On the Efficacy of Knowledge Distillation
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了On the Efficacy of Knowledge Distillation相关的知识,希望对你有一定的参考价值。
Motivation
- 实验观察到:并不是性能越好的teacher就能蒸馏(教)出更好的student,因此本文想梳理出影响蒸馏性能的因素
- 推测是容量不匹配的原因,导致student模型不能够mimic teacher,反而带偏了主要的loss
- 之前解决该问题的做法是逐步的进行蒸馏,但是效果也不好。
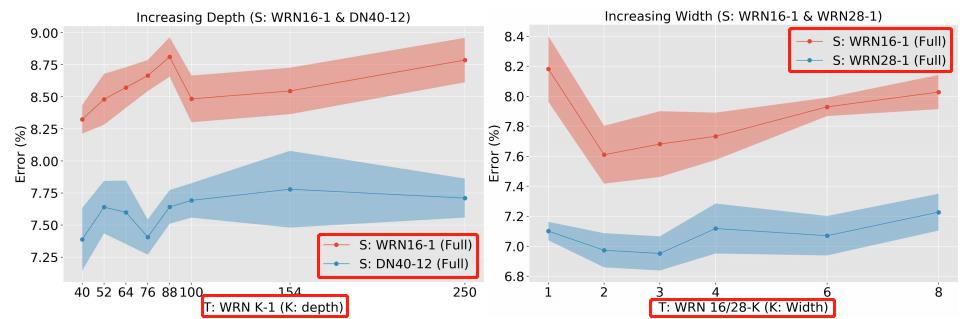
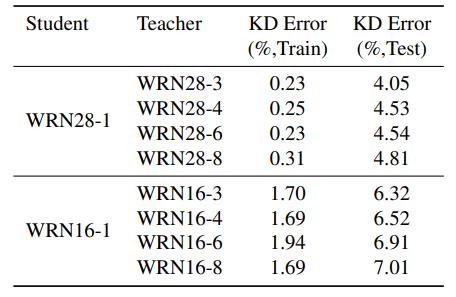
- 左边Teacher为WRN k-1,k是深度,Student是WRN16-1和DN40-12(Densenet 40-12),两个student并没有随着teacher深度的增加而效果变好
- 右边Teacher为WRN 16/28-k, Student是WRN16-1和WRN28-1,两个student并没有随着teacher宽度的增加而效果变好
表明单单提高teacher的性能好坏并不一定能提高蒸馏效果
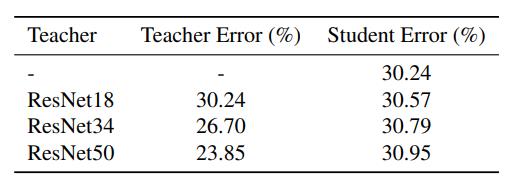
Method
因为本文提出一种early-stop teacher方法可以有效地避免该问题即:
- 使用early-stop teacher进行蒸馏
- 接近收敛时要提前停止知识蒸馏(这个论文中后续没有细说了)
Experiments
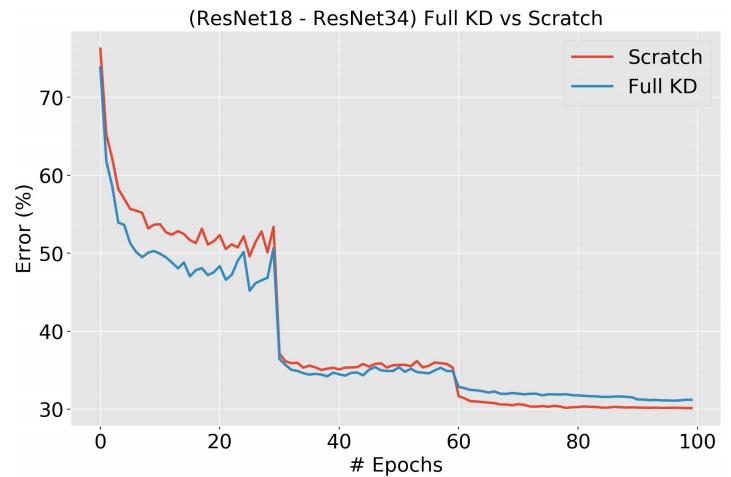
有趣的发现:
- 红色是training from scratch,蓝色是full KD,我们可以看到网络训练前期,KD大大帮助了训练,但是后面会开始影响精度
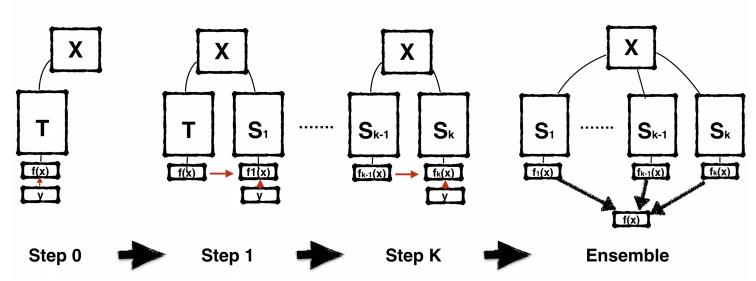
- 逐步的进行蒸馏可能依赖于网络结构,如在本文实验的Res18不work,和之前的论文又悖
训练过程:开始训练一个teacher,然后KD得到s1,然后s1KD得到s2,以此循环最后得到sk,最最后可以把他们ensemble起来得到一个最终模型
但是本文发现在Res18不work,逐步KD得到的还不如train from scratch,在WRN16-2上是work的。但是最终ensemble的模型还不如ensemble一些train from scratch的模型,因为KD得到的模型太“像”了
- teacher太强,student的容量和teacher差距太远,导致根本都无法mimic到那个空间去,KD loss随着teacher变强升高,反而容易干扰正常的学习。
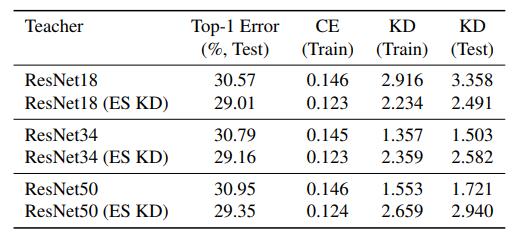
引入Early Stop的策略后情况有所改善了
以上是关于On the Efficacy of Knowledge Distillation的主要内容,如果未能解决你的问题,请参考以下文章