大数据:Spark mlib Naive bayes朴素贝叶斯分类之多元朴素贝叶斯源码分析
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据:Spark mlib Naive bayes朴素贝叶斯分类之多元朴素贝叶斯源码分析相关的知识,希望对你有一定的参考价值。
1. 什么是朴素贝叶斯
朴素贝叶斯是一种构建分类器,该分类器基于一个理论:所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关
2. 朴素贝叶斯概率模型
概率模型分类器是一个条件概率模型:(独立的类别特征C有若干类别,条件依赖于若干特征变量F1,F2,...,Fn)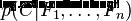 贝叶斯定理:
贝叶斯定理:
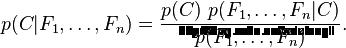 我们可以看到分母并不依赖于C,而且特征Fn的概率是给定的,分母可以认为是一个常数。
这样分子就等价于联合分布模型, 使用链式法则,可将该式写成条件概率的形式,如下所示
我们可以看到分母并不依赖于C,而且特征Fn的概率是给定的,分母可以认为是一个常数。
这样分子就等价于联合分布模型, 使用链式法则,可将该式写成条件概率的形式,如下所示
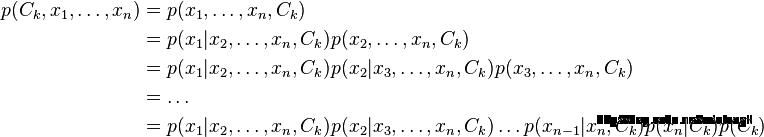
假设每个特征Fi对于其他特征Fj是条件独立的。
这就意味着
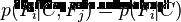
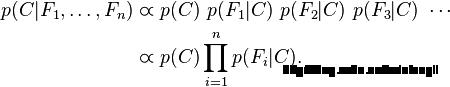
3. 多元朴素贝叶斯
p(X|Ck)表示事件i发生的概率,特征向量X=(x1,x2,...,xn),其中xi表示事件i在特定的对象中被观察到的次数。 X的似然函数如下所示:
多元朴素贝叶斯分类器:使用对数转化成线性分类器。
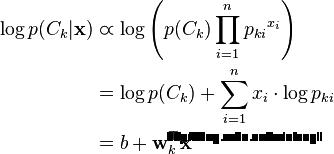
如果一个事件在特征向量i中没有出现过,那么i的特征值概率将为0,而0的对数是无效的,需要对每个小类样本概率进行修正,以保证不会出现有为0的概率出现,需要加上平滑系数,常用到的平滑就是加1平滑(也称拉普拉斯平滑)。
多元朴素贝叶斯常用于文档的归类分析
4. Spark实现多元朴素贝叶斯
4.1 计算事件i的特征向量的次数
要实现多元朴素贝叶斯模型,首先要归并同一事件i的特征向量的次数,那么我们很容易想到函数AggregateByKey,事件i作为key进行归并 val aggregated = dataset.select(col($(labelCol)), w, col($(featuresCol))).rdd
.map row => (row.getDouble(0), (row.getDouble(1), row.getAs[Vector](2)))
.aggregateByKey[(Double, DenseVector)]((0.0, Vectors.zeros(numFeatures).toDense))(
seqOp =
case ((weightSum: Double, featureSum: DenseVector), (weight, features)) =>
requireValues(features)
BLAS.axpy(weight, features, featureSum)
(weightSum + weight, featureSum)
,
combOp =
case ((weightSum1, featureSum1), (weightSum2, featureSum2)) =>
BLAS.axpy(1.0, featureSum2, featureSum1)
(weightSum1 + weightSum2, featureSum1)
).collect().sortBy(_._1)- DataSet的支持:在Spark 2.1后部分mlib库对dataset进行支持,在这种情况下需要把原来的LabeledPoint进行转化成DataSet
- Weight 权重支持:你可以定义每一个特征纬度的权重,特征纬度的权重最后会影响log(P(Ck))的值,默认的权重设置为1
- seqOp:在同一个Partation中的合并操作 combOp: 不同的Partition 的最后合并操作
4.2 计算事件i的概率
val piLogDenom = math.log(numDocuments + numLabels * lambda)
var i = 0
aggregated.foreach case (label, (n, sumTermFreqs)) =>
labelArray(i) = label
piArray(i) = math.log(n + lambda) - piLogDenom
......
计算事件I的概率对数: log(P|Ck) = math.log((n+lambda)/(numDocuments+numLabels*lamdba)) 假如:有两个事件A,B,特征向量是x1,x2,x3 数据集合如下: A 1 2 3 A 3 4 1 B 3 2 4 B 5 7 1 计算log(P|A) n: 就是事件A的数量 2(权重是1的情况下) numDocuments: 就是总数据集合的数量 4 numLabels: 就是合并后剩下的数据集合的数量 2,也就是事件的数量(A,B) lambda:就是为了防止为0的平滑系数
4.3 计算事件i的每个特征的概率
val thetaLogDenom = $(modelType) match
case Multinomial => math.log(sumTermFreqs.values.sum + numFeatures * lambda)
case _ =>
// This should never happen.
throw new UnknownError(s"Invalid modelType: $$(modelType).")
var j = 0
while (j < numFeatures)
thetaArray(i * numFeatures + j) = math.log(sumTermFreqs(j) + lambda) - thetaLogDenom
j += 1
sumtermfreqs.values.sum 就是所有特征值x1...xn在事件A下的数量和
numfeatures: 就是总的特征向量的数量n
4.4 构建矩阵和向量生成模型
向量:事件A,B的概率向量 举证:事件A,B的每一个特征的概率,构成一个以特征数量为行,以事件为列的密度矩阵,保存到朴素贝叶斯模型中去 val pi = Vectors.dense(piArray)
val theta = new DenseMatrix(numLabels, numFeatures, thetaArray, true)
new NaiveBayesModel(uid, pi, theta).setOldLabels(labelArray)4.5 如何进行分类
按照多元朴素贝叶斯计算模型
计算log(P(Ck))+sum(xi*log(Pki))为归为某个事件的概率
log(p(Ck))和log(Pki)都已经在前面计算好了,唯一要做的是将要用于分类的数据*log(Pki)并且求和,加上log(Pck)就可以了,会不会很奇怪为什么是求和而不是求乘法,通常贝叶斯公式都是乘法,因为这里是求了对数,所以乘法变成了加法 如何分类? MAP决策准则:选出算出最大的概率所属的分类
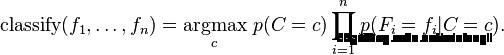
4.6 如何判定模型有效
使用常用的交叉验证方式,将已经分类好的数据集合随机分成测试数据和训练数据,使用训练数据进行训练计算概率矩阵,使用测试数据进行预测分类,计算预测的准确率,设定自己定义的准确率,如果达到就判定训练的模型有效。 val Array(training, test) = data.randomSplit(Array(0.6, 0.4))
val model = NaiveBayes.train(training, lambda = 1.0, modelType = "multinomial")
val predictionAndLabel = test.map(p => (model.predict(p.features), p.label))
val accuracy = 1.0 * predictionAndLabel.filter(x => x._1 == x._2).count() / test.count()以上是关于大数据:Spark mlib Naive bayes朴素贝叶斯分类之多元朴素贝叶斯源码分析的主要内容,如果未能解决你的问题,请参考以下文章