Python字体反爬之乐居字体反爬,一文看懂,一文学会
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python字体反爬之乐居字体反爬,一文看懂,一文学会相关的知识,希望对你有一定的参考价值。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 672 篇原创博客
从订购之日起,案例 5 年内保证更新
文章目录
⛳️ 实战场景
本次字体反爬的目标场景是:乐居,地址如下所示:
https://house.leju.com/as/new/#wt_source=pc_csss_mf_zxlp
以上页面是随机打开的,你可以选择自己的城市进行测试。
使用开发者工具,先找到对应的数字,查看是否所见即所得。
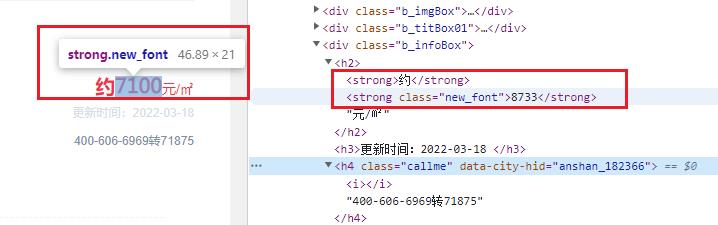
很明显的一个字体反爬,数字由 8733 转变为 7100 ,既然已经发现是数字产生了变化,那接下来的事情就非常容易了。
我们抓取一下字体文件,查看其内部具体包含哪些字体编码。
结果发现字体文件竟然是已字节流形式写到了前台,这样我们后续获取字体文件,就转变成了字节读取与解析。

通过工具查看字体文件之后,发现除字体外,还存在一些中文字符被替换的情况,我们在页面实测一下。
测试之后,中文字符在列表页未启用,估计在其它页面,这里不做过多探究。
查看字体文件是否一致
捕获多次刷新数据,得到下图内容。
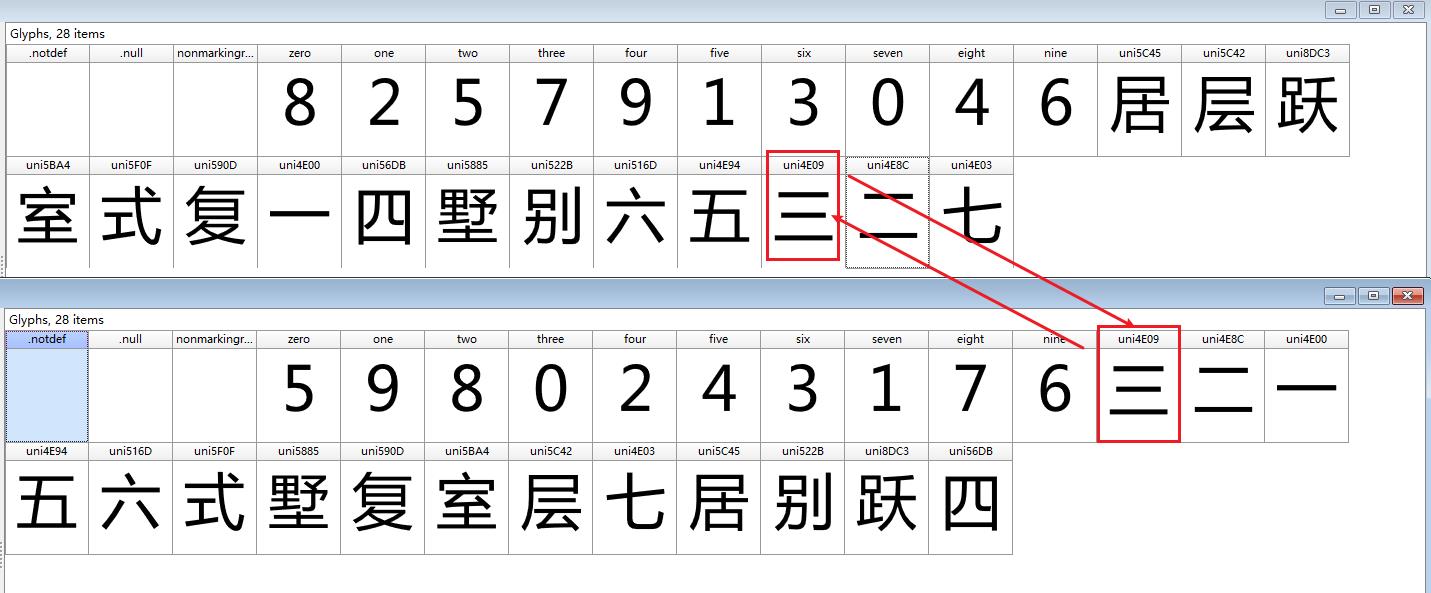
对比结果之后,可以了解到中文字符的编码无变化,仅数字产生变化,但是数字对应的英文又是确定的,这里其实已经解决了该案例。
⛳️ 乐居实战场景
字体文件的解析,参考我们 Python 爬虫 120 例子中的其它博客即可,本文仅对字体文件的爬取做解析。
import requests
import io
from lxml import etree
import base64
from fontTools.ttLib import TTFont
detail_url = 'https://house.leju.com/as/new/#wt_source=pc_csss_mf_zxlp'
res = requests.get(detail_url)
tree = etree.html(res.text)
style = tree.xpath("//style/text()")
font_face = style[0]
font_char = font_face.split("src: url(data:font/truetype;charset=utf-8;base64,")[1].split(") format('woff');")[0]
# print(font_char)
# 转换为字体文件
font_file_io = base64.b64decode(font_char)
print(type(font_file_io))
# 加载字体二进制流
font = TTFont(io.BytesIO(font_file_io))
print(font)
# 测试一下字体文件
font_map = font['cmap'].getBestCmap()
print(font_map)
运行代码的输出如下所示。

此时问题已经成功解决。
📣📣📣📣📣📣
右下角有个大拇指,点赞的漂亮加倍
欢迎大家订阅专栏:
以上是关于Python字体反爬之乐居字体反爬,一文看懂,一文学会的主要内容,如果未能解决你的问题,请参考以下文章