Kafka Session
Posted 老邋遢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka Session相关的知识,希望对你有一定的参考价值。
Kafka Session
文章目录
本文源于笔者一次集成外部Kafka实例的总结,
所以侧重点会放到landing上面,
比如一些关键的知识点和踩到的坑。
基础知识点会一笔带过,有兴趣可以参考文末引用部分的书籍和博客自行取阅。
1. What’s Kafka

Apache Kafka® 是 一个分布式流处理平台.
上面是Kafka官方对其自身的一个简练概括,
分布式(distributed)和平台(platform)不用过多解释,
对于初次接触Kafka的人来说, 流处理(streaming)是比较难以理解的。
引用知乎中的一段话(本文所有引用都可以在文末找到原文链接,后面不再赘述):
流数据是指由数千个数据源持续生成的数据,通常也同时以数据记录的形式发送,规模较小(约几千字节)。流数据包括多种数据,例如客户使用您的移动或 Web 应用程序生成的日志文件、网购数据、游戏内玩家活动、社交网站信息、金融交易大厅或地理空间服务,以及来自数据中心内所连接设备或仪器的遥测数据。
总结一下,所谓流数据就是持续生成的数据。
所有的流处理平台都具备一下三种特性, Kafka亦复如是:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
2. Why Kafka
在此之前,我们可以将现在主流的消息队列方案予以对比(一些冷门的MQ如ZeroMQ不在此列)
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| PRODUCER-COMSUMER | 支持 | 支持 | 支持 | 支持 |
| PUBLISH-SUBSCRIBE | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持,JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级 | 万级 | 十万级 | 单机万级 |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
可见Kafka在可用性和吞吐量上占有绝对的优势。
其优势决定了Kafka很适合在高负载下提供稳定的服务,比如日志的采集、大数据中间件等。
Kafka适用场景
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
3. Tech Points
3.1 说一说什么是Kafka中的 ISR、OSR?
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度的同步”是指可忍受的滞后范围,这个范围可以通过参数进行配置。与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即AR=ISR,OSR集合为空。
leader副本负责维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中有follower副本“追上”了leader副本,那么leader副本会把它从OSR集合转移至ISR集合。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
3.2 说一说什么是Kafka中的LSO、LEO、HW?
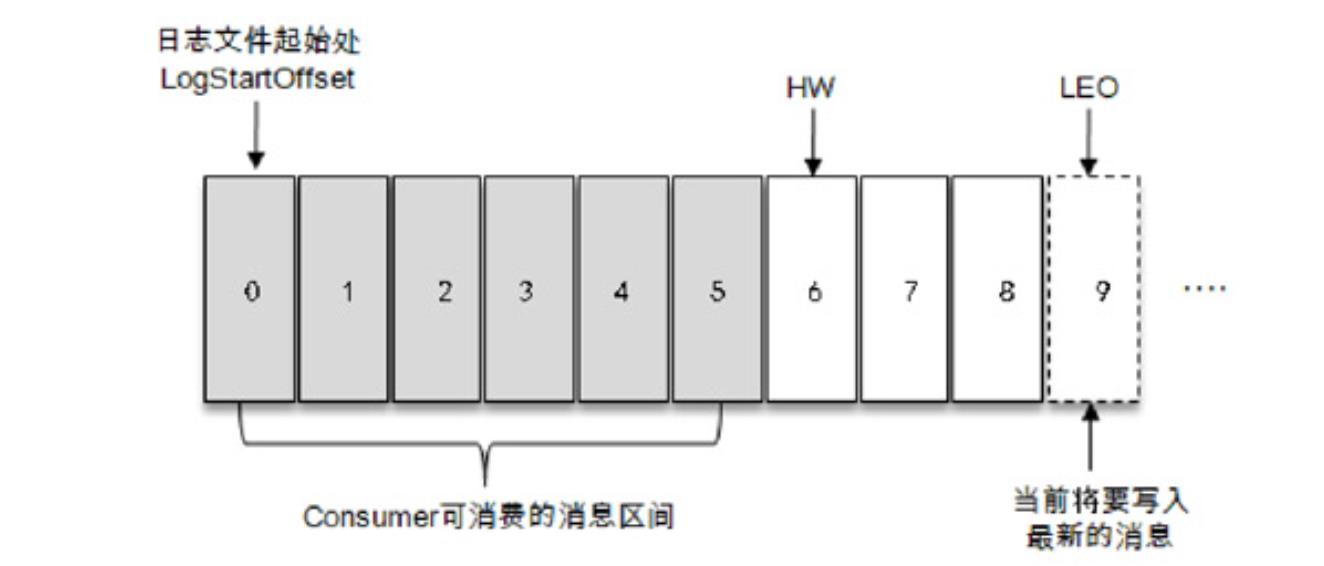
ISR与HW和LEO也有紧密的关系。HW是High Watermark的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
如图所示,它代表一个日志文件,这个日志文件中有 9 条消息,第一条消息的 offset(LogStartOffset)为0,最后一条消息的offset为8,offset为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的HW为6,表示消费者只能拉取到offset在0至5之间的消息,而offset为6的消息对消费者而言是不可见的。
LEO是Log End Offset的缩写,它标识当前日志文件中下一条待写入消息的offset,图1-4中offset为9的位置即为当前日志文件的LEO,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费者而言只能消费HW之前的消息
3.3 Kafka Producer的常见参数
有点多,罗列一个常见且重要的,剩下的在文末书籍第二章有很多:
acks
这个参数用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的。acks 是生产者客户端中一个非常重要的参数,它涉及消息的可靠性和吞吐量之间的权衡。
- acks=1。默认值即为1。生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应。如果消息无法写入leader副本,比如在leader 副本崩溃、重新选举新的 leader 副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重发消息。如果消息写入leader副本并返回成功响应给生产者,且在被其他follower副本拉取之前leader副本崩溃,那么此时消息还是会丢失,因为新选举的leader副本中并没有这条对应的消息。acks设置为1,是消息可靠性和吞吐量之间的折中方案。
- acks=0。生产者发送消息之后不需要等待任何服务端的响应。如果在消息从发送到写入Kafka的过程中出现某些异常,导致Kafka并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks 设置为 0 可以达到最大的吞吐量。
- acks=-1或acks=all。生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。在其他配置环境相同的情况下,acks 设置为-1(all)可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有leader副本,这样就退化成了acks=1的情况。要获得更高的消息可靠性需要配合 min.insync.replicas 等参数的联动
3.4 有没有对Kafka Producer参数进行过调优?
首先这个问题是有坑的,因为如果你不足够了解Kafka的话,很有可能忽略一些联动参数而导致错误。
以下是一些常见的生产者联动参数:
- acks=-1或acks=all。虽然这个配置可以达到最高的消息可靠性,但是ISR中如果只有leader副本的情况下会退化为acks=1,需要配合min.insync.replicas 等参数的联动。
- max.request.size。这个参数用来限制生产者发送消息的最大值,默认为1M,但是不能单纯加大这个参数的设置,需要配合broker端的message.max.bytes参数联动。
- retries。这个参数是生产者重试次数,默认为0即发生异常不重试。如果要动这个参数,一般需要联动retry.backoff.ms,即重试间隔时间。
- compression.type。指定压缩的类型,默认不压缩,如果对延时要求较高不建议动这个参数。
- receive.buffer.bytes。Socket接收缓冲区大小,默认32KB,如果Producer与Kafka处于不同的机房,则可以适地调大这个参数值。
所以没有系统的学习或者生产上的验证干脆就说没有调优过就可以了。
4. Landing Implementation
这是本文重点,先说一下我们的需求
requirement
我们的系统需要整合一个外部系统来获取单一可信的数据,
集成方式为监听外部系统部署于AWS MSK(Managed Stream for Kafka)的队列。
为了安全起见,我们使用的是AWS提供的IAM认证。
1. 创建新工程
这一步没有什么特别需要注意的地方,
依旧是使用Spring Initializer初始化一个SpringBoot项目,
然后引入所有工程都有的一些公共组件。
我们用的构建工具是Gradle。
2. 封装连接到MSK的公共starter
因为后续还会有一些工程需要用监听AWS消息队列的方式集成,
所以将顶层逻辑提取出来,抽一个starter是很有必要的。
首先梳理出我们的一些核心starter功能:
- 因为starter中需要对Kafka有一些默认的配置设置,所以需要将这些配置封装进我们自定义的Bean
- 尽量将Listener上程序可以推导的参数用反射注入进去,提升易用性
- 让消息监听方法支持链路追踪
- 做到使用者无感(这个已有方案,最终因为effort原因没有落地)
有了核心功能的需求,
我们就可以着手开发kafka-starter了。
创建一个resources/META-INF/spring.factories文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.daimler.otr.message.configuration.KafkaDatasourceConfiguration
创建KafkaDatasourceConfiguration配置类
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory()
Assert.notNull(applicationName, "This application does not have a valid application name.");
initKafkaCommonProperties();
ConcurrentKafkaListenerContainerFactory<String, String> factory
= new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(isBatchListener);
factory.setBatchErrorHandler((e, consumerRecords) ->
log.error("error when consuming: , records are: ", e.getMessage(), consumerRecords, e));
return factory;
private void initKafkaCommonProperties()
if (isKafkaBootstrapServersNone())
throw new IllegalArgumentException("required spring.kafka.bootstrap-servers not configured.");
Map<String, String> properties = kafkaProperties.getProperties();
properties.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, SASL_SSL);
properties.put(SaslConfigs.SASL_MECHANISM, AWS_MSK_IAM);
properties.put(SaslConfigs.SASL_JAAS_CONFIG, IAM_LOGIN_MODULE);
properties.put(SaslConfigs.SASL_CLIENT_CALLBACK_HANDLER_CLASS, IAM_CLIENT_CALLBACK_HANDLER);
private boolean isKafkaBootstrapServersNone()
return CollectionUtils.isEmpty(kafkaProperties.getBootstrapServers());
@Bean
public ConsumerFactory<String, String> consumerFactory()
KafkaProperties.Consumer consumer = kafkaProperties.getConsumer();
consumer.setMaxPollRecords(maxPollRecords);
consumer.setFetchMaxWait(Duration.ofSeconds(fetchMaxWait));
consumer.setKeyDeserializer(StringDeserializer.class);
consumer.setValueDeserializer(JsonDeserializer.class);
consumer.setGroupId(StringUtils.isEmpty(groupId) ? applicationName : groupId);
consumer.setAutoOffsetReset(autoOffsetReset);
consumer.getProperties().put(TRUSTED_PACKAGES, trustedPackages);
consumer.getProperties().put(USE_TYPE_INFO_HEADERS, AWS_JSON_TYPE_HEADERS);
return new DefaultKafkaConsumerFactory<>(kafkaProperties.buildConsumerProperties());
这里主要是创建出我们自己的两个工厂Bean(ConcurrentKafkaListenerContainerFactory、ConsumerFactory),
然后设置一些通用的参数,
其中AWS_JSON_TYPE_HEADERS常量对应的值为spring.json.use.type.headers=false,
这是为了在json反序列化的时候忽略请求头中携带的对象信息。
若携带了对象信息例如package.xxx.xxx.A,那么反序列化的时候就会去找对应包下的对应对象,
显然这个对象在本地的目录结构不一定和远端一致,所以我们需要移除反序列化时远端带过来的type header。
上述问题除了移除type header外,我们还需要设置对应的本地type,形如:
spring.json.value.default.type=package.xxx.xxx.A
这样就能正常的反序列化了,其实这么设置等价于以下的代码:
@KafkaListener(topics = "topic",properties =
"spring.json.use.type.headers=false",
"spring.json.value.default.type=package.xxx.xxx.A"
)
public void listen(List<A> messages)
//TODO 可以将消息写入数据库, 或者做其他处理
而统一设置后,使用我们starter的小伙伴只需要这么编码即可
@KafkaListener(topics = "topic")
public void listen(List<A> messages)
//TODO 可以将消息写入数据库, 或者做其他处理
但是这样做会存在一个问题:我们"spring.json.value.default.type=package.xxx.xxx.A"后面的对象是根据监听队列的变化而变化的
所以我们需要动态的去获取参数列表中的对象ClassName,然后拼接好了给注解反射设置进去。
最开始笔者想用切面实现,但是最后发现实现不了,看源码可以发现spring-kafka是通过Processor实现的
下图为部分源码
并且这个processor的优先级为最低,所以我们可以在spring-kafka操作KafkaListener这个注解之前把
"spring.json.value.default.type=package.xxx.xxx.A"设置进去
以下是我实现的BeanPostProcessor
@Slf4j
@Component
@SuppressWarnings("PMD.AssignmentInOperand")
public class KafkaJsonTypeBeanProcessor implements BeanPostProcessor, Ordered
private static final String JSON_DEFAULT_TYPE_PREFIX = "spring.json.value.default.type=";
@Override
public Object postProcessAfterInitialization(final Object bean, final String beanName)
Class<?> targetClass = AopUtils.getTargetClass(bean);
Map<Method, Set<KafkaListener>> annotatedMethods = MethodIntrospector.selectMethods(targetClass,
(MethodIntrospector.MetadataLookup<Set<KafkaListener>>) method ->
Set<KafkaListener> listenerMethods = findListenerAnnotations(method);
return listenerMethods.isEmpty() ? null : listenerMethods;
);
annotatedMethods.forEach(this::processKafkaListener);
return bean;
private void processKafkaListener(Method method, Set<KafkaListener> v)
v.parallelStream().forEach(listener ->
String[] properties = listener.properties();
String[] appendedArray = appendJsonDefaultTypeToStringArray(properties, method);
try
InvocationHandler invocationHandler = Proxy.getInvocationHandler(listener);
Field declaredField = invocationHandler.getClass().getDeclaredField("memberValues");
declaredField.setAccessible(true);
Map memberValues = (Map) declaredField.get(invocationHandler);
memberValues.put("properties", appendedArray);
catch (NoSuchFieldException e)
log.error("no such field error", e);
catch (IllegalAccessException e)
log.error("illegal access error", e);
);
private String[] appendJsonDefaultTypeToStringArray(String[] properties, Method method)
List<String> list = Lists.newArrayList(properties);
if (isJsonDefaultTypeExists(list))
return properties;
Type arg = method.getGenericParameterTypes()[0];
Type[] p;
if (arg instanceof ParameterizedType && (p = ((ParameterizedType) arg).getActualTypeArguments()).length > 0)
list.add(JSON_DEFAULT_TYPE_PREFIX + p[0].getTypeName());
else
list.add(JSON_DEFAULT_TYPE_PREFIX + arg.getTypeName());
return list.toArray(String[]::new);
private boolean isJsonDefaultTypeExists(List<String> list)
return list.stream().anyMatch(item -> item.contains(JSON_DEFAULT_TYPE_PREFIX));
private Set<KafkaListener> findListenerAnnotations(Method method)
Set<KafkaListener> listeners = new HashSet<>();
KafkaListener ann = AnnotatedElementUtils.findMergedAnnotation(method, KafkaListener.class);
if (ann != null)
listeners.add(ann);
KafkaListeners anns = AnnotationUtils.findAnnotation(method, KafkaListeners.class);
if (anns != null)
listeners.addAll(Arrays.asList(anns.value()));
return listeners;
@Override
public int getOrder()
return Ordered.LOWEST_PRECEDENCE - 10;
整个Processor就干了一件事,找出所有打了KafkaListener注解的方法,然后把
形如"spring.json.value.default.type=package.xxx.xxx.A"这个property给注解设置进去。
这里注意不能直接拿KafkaListener对象给其设值,因为Spring给每个注解生成了一个代理对象,
我们需要去拿这个代理对其设值(参考上面的processKafkaListener()方法)
最后加个切面,给每次消费消息加个request-id用于链路追踪即可
@Aspect
@Component
public class MdcAspect
public static final String REQUEST_ID = "X-SERVICE-REQUEST-ID";
@Pointcut("@annotation(org.springframework.kafka.annotation.KafkaListener)")
public void kafkaListenerAspect()
@Before("kafkaListenerAspect()")
public void after()
MDC.put(REQUEST_ID, UUID.randomUUID().toString());
3. 新工程引入starter后进行测试
这一步可以通过让外部系统的Dev介入联调,
来验证我们的starter以及代码逻辑是否正确(不得不说联调是最费时费力的一步哈哈)。
5. Issues
5.1 无限消费失败消息
在联调过程中发现有一个offset怎么也消费不过去,一直在重试。
最终发现是因为我们使用的是batch消费的模式,但是没有配置BatchErrorHandler
在ConcurrentKafkaListenerContainerFactory的Bean里加上即可
@Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() Assert.notNull(applicationName, "This application does not have a valid application name."); initKafkaCommonProperties(); ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(isBatchListener); //这里 factory.setBatchErrorHandler((e, consumerRecords) -> log.error("error when consuming: , records are: ", e.getMessage(), consumerRecords, e)); return factory;
References
- 《深入理解Kafka:核心设计与实践原理》 朱忠华 电子工业出版社 2019 第一版
- Apache Kafka 中文文档
- 知乎-什么是流数据
- 常用消息队列介绍和对比
- MQ的四种应用场景
以上是关于Kafka Session的主要内容,如果未能解决你的问题,请参考以下文章