flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题
Posted ESOO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题相关的知识,希望对你有一定的参考价值。
日志平台运行一段时间,发现日志有部分丢失,通过检查日志,发现有两个问题导致数据丢失,一个是遇到空行后,日志停止收集,还有就是kafka监控offsets时变小,通过分析代码,找到如下方法:
空行问题:
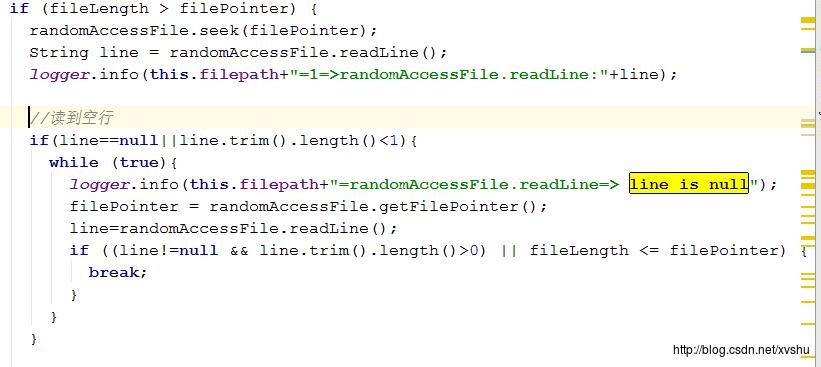
在系统稳定运行一段时间之后,发现了一个致命性的bug就是在遇到空行时,无法自动跳过,导致识别为文件结束,再次读取还是空行,跳入了死循环
解决办法:
解决的办法也非常简单,就是增加对文件大小与当前行数的比较,两者相等则是到达文件末尾,否则继续读取下一行,直到文件末尾
源码:
offsets变小问题:
我们发现,在大数据量的并发前提下,通过监控kafka,发现数据有重复收入的现象,而且非常严重
解决办法:
观察一段时间,发现可能是flume-kafka-channel管理offsets的问题,果断进行源码分析,加入相关配置后,情况有所改善, 但是由于offsets是由flume管理,彻底解决这个问题,需要进一步修正代码。
配置:
agent1.channels.c2.migrateZookeeperOffsets=true
agent1.channels.c2.kafka.consumer.session.timeout.ms=100000
agent1.channels.c2.kafka.consumer.request.timeout.ms=110000
agent1.channels.c2.kafka.consumer.fetch.max.wait.ms=1000
agent1.channels.c2.zookeeperConnect=10.1.115.181:2181,10.1.114.221:2181,10.1.114.231:2181/kafka总结:
flume在业界,是一款不错的管道工具,高并发下问题解决也比较迅速,源码结构简单,逻辑清晰,扩展和维护方便推荐各大公司使用。
以上是关于flume高并发优化——(14)解决空行停止收集数据问题,及offsets变小问题的主要内容,如果未能解决你的问题,请参考以下文章