PPOCRv3模型转pytorch
Posted 三叔家的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PPOCRv3模型转pytorch相关的知识,希望对你有一定的参考价值。
序言
前段时间PaddleOCRv3版本发布,更新了检测和识别模型,性能有很大提升,本着能嫖就嫖的原则,刚出来的第一天就开始嫖上了,虽然新模型的性能相较于之前有较大提升,但是乍一看模型结构复杂了很多,部署起来要麻烦了很多,现阶段paddle框架转其他部署框架只能通过转paddle2onnx再转其他框架实现,所以打算踩下坑,提供import paddle as torch版本的模型:将paddle框架的模型权重转到pytorch上,为部署方案提供多一些选择,转换到pytorch框架上后可以通过从pytorch再转其他部署方式,举个之前的例子:使用pnnx把pytorch模型转ncnn模型。
与之前的模型性能对比:
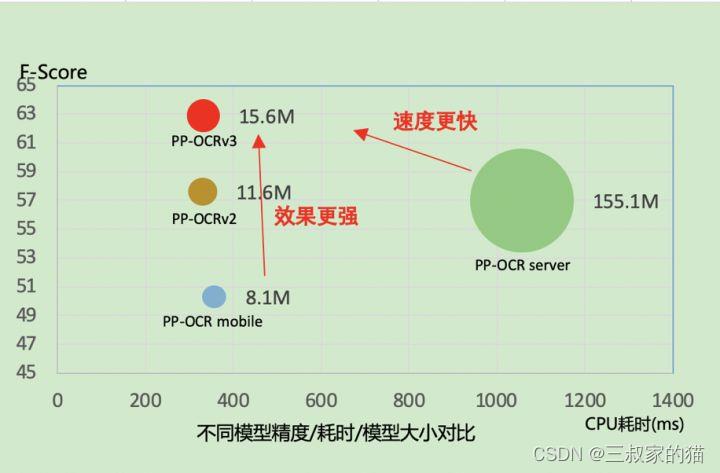
本项目代码实现基于:
一、paddle2torch
先说下转换原理,因为paddlepaddle和pytorch都是动态框架,所以转换起来比较简单,对于要转换的paddle模型,我们只需要用torch重新构建相同的网络模型结构,然后将paddle的权重取出,一一对应赋值进每一层。看似过程比较简单,但是毕竟是不同的框架,有些op实现也是不同的,难免会踩很多坑。
在转换之前,我们先看一下PaddleOCRV3相对于上一个版本的模型更新了那些模块:
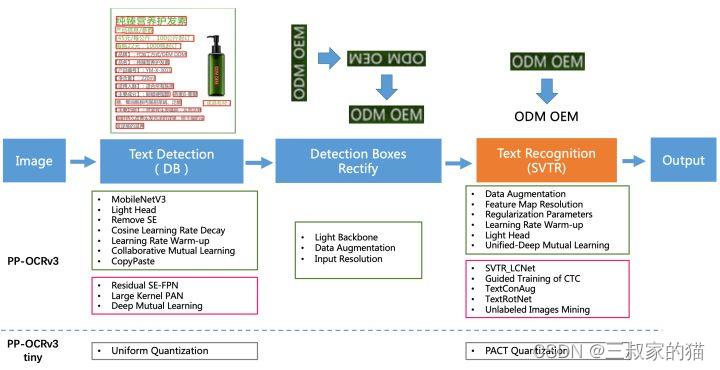
检测模块:
- LK-PAN:大感受野的PAN结构
- DML:教师模型互学习策略
- RSE-FPN:残差注意力机制的FPN结构
识别模块:
- SVTR_LCNet:轻量级文本识别网络
- GTC:Attention指导CTC训练策略
- TextConAug:挖掘文字上下文信息的数据增广策略
- TextRotNet:自监督的预训练模型
- UDML:联合互学习策略
- UIM:无标注数据挖掘方案
具体的可以看PPOCRV3官方的技术报告,在这里我们只需要关注我们转换的过程需要注意的那些模块即可
二、检测模型转换
首先是检测模块,检测模块有三部分更新,我们只需要关注RSE-FPN,因为前两个都是在训练过程中蒸馏学习对教师模型的优化。
RSE-FPN(Residual Squeeze-and-Excitation FPN)如下图所示,引入残差结构和通道注意力结构,将FPN中的卷积层更换为通道注意力结构的RSEConv层,进一步提升特征图的表征能力。考虑到PP-OCRv2的检测模型中FPN通道数非常小,仅为96,如果直接用SEblock代替FPN中卷积会导致某些通道的特征被抑制,精度会下降。RSEConv引入残差结构会缓解上述问题,提升文本检测效果。进一步将PP-OCRv2中CML的学生模型的FPN结构更新为RSE-FPN,学生模型的hmean可以进一步从84.3%提升到85.4%:
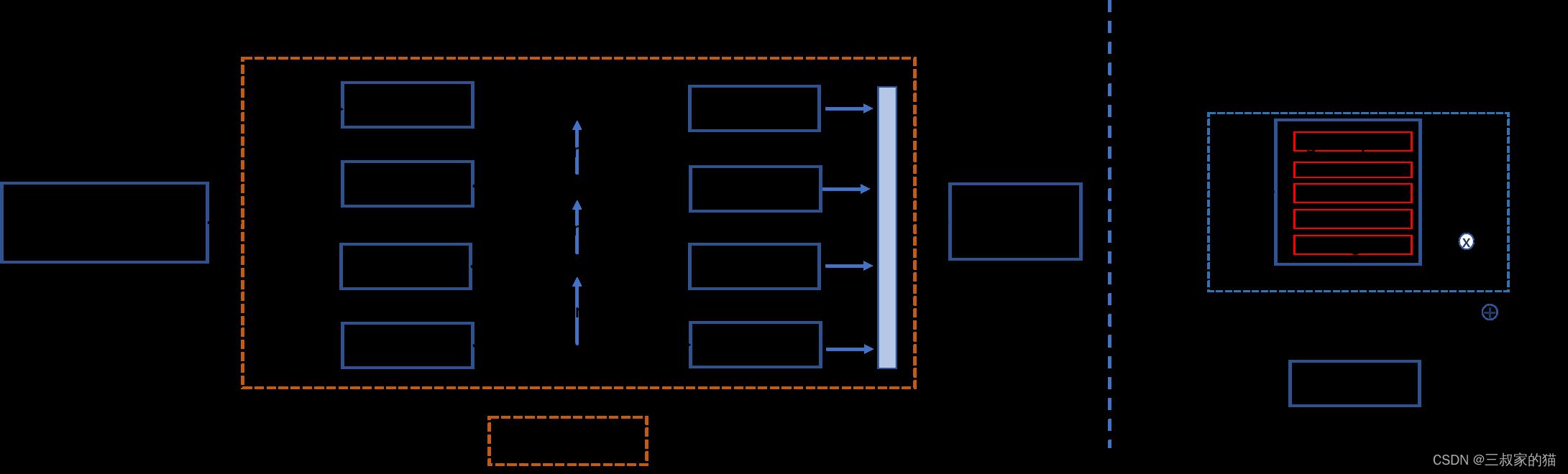
RSE-FPN pytorch代码实现:
class RSELayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, shortcut=True):
super(RSELayer, self).__init__()
self.out_channels = out_channels
self.in_conv = nn.Conv2d(
in_channels=in_channels,
out_channels=self.out_channels,
kernel_size=kernel_size,
padding=int(kernel_size // 2),
bias=False)
self.se_block = SEBlock(self.out_channels,self.out_channels)
self.shortcut = shortcut
def forward(self, ins):
x = self.in_conv(ins)
if self.shortcut:
out = x + self.se_block(x)
else:
out = self.se_block(x)
return out
class RSEFPN(nn.Module):
def __init__(self, in_channels, out_channels=256, shortcut=True, **kwargs):
super(RSEFPN, self).__init__()
self.out_channels = out_channels
self.ins_conv = nn.ModuleList()
self.inp_conv = nn.ModuleList()
for i in range(len(in_channels)):
self.ins_conv.append(
RSELayer(
in_channels[i],
out_channels,
kernel_size=1,
shortcut=shortcut))
self.inp_conv.append(
RSELayer(
out_channels,
out_channels // 4,
kernel_size=3,
shortcut=shortcut))
def _upsample_add(self, x, y):
return F.interpolate(x, scale_factor=2) + y
def _upsample_cat(self, p2, p3, p4, p5):
p3 = F.interpolate(p3, scale_factor=2)
p4 = F.interpolate(p4, scale_factor=4)
p5 = F.interpolate(p5, scale_factor=8)
return torch.cat([p5, p4, p3, p2], dim=1)
def forward(self, x):
c2, c3, c4, c5 = x
in5 = self.ins_conv[3](c5)
in4 = self.ins_conv[2](c4)
in3 = self.ins_conv[1](c3)
in2 = self.ins_conv[0](c2)
out4 = self._upsample_add(in5, in4)
out3 = self._upsample_add(out4, in3)
out2 = self._upsample_add(out3, in2)
p5 = self.inp_conv[3](in5)
p4 = self.inp_conv[2](out4)
p3 = self.inp_conv[1](out3)
p2 = self.inp_conv[0](out2)
x = self._upsample_cat(p2, p3, p4, p5)
return x
完整的网络分为三部分:Backbone(MobileNetV3)、Neck(RSEFPN)、Head(DBHead),借助于PytorchOCR项目,将这三部分分别实现,然后将网络搭建。
from torch import nn
from det.DetMobilenetV3 import MobileNetV3
from det.DB_fpn import DB_fpn,RSEFPN,LKPAN
from det.DetDbHead import DBHead
backbone_dict = 'MobileNetV3': MobileNetV3
neck_dict = 'DB_fpn': DB_fpn,'RSEFPN':RSEFPN,'LKPAN':LKPAN
head_dict = 'DBHead': DBHead
class DetModel(nn.Module):
def __init__(self, config):
super().__init__()
assert 'in_channels' in config, 'in_channels must in model config'
backbone_type = config.backbone.pop('type')
assert backbone_type in backbone_dict, f'backbone.type must in backbone_dict'
self.backbone = backbone_dict[backbone_type](config.in_channels, **config.backbone)
neck_type = config.neck.pop('type')
assert neck_type in neck_dict, f'neck.type must in neck_dict'
self.neck = neck_dict[neck_type](self.backbone.out_channels, **config.neck)
head_type = config.head.pop('type')
assert head_type in head_dict, f'head.type must in head_dict'
self.head = head_dict[head_type](self.neck.out_channels, **config.head)
self.name = f'DetModel_backbone_type_neck_type_head_type'
def load_3rd_state_dict(self, _3rd_name, _state):
self.backbone.load_3rd_state_dict(_3rd_name, _state)
self.neck.load_3rd_state_dict(_3rd_name, _state)
self.head.load_3rd_state_dict(_3rd_name, _state)
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
x = self.head(x)
return x
if __name__=="__main__":
db_config = AttrDict(
in_channels=3,
backbone=AttrDict(type='MobileNetV3', model_name='large',scale=0.5,pretrained=True),
neck=AttrDict(type='RSEFPN', out_channels=96),
head=AttrDict(type='DBHead')
)
model = DetModel(db_config)
然后使用paddleOCRV3的文字检测训练模型(注意只能用训练模型),将模型的权重和对应的键值取出,分别对应初始化到torch模型中,完整代码在文后链接。
def load_state(path,trModule_state):
"""
记载paddlepaddle的参数
:param path:
:return:
"""
if os.path.exists(path + '.pdopt'):
# XXX another hack to ignore the optimizer state
tmp = tempfile.mkdtemp()
dst = os.path.join(tmp, os.path.basename(os.path.normpath(path)))
shutil.copy(path + '.pdparams', dst + '.pdparams')
state = fluid.io.load_program_state(dst)
shutil.rmtree(tmp)
else:
state = fluid.io.load_program_state(path)
# for i, key in enumerate(state.keys()):
# print(" ".format(i, key))
state_dict =
for i, key in enumerate(state.keys()):
if key =="StructuredToParameterName@@":
continue
state_dict[trModule_state[i]] = torch.from_numpy(state[key])
return state_dict
三、识别模型转换
识别模型的转换相对于检测模型要复杂很多,PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力,上面的诸多识别优化中,我们只需要关注第一个优化:SVTR_LCNet,其他的都是训练过程中的训练技巧,在模型转换的过程中不需要用到。
SVTR_LCNet是针对文本识别任务,将基于Transformer的SVTR网络和轻量级CNN网络PP-LCNet 融合的一种轻量级文本识别网络,整体网络如下所示:
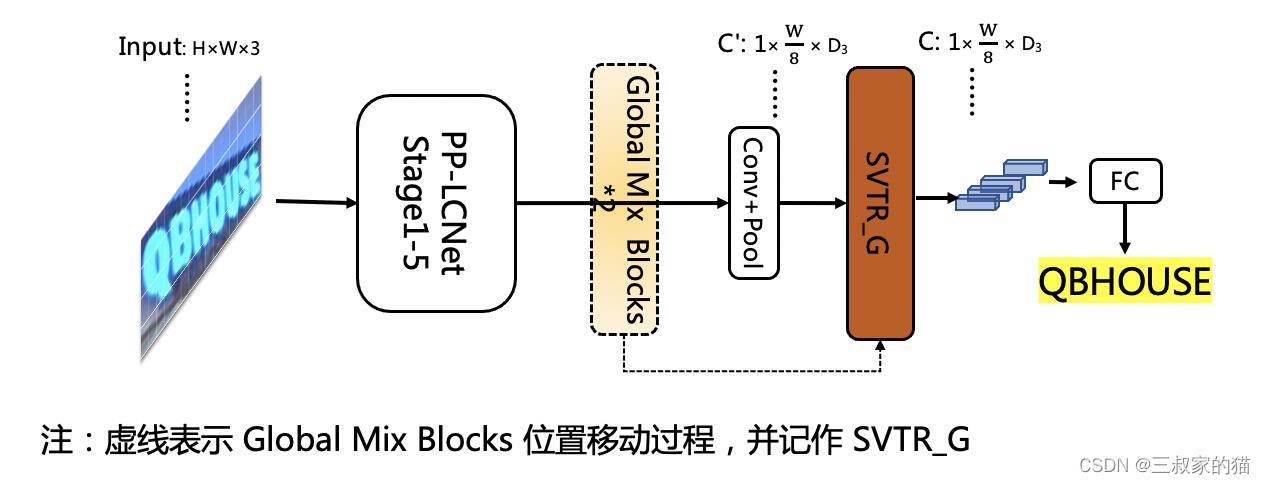
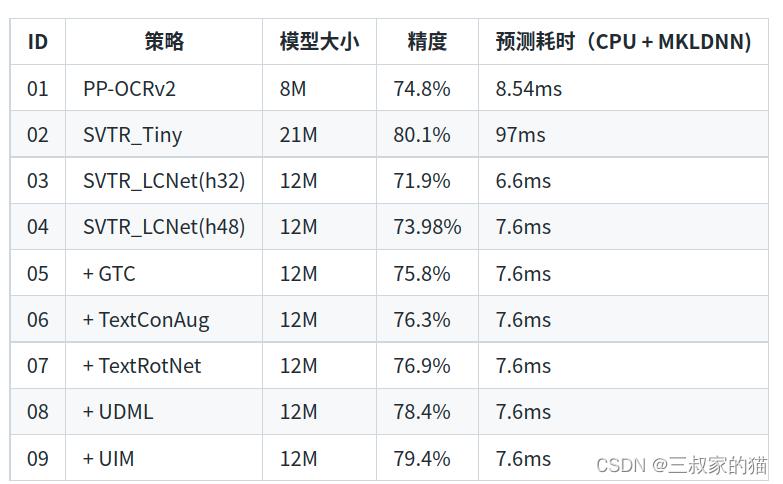
使用该网络,预测速度优于PP-OCRv2的识别模型20%,但是由于没有采用蒸馏策略,该识别模型效果略差。此外,进一步将输入图片规范化高度从32提升到48,预测速度稍微变慢,但是模型效果大幅提升,识别准确率达到73.98%(+2.08%),接近PP-OCRv2采用蒸馏策略的识别模型效果,消融实验过程:
同样的,根据paddle的识别网络结构构建torch网络模型,模型分为三部分:Backbone(LCNet)、Encoder(SVTR Transformers)、Head(MultiHead),其中Encoder部分使用了SVTR的Transformers结构编码:
class EncoderWithSVTR(nn.Module):
def __init__(
self,
in_channels,
dims=64, # XS
depth=2,
hidden_dims=120,
use_guide=False,
num_heads=8,
qkv_bias=True,
mlp_ratio=2.0,
drop_rate=0.1,
attn_drop_rate=0.1,
drop_path=0.,
qk_scale=None):
super(EncoderWithSVTR, self).__init__()
self.depth = depth
self.use_guide = use_guide
self.conv1 = ConvBNLayer(
in_channels, in_channels // 8, padding=1)
self.conv2 = ConvBNLayer(
in_channels // 8, hidden_dims, kernel_size=1)
self.svtr_block = nn.ModuleList([
Block(
dim=hidden_dims,
num_heads=num_heads,
mixer='Global',
HW=None,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
act_layer="Swish",
attn_drop=attn_drop_rate,
drop_path=drop_path,
norm_layer='nn.LayerNorm',
epsilon=1e-05,
prenorm=False) for i in range(depth)
])
self.norm = nn.LayerNorm(hidden_dims, eps=1e-6)
self.conv3 = ConvBNLayer(
hidden_dims, in_channels, kernel_size=1)
# last conv-nxn, the input is concat of input tensor and conv3 output tensor
self.conv4 = ConvBNLayer(
2 * in_channels, in_channels // 8, padding=1)
self.conv1x1 = ConvBNLayer(
in_channels // 8, dims, kernel_size=1)
self.out_channels = dims
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight)
def forward(self, x):
# for use guide
if self.use_guide:
z = x.clone()
z.stop_gradient = True
else:
z = x
# for short cut
h = z
# reduce dim
z = self.conv1(z)
z = self.conv2(z)
# SVTR global block
B, C, H, W = z.shape
z = z.flatten(2).permute([0, 2, 1])
for blk in self.svtr_block:
z = blk(z)
z = self.norm(z)
# last stage
z = z.reshape([-1, H, W, C]).permute([0, 3, 1, 2])
z = self.conv3(z)
z = torch.cat((h, z), dim=1)
z = self.conv1x1(self.conv4(z))
return z
Head部分是一个多头,但是在推理的时候实际上也只用了CTCHead,把训练时候的SARHead去掉了,所以这部分不需要在网络构建时加进去。
class MultiHead(nn.Module):
def __init__(self, in_channels, **kwargs):
super().__init__()
self.out_c = kwargs.get('n_class')
self.head_list = kwargs.get('head_list')
self.gtc_head = 'sar'
# assert len(self.head_list) >= 2
for idx, head_name in enumerate(self.head_list):
# name = list(head_name)[0]
name = head_name
if name == 'SARHead':
# sar head
sar_args = self.head_list[name]
self.sar_head = eval(name)(in_channels=in_channels, out_channels=self.out_c, **sar_args)
if name == 'CTC':
# ctc neck
self.encoder_reshape = Im2Seq(in_channels)
neck_args = self.head_list[name]['Neck']
encoder_type = neck_args.pop('name')
self.encoder = encoder_type
self.ctc_encoder = SequenceEncoder(in_channels=in_channels,encoder_type=encoder_type, **neck_args)
# ctc head
head_args = self.head_list[name]
self.ctc_head = eval(name)(in_channels=self.ctc_encoder.out_channels,n_class=self.out_c, **head_args)
else:
raise NotImplementedError(
' is not supported in MultiHead yet'.format(name))
def forward(self, x, targets=None):
ctc_encoder = self.ctc_encoder(x)
ctc_out = self.ctc_head(ctc_encoder, targets)
head_out = dict()
head_out['ctc'] = ctc_out
head_out['ctc_neck'] = ctc_encoder
return ctc_out # infer 不经过SAR直接返回
# # eval mode
# print(not self.training)
# if not self.training: # training
# return ctc_out
# if self.gtc_head == 'sar':
# sar_out = self.sar_head(x, targets[1:])
# head_out['sar'] = sar_out
# return head_out
# else:
# return head_out
完整的网络构建:
from torch import nn
from rec.RNN import SequenceEncoder, Im2Seq,Im2Im
from rec.RecSVTR import SVTRNet
from rec.RecMv1_enhance import MobileNetV1Enhance
from rec.RecCTCHead import CTC,MultiHead
backbone_dict = "SVTR":SVTRNet,"MobileNetV1Enhance":MobileNetV1Enhance
neck_dict = 'PPaddleRNN': SequenceEncoder, 'Im2Seq': Im2Seq,'None':Im2Im
head_dict = 'CTC': CTC,'Multi':MultiHead
class RecModel(nn.Module):
def __init__(self, config):
super().__init__()
assert 'in_channels' in config, 'in_channels must in model config'
backbone_type = config.backbone.pop('type')
assert backbone_type in backbone_dict, f'backbone.type must in backbone_dict'
self.backbone = backbone_dict[backbone_type](config.in_channels, **config.backbone)
neck_type = config.neck.pop('type')
assert neck_type in neck_dict, f'neck.type must in neck_dict'
self.neck = neck_dict[neck_type](self.backbone.out_channels, **config.neck)
head_type = config.head以上是关于PPOCRv3模型转pytorch的主要内容,如果未能解决你的问题,请参考以下文章