敢看系列?Python字体反爬实战案例之实习那僧,继续挖坑
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了敢看系列?Python字体反爬实战案例之实习那僧,继续挖坑相关的知识,希望对你有一定的参考价值。
文章目录
⛳️ 实习 实战场景 僧
本篇博客继续学习字体反爬,涉及的站点是实习 x,目标站点地址直接百度搜索即可。

可以看到右侧源码中出现了很多“乱码”,这其中就包含了关键信息。
接下来按照常规的套路,在开发者工具中检索字体相关信息,但是筛选之后,并没有得到反爬的字体,只有一个 file? 有些许的可能性。

这里就是一种新鲜的场景了,如果判断不准,那只能用字体样式和字体标签名进行判断了。
在网页源码中检索 @font-face 和 myFont,得到下图内容,这里发现 file 字体又出现了,看来解决问题的关键已经出现了。

下载文件名之后发现无后缀名,我们可以补上一个 .ttf 的后缀,接下来拖拽到 FontCreator 中,然后进行查阅。

二次刷新页面之后,再次获取一个 file 文件,查看二者是否有编码变化问题。
结论:每次请求字体文件,得到的响应无变化。
既然没有变化,后续的字体反爬实战编码就变的简单了。
⛳️ 实习 实战编码 僧
解析字体文件,获取编码与字符。
from fontTools.ttLib import TTFont
font1 = TTFont('./fonts/file.ttf')
keys,values = [],[]
for k, v in font1.getBestCmap().items():
print(k,v)
得到的结果如下所示。
2 extra bytes in post.stringData array
120 x
57345 uni4E00
57360 uni77
57403 uni56
……
然后我们查看一下实习僧站点返回的数据。
-
这其中又涉及到了编码的转换。
我们拿到一段带编码的文字,如下所示。
销售实习
接下来查看一下页面呈现的文字
SaaS软件销售实习生
其中  对应的是 S 字符,再看一下该字符在字体文件中的编码,如下所示。
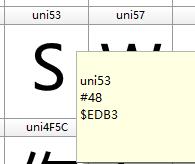
但是从刚才的结果中,并未得到 edb3 相关值,但是把十进制的编码进行转换之后,得到下述结果。
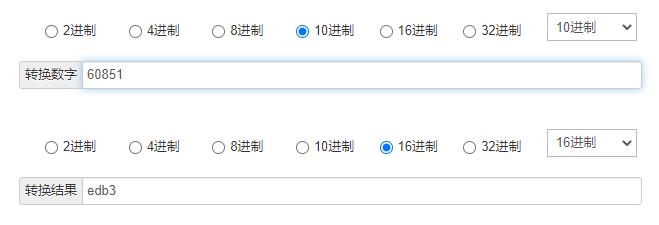
edb3 出现了,我们的本案例也完成了。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 669 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于敢看系列?Python字体反爬实战案例之实习那僧,继续挖坑的主要内容,如果未能解决你的问题,请参考以下文章