必知必会 - 使用kafka之前要掌握的知识
Posted 上帝De助手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了必知必会 - 使用kafka之前要掌握的知识相关的知识,希望对你有一定的参考价值。
必知必会系列之kafka
前记
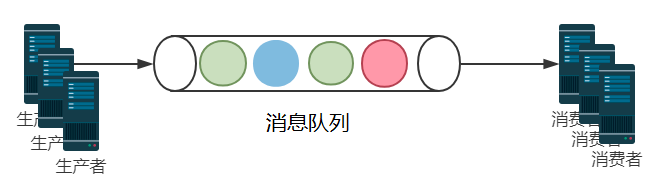
消息队列是分布式系统架构中不可或缺的基础组件,它主要负责服务间的消息通信和数据传输。
市面上有很多的开源消息队列服务可以选择,除了kafka,还有Activemq,Rocketmq等。
对于要选择哪一个服务需要根据的实际情况来定,今天主要介绍kafka。
kafka特性
大多数消息队列服务的主要功能都是大同小异,都能完成基本的消息传输和保障机制,只是在具体的实现细节上会有所不同。
而kafka也是有它独特的特性,主要体现在如下几个方面:
- 文件存储消息日志
- 支持高并发和大吞吐量
- 支持消息持久化
- 可以重复消费消息
除了这些之外的还有通用消息队列服务的标配。比如:
- 支持队列和订阅2种消息传输方式
- 支持集群部署
- 支持多机备份
kafka实现
相比于其它的消息队列服务在内存中存储消息而言,kafka最大的特点就是使用文件存储消息日志。并且这也没有导致kafka的读取性能和整体的吞吐量。
而之所以能达到这样的效果,还要取决于它的设计原理,即保证了高速读写(read before|write behind),又保证了并发效率。
顺序写
kafka之所以能高速写,是因为利用了磁盘的顺序写的特性。经测试发现磁盘的顺序写甚至比内存的随机读还要快很多,因此kafka在写文件时会批量的写入,并且追加到一个文件中。
高速读
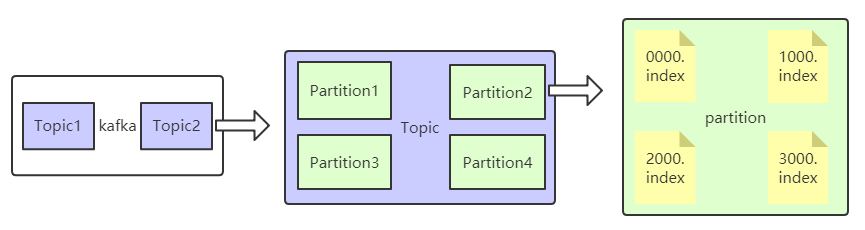
高速读除了因为连续读取,操作系统会有预读的机制之外,还体现在它的文件结构的设计。kafka把消息按topic分类,topic又可以按分区读写,分区再按索引文件分割存取。
这样当我们知道了topic、分区、offset之后,就可以通过O(1)的方式找到目标消息所在的位置。
概念介绍
kafka中有几个重要的概念:
- Topic
- partition
- Consumer Group
- offset
Topic:定义一个消息分类,相关的生产者和消费者通过特定的Topic来进行联通。
partition:Topic下的子概念,一个Topic通常可以分为1或多个partition,该Topic中的消息会分发到不同的partition中,也可以在代码中指定特定的partition。
Consumer Group:消费者组,它的作用的限定一组消费者,同组内的消费者在消费时是一种互斥模式;即同一个组内只有一个消费者可以消费到某个特定的消息。
offset:Topic中记录某条消息位置的偏移量信息,通常offset是消费者读取消息的依据。
分区和分组
分区即一个Topic设置了多个partition(默认是1个),分区有如下的优势:
- 支持分布式
- 支持负载并发请求
- 支持容灾备份
- 保证分区内的消费顺序
分组即把相关联的消费者放在一个组内(kafka对每个消费者会分配一个默认分组,如果不指定的话),分组有如下优势:
- 组内多个消费者可以并发处理(提高消费效率的方式)
- 消费者管理更加灵活
接着,在po一张分区和分组的关系图。
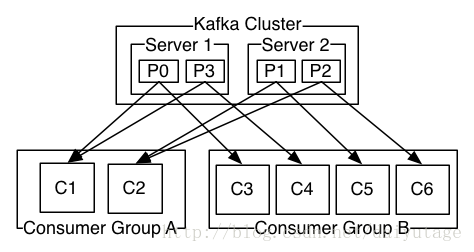
从图中可以看到的关系如下:
- Topic下的消息会分发给所有的订阅组
- 组内的消费者会各自消费不同的分区(且在分区和组内消费者数不变的情况下,关系是固定的)
- 一个消费者可以消费一或多个分区
- 一个分区只能被同一个组内的一个消费者消费
这个是设计相对合理的分区和消费者数量,组内消费者数 = 分区数 * N。如果分区数和消费者数设置不合理,则会有消费者永远拿不到数据。
所以,分区、分组是kafka支持高并发处理的基础。
队列还是分发
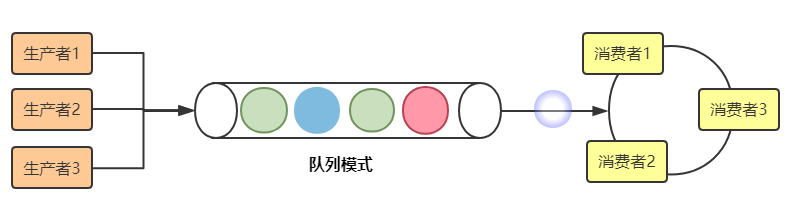
跟其它消息队列一样,kafka的消息模式也支持队列和分发订阅两种方式。
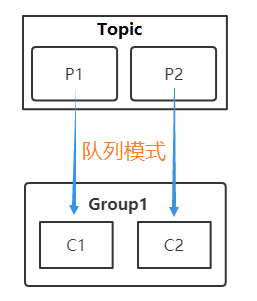
队列模式也称生产消费者模式,特点是同一个消息同时只能被一个消费者消费。其逻辑结构可以简单的通过下面的示意图来说明。
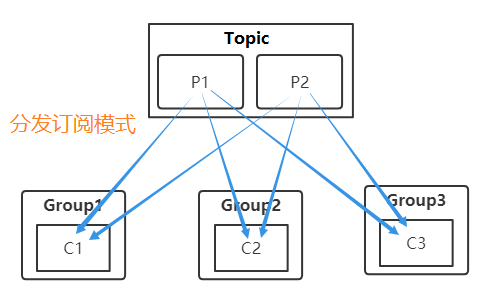
分发订阅模式的特点是同一个消息同时可以被所有的消费者消费。(类似于广播的形式)其逻辑结构的简单示意如下:
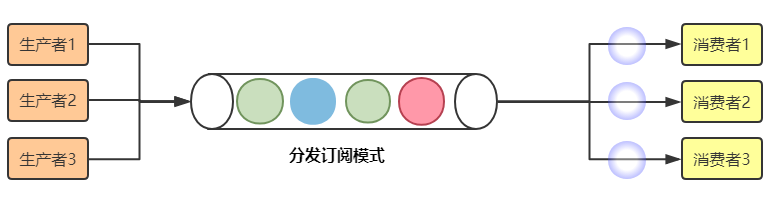
kafka中默认会把同一个消息分发给所有的订阅组(Consumer Group),即分发订阅模式。
如果想要实现队列模式,则把所有的消费者存放在一个Consumer Group内,且该Topic只有这一个组有订阅。kafka不同消费模式的示意如下:
消费方式
消息的消费方式是很多初用者会忽略的,因为简单场景下选择任意一种都是可以正常工作的,而到了生成环境可能就会出问题了。
kafka的消费方式有三种:
- At most once(消息最多被消费一次)
- At least once(消息最少被消费一次)
- Exactly once(消息刚好被消费一次)
前两者所有版本的kafka都支持,可以通过是否自动提交offset来控制。
默认kafka是会自动提交offset的,即属于第一种方式。如果设置为手动提交offset则属于第二种方式。
另外如果需要刚好一次的消费语义,则需要0.11以上的kafka版本。
如果你的版本不是0.11之后的,则可以通过At least once配合下游应用的幂等机制来实现。
API
https://kafka-python.readthedocs.io/en/master/usage.html
获取更多感兴趣的文章,请扫描如下二维码!

以上是关于必知必会 - 使用kafka之前要掌握的知识的主要内容,如果未能解决你的问题,请参考以下文章