Spark Streaming 流式处理(第三集)
Posted 技术能量站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming 流式处理(第三集)相关的知识,希望对你有一定的参考价值。
1. 前言
1.1 传统流处理系统架构
流处理架构的分布式流处理管道执行方式是,首先用数据采集系统接收来自数据源的流数据,然后在集群上并行处理数据,最后将处理结果存放至下游系统。
在大数据时代,随着数据规模的不断扩大,以及越来越复杂的实时分析,这个传统的架构面临着严峻的挑战。
- 故障恢复问题
数据越庞大,出现结点故障与结点运行变慢情况的概率也越高。因此,系统要是能够实时给出结果,就必须能够自动修复故障。但是在传统流处理系统中,在这些工作结点静态分配的连续算子要迅速完成这项工作仍然是个挑战。 - 负载均衡问题
在连续算子系统中,工作结点间的不平衡分配加载会造成部分结点性能的运行瓶颈。这些问题更常见于大规模数据与动态变化的工作量情况下。为了解决这个问题,需要系统必须能够根据工作量动态调整结点间的资源分配。 - 支持统一的流处理与批处理及交互工作的需求
在许多用例中,与流数据的交互或者与静态数据集的结合是很有必要的。这些都很难在连续算子系统中实现,当系统动态地添加新算子时,并没有为其设计临时查询功能,这样大大地削弱了用户与系统的交互能力。因此需要一个能够集成批处理、流处理与交互查询功能的引擎。 - 高级分析能力的需求
一些更复杂的工作需要不断学习和更新数据模型,或者利用 SQL 查询流数据中最新的特征信息。因此,这些分析任务中需要有一个共同的集成抽象组件,让开发人员更容易地去完成他们的工作。
Spark Streaming 引入了一个新结构,即 DStream,它可以直接使用 Spark Engine 中丰富的库,并且拥有优秀的故障容错机制。
1.2 spark streaming 是什么
Spark Streaming 是核心 Spark API 的扩展,支持实时数据流的可扩展、高吞吐量、容错流处理。数据可以从许多来源(如 Kafka、Kinesis 或 TCP 套接字)提取,并且可以使用用高级函数(如map、reduce和)表示的复杂算法join进行处理window。最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。实际上,您可以将 Spark 的 机器学习和 图形处理算法应用于数据流。

在内部,它的工作原理如下。Spark Streaming 接收实时输入数据流,并将数据分批,然后由 Spark 引擎处理,分批生成最终的结果流。
Spark Streaming 提供了一种称为离散流或DStream的高级抽象,它表示连续的数据流。DStream 可以从来自 Kafka 和 Kinesis 等源的输入数据流创建,也可以通过对其他 DStream 应用高级操作来创建。在内部,一个DStream表示为一个 RDD 序列 。
1.3 spark streaming 的特性
- 易用性
Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。 - 容错性
Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。首先要明确一下Spak中RDD的容错机制,即每一个RDD都是个不可变的分布式可重算的数据集,它记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都可以使用原始输入数据经过转换操作重新计算得到。 - 易整合性
Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
1.4 数据维度分析
数据处理方式的角度
- 流式(Streaming)数据处理
- 批量(Batch)数据处理
数据处理延迟的长短
- 实时数据处理:毫秒级别
- 离线数据处理:小时 or 天级别
2. 夯实基础
2.1 整体架构
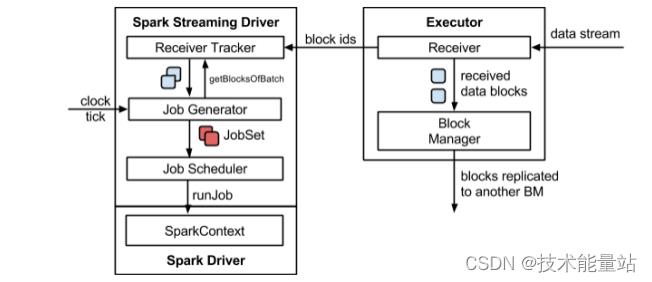
2.2 核心概念
- 离散流(Discretized Stream)或 DStream:park Streaming 对内部持续的实时数据流的抽象描述,即处理的一个实时数据流,在 Spark Streaming 中对应于一个 DStream 实例。
- 时间片或批处理时间间隔(BatchInterval):拆分流数据的时间单元,一般为 500 毫秒或 1 秒。
- 批数据(BatchData): 一个时间片内所包含的流数据,表示成一个 RDD。
- 窗口(Window): 一个时间段。系统支持对一个窗口内的数据进行计算
- 窗口长度(Window Length):一个窗口所覆盖的流数据的时间长度,必须是批处理时间间隔的倍数。
- 滑动步长(Sliding Interval): 前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。
2.3 离散流 (DStreams)
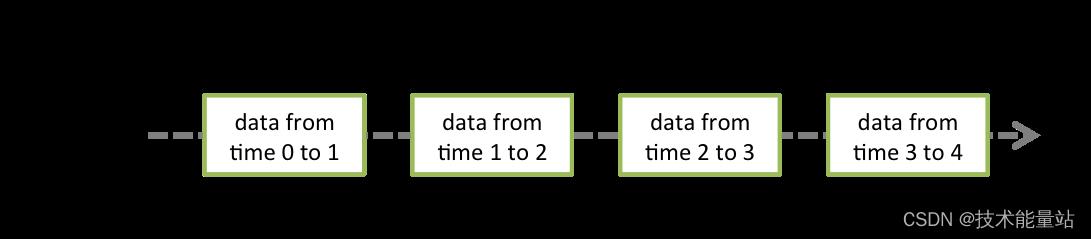
Discretized Stream或DStream是 Spark Streaming 提供的基本抽象。它表示一个连续的数据流,要么是从源接收到的输入数据流,要么是对输入流进行转换后生成的经过处理的数据流。在内部,DStream 由一系列连续的 RDD 表示,这是 Spark 对不可变的分布式数据集的抽象(有关详细信息,请参阅Spark 编程指南)。DStream中的每个RDD都包含一定间隔的数据,如下图所示
应用于 DStream 的任何操作都将转换为对底层 RDD 的操作。例如,在前面将行流转换为单词的示例中,该flatMap操作应用于 DStream 中的每个 RDD,lines以生成 DStream 的 wordsRDD。如下图所示。
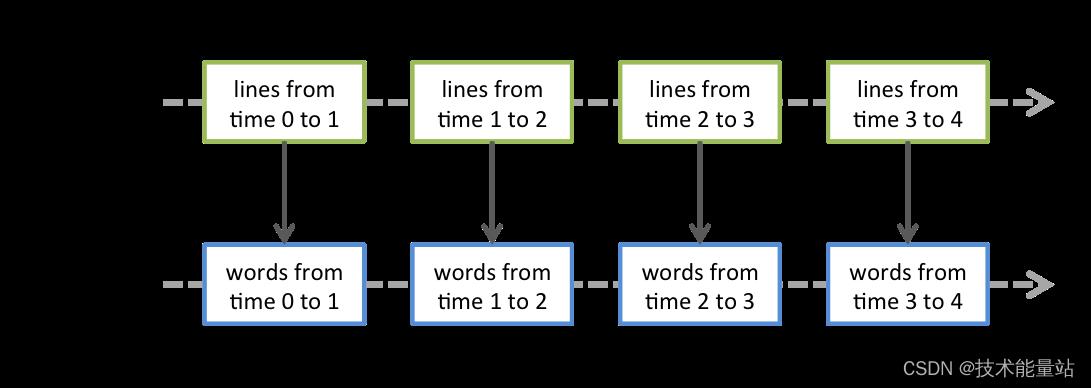
这些底层 RDD 转换由 Spark 引擎计算。DStream 操作隐藏了大部分这些细节,并为开发人员提供了更高级别的 API 以方便使用。
2.4 窗口操作(window)
Spark Streaming 还提供了窗口计算,它允许您在数据的滑动窗口上应用转换。下图说明了这个滑动窗口。
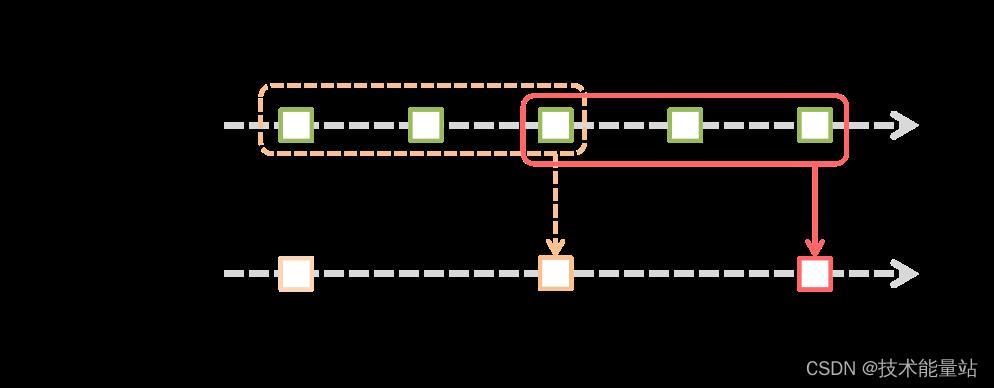
如图所示,每次窗口在源 DStream 上滑动时,落入窗口内的源 RDD 会被组合并操作,以产生窗口化 DStream 的 RDD。在这种特定情况下,该操作应用于数据的最后 3 个时间单位,并滑动 2 个时间单位。这说明任何窗口操作都需要指定两个参数。
- 窗口长度- 窗口的持续时间(图中的 3)。
- 滑动间隔- 执行窗口操作的间隔(图中的 2)。
这两个参数必须是源DStream的批处理间隔的倍数(图中1)。
3. 应用实战
下面以wordcount为例 实操DStream
3.1 场景需求
需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并
统计不同单词出现的次数
3.2 代码演练
(1) 添加依赖
<!--spark streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
(2) 编写代码
object Demo01_StreamWordCount
/**
* netcat 使用 来模拟实时数据流
* - win10: nc -l -p 9999
* - linux: nc -lk 9999
* @param args
*/
def main(args: Array[String]): Unit =
// 初始化spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Demo01_StreamWordCount")
// 初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
// 通过监控端口创建 DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("localhost", 9999)
// 将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
// 将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
// 将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动 SparkStreamingContext
ssc.start()
ssc.awaitTermination()
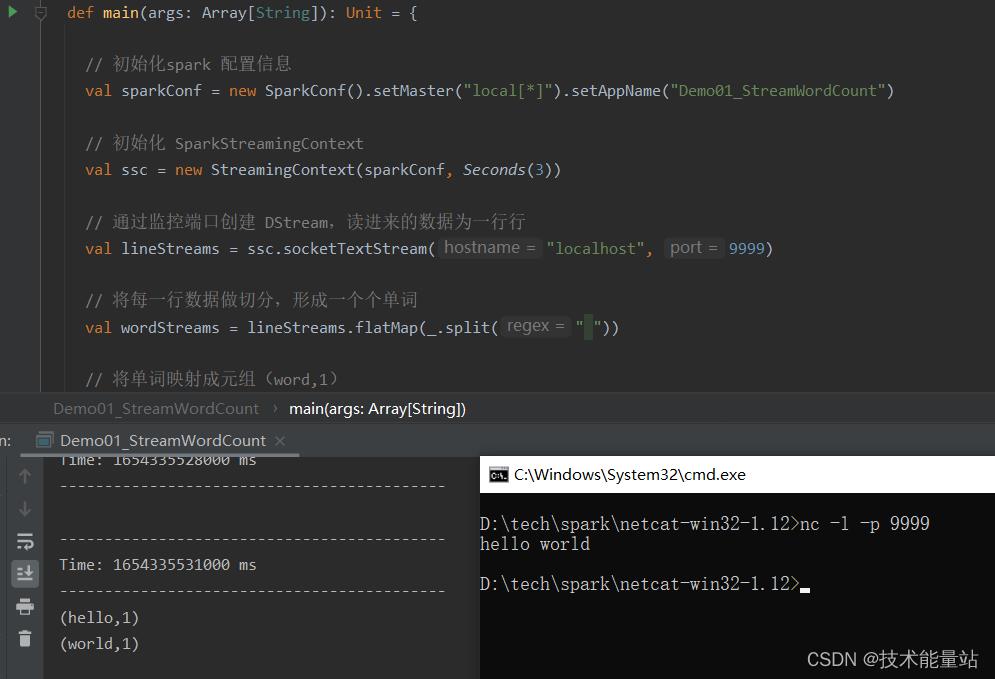
(3) 启动程序并通过 netcat 发送数据
nc -lk 9999
hello spark
(4)代码分析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据。
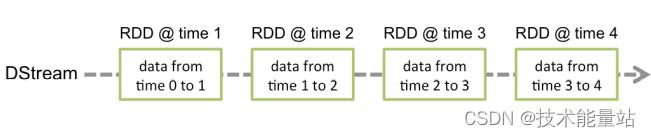
对数据的操作也是按照 RDD 为单位来进行的
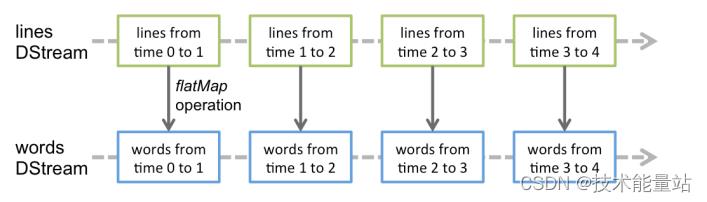
计算过程由 Spark Engine 来完成

(5) 运行结果
3.3 DStream 创建
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到
这个队列中的 RDD,都会作为一个 DStream 处理。
/**
* @contract: 公众号:技术能量站
* @desc:
* @link:
*/
object Demo02_DStream
def main(args: Array[String]): Unit =
//1.初始化 Spark 配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(4))
//3.创建 RDD 队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//4.创建 QueueInputDStream
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
//5.处理队列中的 RDD 数据
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//6.打印结果
reducedStream.print()
//7.启动任务
ssc.start()
//8.循环创建并向 RDD 队列中放入 RDD
for (i <- 1 to 5)
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
ssc.awaitTermination()
运行结果
-------------------------------------------
Time: 1539075280000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
-------------------------------------------
Time: 1539075284000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
参考文章
- https://spark.apache.org/docs/latest/streaming-programming-guide.html
- http://c.biancheng.net/view/3642.html
以上是关于Spark Streaming 流式处理(第三集)的主要内容,如果未能解决你的问题,请参考以下文章