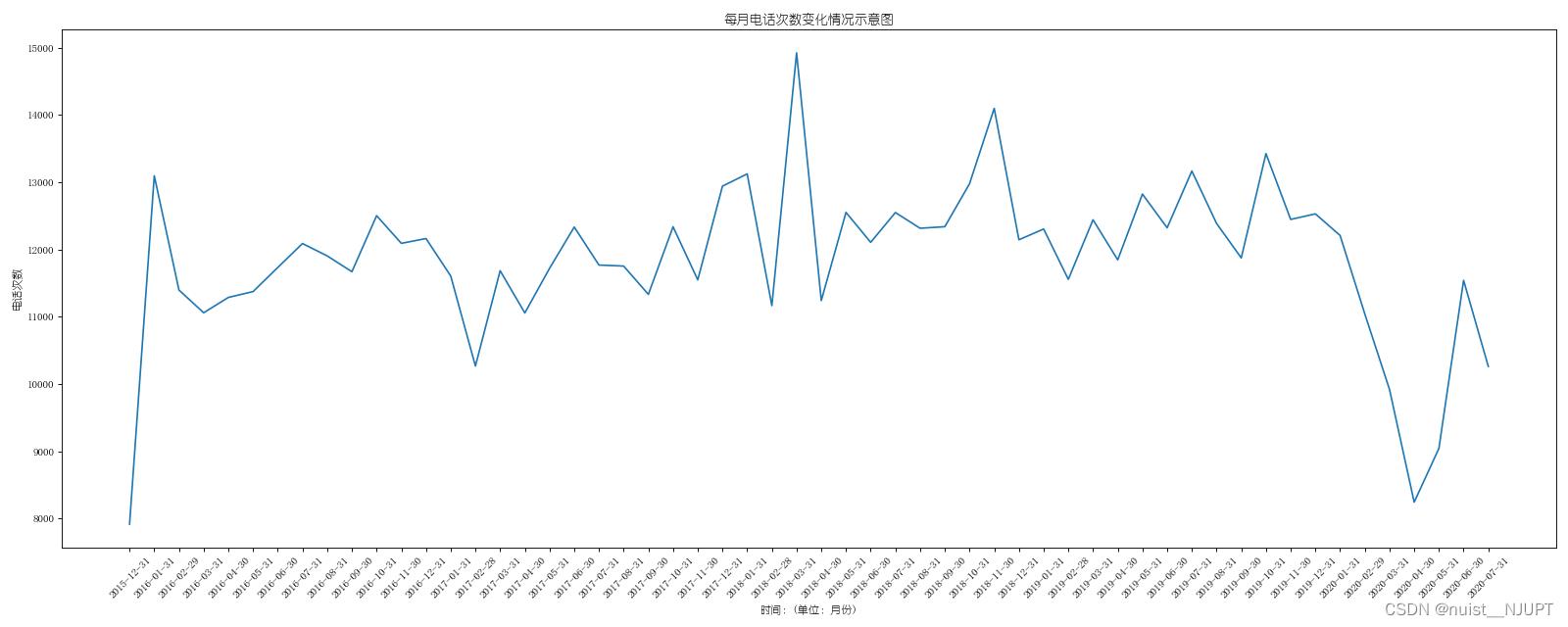
1-统计出911数据中不同月份电话次数的变化情况;
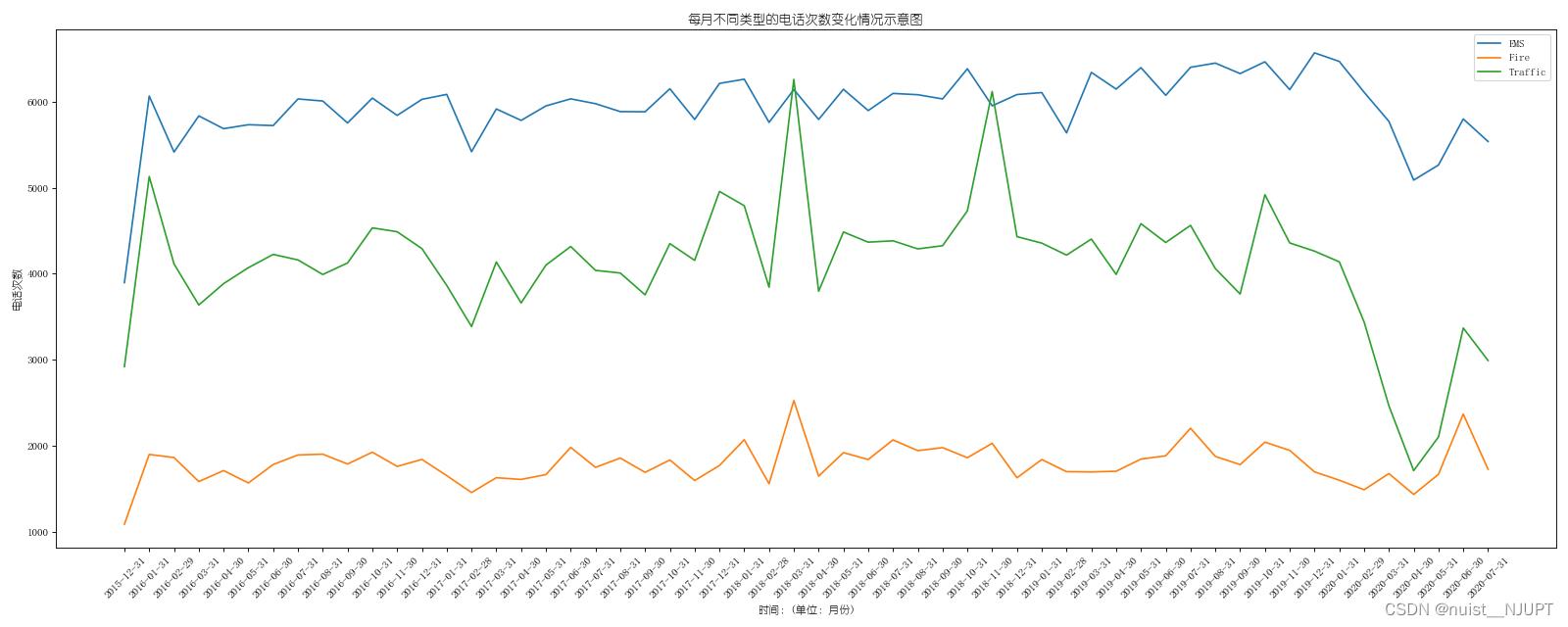
2-统计出911数据中不同月份不同类型的电话次数的变化情况;
问题1的pytho代码如下:
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font", family='YouYuan')
df = pd.read_csv("./data/911.csv")
#把时间序列转换为时间类型,设置为索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
#统计出911数据中不同月份的电话次数
count_by_month = df.resample("M").count()["title"]
print(count_by_month)
#画图
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y-%m-%d") for i in _x]
plt.figure(figsize=(20,8), dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.xlabel("时间:(单位:月份)")
plt.ylabel("电话次数")
plt.title("每月电话次数变化情况示意图")
plt.show()
问题1绘制的图形如下所示:
问题2的python代码如下所示:
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
import numpy as np
matplotlib.rc("font", family='YouYuan')
df = pd.read_csv("./data/911.csv")
#把时间序列转换为时间类型,设置为索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
plt.figure(figsize=(20,8), dpi=80)
df.set_index("timeStamp",inplace=True)
#分组
for group_name, group_data in df.groupby(by="cate"):
#对不同的分类都进行绘图
count_by_month = group_data.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y-%m-%d") for i in _x]
plt.plot(range(len(_x)),_y,label=group_name)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.legend(loc="best")
plt.xlabel("时间:(单位:月份)")
plt.ylabel("电话次数")
plt.title("每月不同类型的电话次数变化情况示意图")
plt.show()绘制的图形如下:
2-pandas案例
假设现在我们有北京、上海、广州、深圳和沈阳5个城市的空气质量数据,请绘制出5个城市的PM2.5随时间变化的情况,观察这组数据的时间结构,并不是字符串,这个时候我们该怎么办呢?我们可以把分开的时间字符串通过PeriodIndex()方法转换为pandas的时间类型,然后就可以将时间序列设置成索引,进行重采样,然后绘图。
绘制出北京的空气质量随着时间变化数据,其余城市不再赘述,python代码如下所示:
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
import numpy as np
matplotlib.rc("font", family='YouYuan')
df = pd.read_csv("./PM2.5/BeijingPM20100101_20151231.csv")
#把分开的时间字符串通过PeriodIndex()方法转换为pandas的时间类型
period = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],hour=df["hour"],freq="H")
df["datetime"] = period
print(df.head(10))
#把datetime设置为索引
df.set_index("datetime",inplace=True)
#进行降采样
df = df.resample("7D").mean()
#处理NAN数据,直接删除
data = df["PM_US Post"].dropna()
#画图
_x = data.index
_y = data.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)), _y)
plt.xticks(range(0,len(_x),10),list(_x)[::10],rotation=45)
plt.xlabel("时间:(单位:月份)")
plt.ylabel("PM2.5指数")
plt.title("2010年至2015年北京PM2.5变化情况示意图")
plt.show()
绘制的图像如下:

以上是关于备战数学建模29 & 科研必备 Python之pandas时间序列的主要内容,如果未能解决你的问题,请参考以下文章
备战数学建模27 & 科研必备 -Python之数值型数据处理numpy
备战数学建模43-决策树&随机森林&Logistic模型(攻坚站7)