LSTM内部实现原理详解
Posted 走召大爷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSTM内部实现原理详解相关的知识,希望对你有一定的参考价值。
最近看到一个巨牛的人工智能教程,分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。平时碎片时间可以当小说看,【点这里可以去膜拜一下大神的“小说”】。
文章转自《https://blog.csdn.net/shenxiaoming77/article/details/79390595》
LSTM不经常用,所以每次看完原理后不久就会忘记,今天从【LSTM 实际神经元隐含层物理架构原理解析】 看到一篇对LSTM的详解,觉得写得挺好的,于是转载过来,文章排版格式上略作修改。
一些基于LSTM网络的NLP案例代码,涉及到一些input_size,num_hidden等变量的时候,可能容易搞混,首先是参照了知乎上的一个有关LSTM网络的回答https://www.zhihu.com/question/41949741, 以及github上对于LSTM比较清晰的推导公式http://arunmallya.github.io/writeups/nn/lstm/index.html#/3, 对于lstm cell中各个门处理,以及隐含层的实际物理实现有了更深刻的认识,前期一些理解上还模糊的点 也在不断的分析中逐渐清晰。
首先给出LSTM网络的三种不同的架构图:
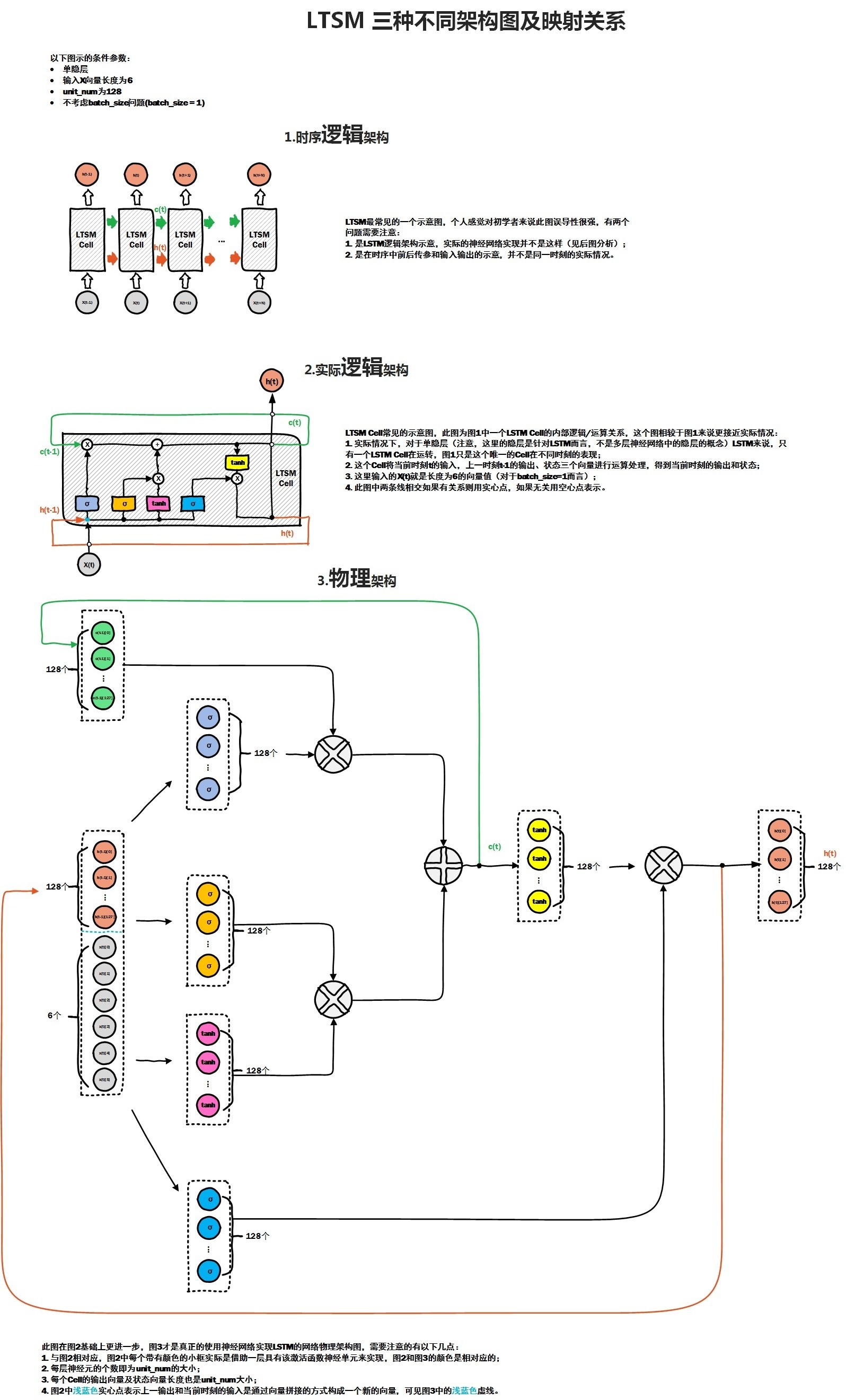
其中前两种是网上最常见的,图二相对图一,进一步解释了cell内各个门的作用。
在实际的神经网络中,各个门处理函数 其实是由一定数量的隐含层神经元来处理。
在
RNN中,M个神经元组成的隐含层,实际的功能应该是f(wx + b).
这里实现了两步:
- 首先
M个隐含层神经元与输入向量X之间全连接,通过w参数矩阵对x向量进行加权求和,其实就是对x向量各个维度上进行筛选,加上bias偏置矩阵。- 通过
f激励函数, 得到隐含层的输出。
而在LSTM Cell中,一个cell包含了若干个门处理函数,假如每个门的物理实现,我们都可以看做是由num_hidden个神经元来实现该门函数功能, 那么每个门各自都包含了相应的w参数矩阵以及bias偏置矩阵参数,就是在图3物理架构图中的实现。
从图3中可以看出,cell单元里有四个门,每个门都对应128个隐含层神经元,相当于四个隐含层,每个隐含层各自与输入x全连接,而输入x向量是由两部分组成,一部分是上一时刻cell 输出,大小为128, 还有部分就是当前样本向量的输入,大小为6,因此通过该cell内部计算后,最终得到当前时刻的输出,大小为128,即num_hidden,作为下一时刻cell的一部分输入。
比如在NLP场景下,当一个词向量维度为M时, 可以认为当前x维度为M,如果num_hidden = N, 那么与x全连接的某个隐含层神经元的w矩阵大小为 M * N, bias的维度为N, 所以平时我们在初始化lstm cell的时候,样本输入的embedding_size 与 num_hidden之间没有直接关联,而是会决定每个门的w矩阵维度, 而且之前的一片BasicLSTMCell源码分析中,我们提到了BasicLSTMCell 是直接要求embedding_size 与num_hidden 是相等的,这也大大简化了多个w矩阵的计算,这也说明了BasicLSTMCell是最简单和最常用的一种lstm cell
以上是关于LSTM内部实现原理详解的主要内容,如果未能解决你的问题,请参考以下文章