SQL调优指南笔记8:Optimizer Access Paths
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL调优指南笔记8:Optimizer Access Paths相关的知识,希望对你有一定的参考价值。
本文为SQL Tuning Guide第8章“优化访问路径”的笔记。
重要基本概念
-
access path
The means by which the database retrieves data from a database. For example, a query using an index and a query using a full table scan use different access paths.
数据库从数据库中检索数据的方法。 例如,使用索引的查询和使用全表扫描的查询使用不同的访问路径。
访问路径是查询用来从行源检索行的一种技术。 -
heap-organized table
A table in which the data rows are stored in no particular order on disk. By default, CREATE TABLE creates a heap-organized table.
一个表,其中数据行在磁盘上没有特定存储顺序。 默认情况下,CREATE TABLE 创建一个堆组织表。 -
index-organized table
A table whose storage organization is a variant of a primary B-tree index. Unlike a heap-organized table, data is stored in primary key order.
存储组织是主 B 树索引的变体的表。 与堆组织表不同,数据按主键顺序存储。 -
external table
A read-only table whose metadata is stored in the database but whose data in stored in files outside the database. The database uses the metadata describing external tables to expose their data as if they were relational tables.
一个只读表,其元数据存储在数据库中,但其数据存储在数据库外部的文件中。 数据库使用描述外部表的元数据来展现它们的数据,就好像它们是关系表一样。 -
unselective
A relatively large fraction of rows from a row set. A query becomes more unselective as the selectivity approaches 1. For example, a query that returns 999,999 rows from a table with one million rows is unselective. A query of the same table that returns one row is selective.
行集中返回相对较大的一部分行。 随着选择性的接近1,查询变得更加不具选择性。例如,从一百万行的表中返回999,999行的查询是不具选择性的。 返回一行的同一个表的查询是具选择性的。
8.1 Introduction to Access Paths
行源是执行计划中的步骤返回的一组行。 行源可以是表、视图或联结或分组操作的结果。
诸如访问路径之类的一元操作是查询从行源检索行的一种技术,它接受单个行源作为输入。 例如,全表扫描是检索单个行源的行。 相比之下,联结是二元操作,从两个行源接收输入。
数据库对不同的关系数据结构使用不同的访问路径。 下表总结了主要数据结构的常见访问路径。
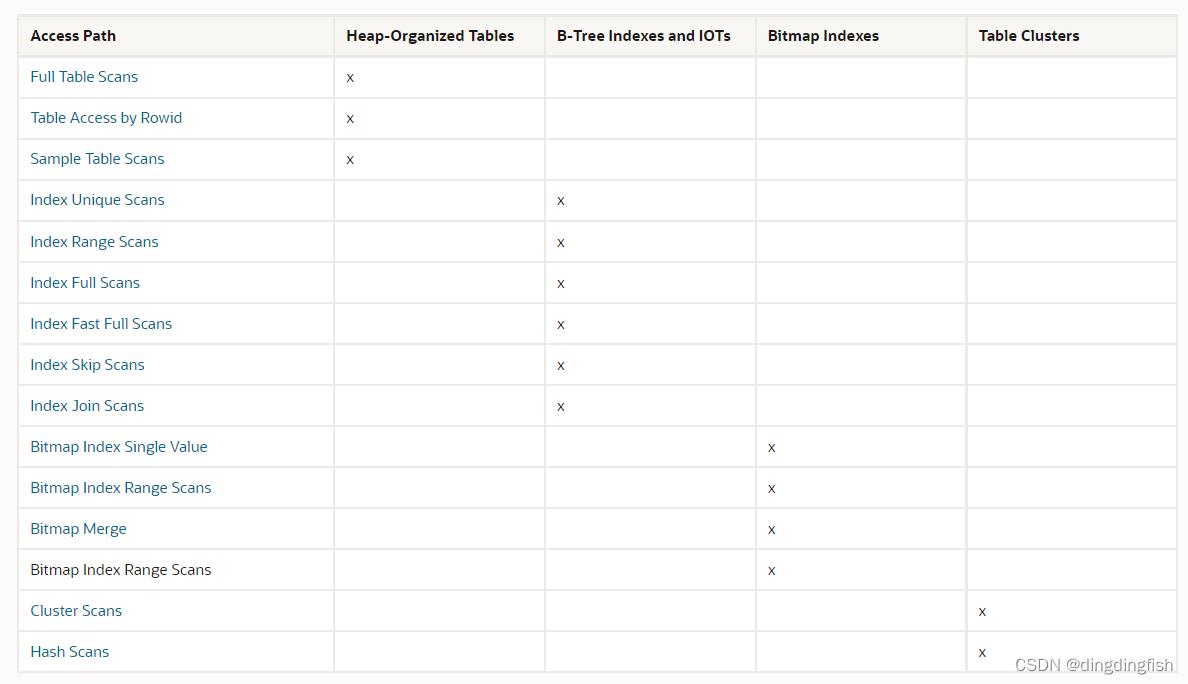
优化器考虑不同的可能执行计划,然后为每个计划分配一个成本。 优化器选择成本最低的计划。 一般来说,索引访问路径对于检索一小部分表行的语句更有效,而全表扫描在访问表的大部分数据时更有效。
8.2 Table Access Paths
表是 Oracle 数据库中数据组织的基本单位。
关系表是最常见的表类型。 关系表具有以下组织特征:
- 堆组织表不以任何特定顺序存储行。
- 索引组织表根据主键值对行进行排序。
- 外部表是只读表,其元数据存储在数据库中,但其数据存储在数据库之外。
8.2.1 About Heap-Organized Table Access
默认情况下,表按堆组织,这意味着数据库将行放置在最适合的位置,而不是按照用户指定的顺序。
当用户添加行时,数据库将这些行放在数据段中的第一个可用空间中。 不保证按插入的顺序检索行。
8.2.1.1 Row Storage in Data Blocks and Segments: A Primer
数据库将行存储在数据块中。在表中,数据库可以在块底部的任何位置写入一行。 Oracle 数据库使用包含行目录和表目录的块开销来管理块本身。
一个extent由逻辑上连续的数据块组成。这些块在磁盘上可能不是物理上连续的。segment是一组extent,其中包含表空间内逻辑存储结构的所有数据。例如,Oracle 数据库分配一个或多个extent来形成表的数据segment。数据库还分配一个或多个extent以形成表的索引段。
默认情况下,数据库对永久的本地管理表空间使用自动段空间管理 (ASSM)。当会话首次将数据插入表时,数据库会格式化位图块。位图跟踪段中的块。数据库使用位图查找空闲块,然后在写入之前格式化每个块。 ASSM 在块之间分散插入以避免并发问题。
高水位线 (HWM) 是数据块未格式化且从未使用过的段中的点。在 HWM 之下,一个块可的状态可以是已格式化和写入、格式化但为空,或者或未格式化。低高水位线 (low HWM) 标记了所有块都被格式化的点,因为它们的状态可能是包含数据或之前包含过数据。
在全表扫描期间,数据库读取所有已知已格式化的低 HWM 块,然后读取段位图以确定 HWM 和低 HWM 之间的哪些块已格式化并且可以安全读取。数据库不会去读取 HWM之外的块,因为这些块未格式化。
8.2.1.2 Importance of Rowids for Row Access
堆组织表中的每一行都有一个该表唯一的 rowid,它对应于行块的物理地址。 rowid 是一行的 10 字节物理地址。
rowid 指向特定的文件、块和行号。例如,在 rowid AAAPecAAFAAAABSAAA 中,最后的 AAA 表示行号。行号是行目录条目的索引。行目录条目包含指向块上行位置的指针。
数据库有时可以在块的底部移动一行。例如,如果启用了行移动,那么行可以因为分区键更新、闪回表操作、收缩表操作等而移动。如果数据库在块内移动一行,则数据库更新行目录条目以修改指针。 rowid 保持不变。
Oracle 数据库在内部使用 rowid 来构建索引。例如,B 树索引中的每个键都与指向关联行地址的 rowid 相关联。物理 rowid 提供对表行的最快访问,使数据库能够在一次 I/O 中检索一行。
8.2.1.3 Direct Path Reads
在直接路径(direct path)读取中,数据库将缓冲区从磁盘直接读取到 PGA 中,完全绕过 SGA。
下图显示了分散读取和顺序读取(将缓冲区存储在 SGA 中)与直接路径读取之间的区别。
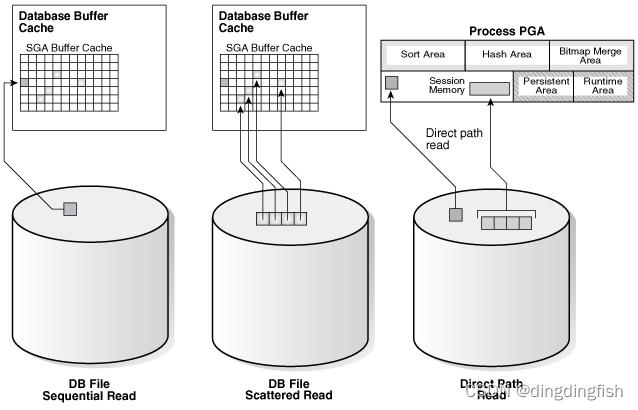
Oracle 数据库可能执行直接路径读取的情况包括:
- 执行 CREATE TABLE AS SELECT 语句
- 执行 ALTER REBUILD 或 ALTER MOVE 语句
- 从临时表空间读取
- 并行查询
- 从 LOB 段读取
8.2.2 Full Table Scans
全表扫描从表中读取所有行,然后过滤掉那些不符合选择条件的行。
8.2.2.1 When the Optimizer Considers a Full Table Scan
一般来说,优化器在没有其他的访问路径可选择,或者另一个可用的访问路径成本较高时,会选择全表扫描。
下表显示了选择全表扫描的典型原因。
- 无索引
如果索引不存在,则优化器使用全表扫描。 - 查询谓词将函数应用于索引列
除非索引是基于函数的索引,否则数据库会索引列的值,而不是列应用函数后的值。 一个典型的应用程序级错误是索引一个字符列,例如 char_col,然后使用 WHERE char_col=1 等语法查询该列。 数据库隐式地将 TO_NUMBER 函数应用于常数 1,从而阻止使用索引。 - 发出 SELECT COUNT(*) 查询,虽存在索引,但索引列包含空值
此时优化器不能使用索引来计算表行数,因为索引不能包含空条目。 - 查询谓词无法使用 B 树索引的前导部分
例如,员工(first_name,last_name)上可能存在索引。 如果用户使用谓词 WHERE last_name=‘KING’ 发出查询,则优化器可能不会选择索引,因为列 first_name 不在谓词中。 但是,在这种情况下,优化器可能会选择使用索引跳过扫描。 - 查询的选择性不强
如果优化器确定查询需要表中的大部分块,那么即使索引可用,它也会使用全表扫描。 全表扫描可以使用更大的 I/O 调用。 进行较少的大型 I/O 调用比进行许多较小的调用代价更低。 - 表统计信息已过时
例如,一张表很小,但现在已经变大了。 如果表统计信息过时并且不能反映表的当前大小,则优化器不知道索引现在比全表扫描最有效。 - 表很小
如果表在高水位线下包含少于 n 个块,其中 n 等于 DB_FILE_MULTIBLOCK_READ_COUNT 初始化参数的设置,则全表扫描可能比索引范围扫描便宜。 无论正在访问的表的比例或存在的索引如何,扫描的成本都可能较低。 - 该表具有高度的并行性
表的高度并行性使优化器倾向于全表扫描而不是范围扫描。 查询 ALL_TABLES.DEGREE 列中的值以确定并行度。 - 该查询使用全表扫描提示。
提示 FULL(表别名) 指示优化器使用全表扫描。
8.2.2.2 How a Full Table Scan Works
在全表扫描中,数据库顺序读取高水位线下的每个格式化块。 数据库只读取每个块一次。
下图描述了对表段的扫描,显示了扫描如何跳过高水位线以下的未格式化块。
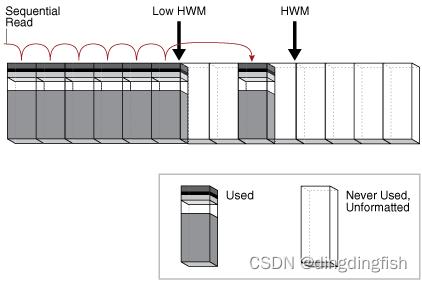
由于块是相邻的,数据库可以通过使 I/O 调用大于单个块(称为多块读取)来加快扫描速度。 读取调用的大小范围从一个块到 DB_FILE_MULTIBLOCK_READ_COUNT 初始化参数指定的块数。 例如,将此参数设置为 4 会指示数据库在一次调用中最多读取 4 个块。(跳过的那2个块,估计是通过位图知道它们是未格式化的)
在全表扫描期间缓存块的算法很复杂。 例如,数据库缓存块的方式取决于表的大小。
8.2.2.3 Full Table Scan: Example
以下语句使用全表扫描,是因为salary列上没有索引。
SELECT salary
FROM hr.employees
WHERE salary > 4000;
8.2.3 Table Access by Rowid
rowid 是数据存储位置的内部表示。
行的rowid 指定包含该行的数据文件和数据块以及该行在该块中的位置。 通过指定行 ID 来定位行是检索单行的最快方法,因为它指定了该行在数据库中的确切位置。
注意:Rowids 在不同版本可能会改变。 不建议根据位置访问数据,因为行可以移动。
8.2.3.1 When the Optimizer Chooses Table Access by Rowid
在大多数情况下,数据库在扫描一个或多个索引后通过 rowid 访问表。
但是,rowid 的表访问不一定发生在每次索引扫描之后。 如果索引包含所有需要的列,则可能不需要按 rowid 的访问。
8.2.3.2 How Table Access by Rowid Works
要通过 rowid 访问表,数据库执行多个步骤。
数据库执行以下操作:
- 从语句 WHERE 子句或通过一个或多个索引的索引扫描获取选定行的 rowid
语句中的列若在索引中不存在,则可能需要表访问。 - 根据其 rowid 定位表中的每个选定行
8.2.3.3 Table Access by Rowid: Example
以下语句的执行计划中,数据库通过索引中的rowid来返回行中的数据(因为是SELECT *)。
步骤 1 中所示的 BATCHED 访问是指数据库从索引中检索多个 rowid,然后尝试按块顺序访问行,以提高聚类并减少数据库必须访问块的次数。
SELECT *
FROM employees
WHERE employee_id > 190;
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16 | 1104 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEES | 16 | 1104 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_EMP_ID_PK | 16 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
8.2.4 Sample Table Scans
样本表扫描从简单表或复杂 SELECT 语句(例如涉及连接和视图的语句)中检索数据的随机样本。
8.2.4.1 When the Optimizer Chooses a Sample Table Scan
当语句 FROM 子句包含 SAMPLE 关键字时,数据库使用样本表扫描。
SAMPLE 子句具有以下形式:
- SAMPLE (sample_percent)
数据库读取表中指定百分比的行以执行样本表扫描。 - SAMPLE BLOCK (sample_percent)
数据库读取指定百分比的表块以执行样本表扫描。
sample_percent 指定要包含在样本中的总行数或块数的百分比。 该值必须在 0.000001 到(但不包括)100 的范围内。此百分比表示为样本选择块抽样中的每一行或每一行集群的概率。 这并不意味着数据库准确地检索 sample_percent 行。
注意:只有在全表扫描或索引快速全扫描期间才可以进行块采样。 如果存在更有效的执行路径,则数据库不会对块进行采样。 要保证对特定表或索引进行块采样,请使用 FULL 或 INDEX_FFS 提示。
8.2.4.2 Sample Table Scans: Example
此示例使用示例表扫描访问员工表 1% 的数据,按块而不是行进行采样。此表共107行。
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
| 1 | TABLE ACCESS SAMPLE| EMPLOYEES | 1 | 69 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------
8.2.5 In-Memory Table Scans
In-Memory 扫描从 In-Memory Column Store(IM 列存储)中检索行。
IM 列存储是一个可选的 SGA 区域,它以针对快速扫描优化的特殊列格式存储表和分区的副本。
8.2.5.1 When the Optimizer Chooses an In-Memory Table Scan
优化器成本模型知道 IM 列存储的内容。
当用户执行引用 IM 列存储中的表的查询时,优化器会计算所有可能的访问方法(包括内存中表扫描)的成本,并选择成本最低的访问方法。
8.2.5.2 In-Memory Query Controls
您可以使用初始化参数控制 In-Memory 查询。
以下数据库初始化参数会影响 In-Memory 功能:
-
INMEMORY_QUERY
此参数在会话或系统级别启用或禁用数据库的内存中查询。 当您想要测试启用和禁用 IM 列存储的工作负载时,此参数很有帮助。 -
OPTIMIZER_INMEMORY_AWARE
此参数启用 (TRUE) 或禁用 (FALSE) 对优化器成本模型、表扩展、布隆过滤器等所做的所有内存增强。 将该参数设置为 FALSE 会导致优化器在 SQL 语句优化期间忽略表的 In-Memory 属性。 -
OPTIMIZER_FEATURES_ENABLE
当设置为低于 12.1.0.2 的值时,此参数与将 OPTIMIZER_INMEMORY_AWARE 设置为 FALSE 的效果相同。
要启用或禁用 In-Memory 查询,您可以指定 INMEMORY 或 NO_INMEMORY 提示,它们是 INMEMORY_QUERY 初始化参数的按查询设置的等效项。 如果 SQL 语句使用 INMEMORY 提示,但它引用的对象尚未加载到 IM 列存储中,则数据库在执行语句之前不会等待对象填充到 IM 列存储中。 但是,对象的初始访问会触发 IM 列存储中的对象填充。
8.2.5.3 In-Memory Table Scans: Example
此略。执行计划的Operation中会出现TABLE ACCESS INMEMORY FULL关键字。
8.3 B-Tree Index Access Paths
索引是一种可选结构,与表或表簇相关联,有时可以加快数据访问速度。
通过在表的一个或多个列上创建索引,您可以在某些情况下从表中检索一小组随机分布的行。 索引是减少磁盘 I/O 的众多方法之一。
8.3.1 About B-Tree Index Access
B树是平衡树的缩写,是最常见的数据库索引类型。
B-tree 索引是一个有序的值列表,分为多个范围。 通过将键与行或行范围相关联,B 树为广泛的查询提供了出色的检索性能,包括精确匹配和范围搜索。
8.3.1.1 B-Tree Index Structure
B-tree 索引有两种类型的块:用于搜索的分支块和存储值的叶块。
下图说明了 B 树索引的逻辑结构。 分支块存储在两个键之间做出分支决策所需的最小键前缀。 叶块包含每个索引数据值和用于定位实际行的相应 rowid。 每个索引条目都按 (key, rowid) 排序。 叶块是双向链接的。
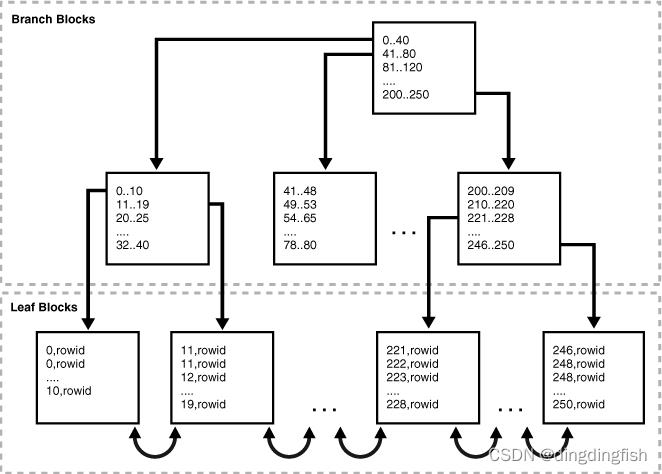
8.3.1.2 How Index Storage Affects Index Scans
位图索引块可以出现在索引段的任何位置。
上图显示了叶块彼此相邻。 例如,1-10 块在 11-19 块的旁边和之前。 此排序说明了连接索引条目的链表。 但是,索引块不需要按顺序存储在索引段内。 例如,246-250 块可以出现在段中的任何位置,包括直接在 1-10 块之前。 因此,有序索引扫描必须执行单块 I/O。 数据库必须读取一个索引块以确定它接下来必须读取哪个索引块。
索引块体将索引条目存储在堆中,就像表行一样。 例如,如果首先将值 10 插入到表中,那么键为 10 的索引条目可能会插入到索引块的底部。 如果接下来将 0 插入表中,则键 0 的索引条目可能会插入到 10 的条目之上。因此,块主体中的索引条目不是按键顺序存储的。 但是,在索引块中,行头按键顺序存储记录。 例如,头中的第一条记录指向键为 0 的索引条目,依此类推,直到指向键为 10 的索引条目的记录。因此,索引扫描可以读取行头以确定从哪里开始和结束范围扫描,避免读取块中的每个条目。
8.3.1.3 Unique and Nonunique Indexes
在非唯一索引中,数据库通过将 rowid 作为额外列附加到键来存储它。 该条目添加一个长度字节以使索引键唯一。
例如,上图所示的非唯一索引中的第一个索引键是 0,rowid 而不是简单的 0。数据库按索引键值对数据进行排序,然后按 rowid 升序排列。 例如,条目排序如下:
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
8.3.1.4 B-Tree Indexes and Nulls
B-tree 索引从不存储所有键为空的条目,这对于优化器如何选择访问路径很重要。 此规则的结果是单列 B 树索引从不存储空值。
一个例子有助于说明。 hr.employees 表在employee_id 上有一个主键索引,在department_id 上有一个唯一索引。 department_id 列可以包含空值,使其成为可为空的列,但employee_id 列不能。
SQL> SELECT COUNT(*) FROM employees WHERE department_id IS NULL;
COUNT(*)
----------
1
SQL> SELECT COUNT(*) FROM employees WHERE employee_id IS NULL;
COUNT(*)
----------
0
所以其执行计划是不同的:
-- 全表扫描
EXPLAIN PLAN FOR SELECT department_id FROM employees;
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
-- 索引范围扫描
EXPLAIN PLAN FOR SELECT department_id FROM employees WHERE department_id=10;
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
-- 排除掉NULL后,仍可以使用索引扫描:INDEX FULL SCAN
EXPLAIN PLAN FOR SELECT department_id FROM employees
WHERE department_id IS NOT NULL;
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
8.3.2 Index Unique Scans
索引唯一扫描最多返回 1 个 rowid。
8.3.2.1 When the Optimizer Considers Index Unique Scans
索引唯一扫描需要相等谓词。
具体来说,仅当查询谓词使用相等运算符(例如 WHERE prod_id=10)引用唯一索引键中的所有列时,数据库才会执行唯一扫描。
唯一或主键约束本身不足以产生索引唯一扫描,因为列上的非唯一索引可能已经存在。 考虑以下示例,该示例创建 t_table 表,然后在 numcol 上创建非唯一索引:
DROP TABLE t_table;
CREATE TABLE t_table(numcol INT);
CREATE INDEX t_table_idx ON t_table(numcol);
SELECT UNIQUENESS FROM USER_INDEXES WHERE INDEX_NAME = 'T_TABLE_IDX';
UNIQUENES
---------
NONUNIQUE
以下代码在具有非唯一索引的列上创建主键约束,从而导致索引范围扫描而不是索引唯一扫描:
ALTER TABLE t_table ADD CONSTRAINT t_table_pk PRIMARY KEY(numcol);
SET AUTOTRACE TRACEONLY EXPLAIN
SELECT * FROM t_table WHERE numcol = 1;
--------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.01 |
|* 1 | INDEX RANGE SCAN| T_TABLE_IDX | 1 | 1 | 0 |00:00:00.01 |
--------------------------------------------------------------------------------
您可以使用 INDEX(alias index_name) 提示指定要使用的索引,但不能指定特定类型的索引访问路径。
这个例子太奇怪了,按说定义了主键后应该删除非唯一索引。
8.3.2.2 How Index Unique Scans Work
扫描按顺序搜索索引以查找指定的键。 索引唯一扫描在找到第一条记录后立即停止处理,因为不可能有第二条记录。 数据库从索引条目中获取rowid,然后检索rowid指定的行。
下图说明了索引唯一扫描。 该语句请求 prod_id 列中产品 ID 19 的记录,该列具有主键索引。
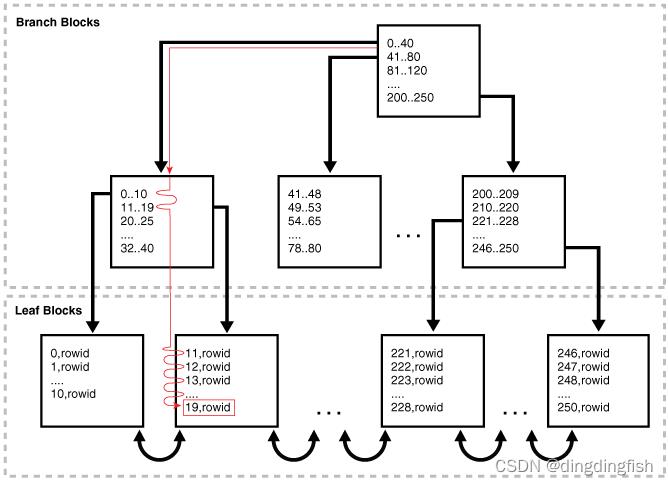
8.3.2.3 Index Unique Scans: Example
此示例使用唯一扫描从 products 表中检索一行。
SELECT *
FROM sh.products
WHERE prod_id = 19;
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 173 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | 173 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PRODUCTS_PK | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
8.3.3 Index Range Scans
索引范围扫描是值的有序扫描。
扫描的范围可以在两侧有界(例如>=和<=),也可以在一侧或两侧无界(例如>和<)。 优化器通常为具有高选择性的查询选择范围扫描。
默认情况下,数据库以升序存储索引,并以相同的顺序扫描它们。 例如,谓词 department_id >= 20 的查询使用范围扫描返回按索引键 20、30、40 等排序的行。 如果多个索引条目具有相同的键,则数据库按 rowid 升序返回它们,因此 0,AAAPvCAAFAAAAFaAAAa 后面是 0,AAAPvCAAFAAAAFaAAg,依此类推。
降序索引范围扫描与索引范围扫描相同,只是数据库按降序返回行。 通常,当以降序对数据进行排序或查找小于指定值的值时,数据库会使用降序扫描。
8.3.3.1 When the Optimizer Considers Index Range Scans
对于索引范围扫描,索引键必须可以有多个值。
具体来说,优化器会在以下情况下考虑索引范围扫描:
- 在条件中指定索引的一个或多个前导列。
条件指定一个或多个表达式和逻辑(布尔)运算符的组合,并返回 TRUE、FALSE 或 UNKNOWN 值。 - 索引键可以有 0个、1个 或更多值。
提示:如果您需要排序数据,请使用 ORDER BY 子句,不要依赖索引。 如果索引可以满足 ORDER BY 子句,则优化器使用此选项,从而避免排序。
当索引可以满足 ORDER BY DESCENDING 子句时,优化器会考虑降序索引范围扫描。
如果优化器选择全表扫描或其他索引,则可能需要提示来强制执行此访问路径。 INDEX(tbl_alias ix_name) 和 INDEX_DESC(tbl_alias ix_name) 提示指示优化器使用特定索引。
8.3.3.2 How Index Range Scans Work
在索引范围扫描期间,Oracle 数据库从根到分支行进。
一般来说,扫描算法如下:
- 读取根块。
- 读取分支块。
- 交替执行以下步骤,直到检索到所有数据:
a. 读取叶子块以获取 rowid。
b. 读取表块以检索行。
注意:在某些情况下,索引扫描会读取一组索引块,对 rowid 进行排序,然后再读取一组表块。
因此,为了扫描索引,数据库通过叶子块向后或向前移动。 例如,对 20 到 40 之间的 ID 的扫描会定位第一个具有最小键值为 20 或更大的叶块。 扫描在叶节点链表中水平进行,直到找到大于 40 的值,然后停止。
下图说明了使用升序的索引范围扫描。 一条语句请求department_id 列中值为20 的员工记录,该列具有非唯一索引。 在此示例中,部门 20 存在 2 个索引条目。
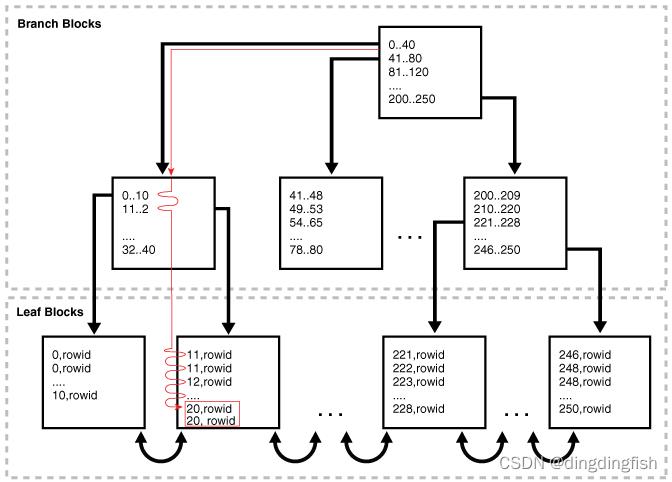
8.3.3.3 Index Range Scan: Example
此示例使用索引范围扫描从员工表中检索一组值。
SELECT *
FROM employees
WHERE department_id = 20
AND salary > 1000;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEES | 2 | 138 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 2 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
8.3.3.4 Index Range Scan Descending: Example
此示例使用索引按排序顺序从 employees 表中检索行。
SELECT *
FROM employees
WHERE department_id < 20
ORDER BY department_id DESC;
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 2 | 138 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| EMP_DEPARTMENT_IX | 2 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
数据库定位第一个索引叶子块,该块包含 20 或更少的最高键值。 然后扫描通过叶节点的链表水平向左进行。 数据库从每个索引条目中获取rowid,然后检索rowid指定的行。
8.3.4 Index Full Scans
索引全扫描按顺序读取整个索引。 索引全扫描可以消除单独的排序操作,因为索引中的数据是按索引键排序的。
8.3.4.1 When the Optimizer Considers Index Full Scans
优化器会在多种情况下考虑索引全扫描。
这些情况包括:
- 谓词引用索引中的列。 此列不必是前导列。
- 未指定谓词,但满足以下所有条件:
- 表和查询中的所有列都在索引中。(似乎和后面的例子不符)
- 至少一个索引列不为空。
- 查询在索引的不可为空的列上包含 ORDER BY。
8.3.4.2 How Index Full Scans Work
数据库读取根块,然后下行到索引的左侧(如果进行降序全扫描,则为右侧)直到到达叶块。
然后数据库到达一个叶子块,扫描在索引的底部进行,一次一个块,按排序顺序。 数据库使用单块 I/O 而不是多块 I/O。
下图说明了索引全扫描。 一条语句请求按 department_id 排序的部门记录。
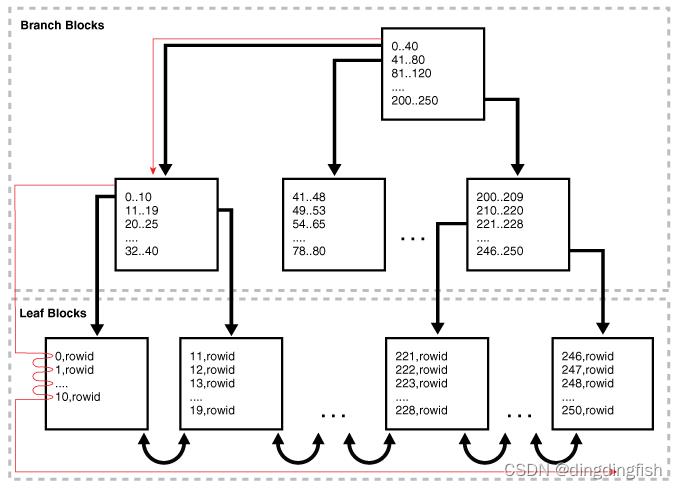
8.3.4.3 Index Full Scans: Example
此示例使用索引全扫描来满足带有 ORDER BY 子句的查询。
SELECT department_id, department_name
FROM departments
ORDER BY department_id;
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 27 | 432 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
| 2 | INDEX FULL SCAN | DEPT_ID_PK | 27 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
由于department_name不在索引中,所以还需通过rowid去查询表,不过仍避免了排序。
8.3.5 Index Fast Full Scans
索引快速全扫描以未排序的顺序读取索引块,因为它们存在于磁盘上。 这种扫描不使用索引来探查表,而是读取索引而不是表,本质上是使用索引本身作为表。
8.3.5.1 When the Optimizer Considers Index Fast Full Scans
当查询仅访问索引中的属性时,优化器会考虑此扫描。
注意:与全扫描不同,快速全扫描不能消除排序操作,因为它不会按顺序读取索引。
INDEX_FFS(table_name index_name) 提示强制进行快速全索引扫描。
8.3.5.2 How Index Fast Full Scans Work
数据库使用多块 I/O 来读取根块以及所有叶和分支块。 数据库忽略分支和根块并读取叶块上的索引条目。
8.3.5.3 Index Fast Full Scans: Example
此示例使用快速全索引扫描作为优化器提示的结果。
EXPLAIN PLAN FOR
SELECT /*+ INDEX_FFS(departments dept_id_pk) */ COUNT(*)
FROM departments;
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| DEPT_ID_PK | 27 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------
-- 若不指定hint,则为INDEX FULL SCAN
-----------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FULL SCAN| DEPT_ID_PK | 以上是关于SQL调优指南笔记8:Optimizer Access Paths的主要内容,如果未能解决你的问题,请参考以下文章