学习方法|一把解开Kafka背后机制的“钥匙”
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习方法|一把解开Kafka背后机制的“钥匙”相关的知识,希望对你有一定的参考价值。
在Kafka中有一个非常重要的角色:控制器,KafkaController,承担着Kafka核心运作机制,从本文开始将逐步深入Kafka内核,揭晓Kafka内部的运作机制,为更好的运维Kafka储备充足的弹药。
深入探究Kafka内核,我们将如何展开呢?经过笔者初略的浏览了KafkaController类的源码,发现Kafka的控制器严重依赖Zookeeper集群,而基于Zookeeper编程的常规套路:基于事件监听模型:
- Zookeeper创建相应的节点
- 创建Watch,监听节点的新增/修改/删除事件,并执行对应的事件回调函数。
基于此种编程模型,事件回调方法就成为我们探究Kafka的突破口,而kafka也为控制类事件定义了统一的接口:ControllerEvent,简单声明如下图所示:

关键信息如下:
- long enqueueTimeMs
进入请求队列的时间戳 - ControllerState
事件状态(应该用类型更加准确),例如ISR变更、Broker变更等。 - process()
事件的处理函数,由各个子类实现。
ControllerEvent的所有子类如下图所示:
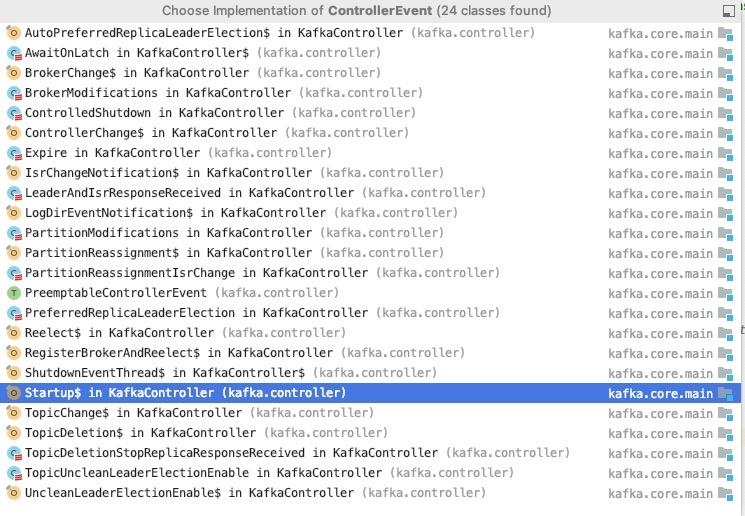
上面每一种事件都代表Kafka内核蕴含的一种机制,这些也是接下来探究的重点,本文将重点关注Startup事件,包含了Kafka控制器选举,揭晓控制器的职权范围。
1、Kafka控制选举机制
通过查看Kafka启动流程发现,Broker启动时首先会向/broker/ids节点下注册自己,然后会将Startup事件放入到任务队列中,从而将触发Controller的选举,Startup事件的定义如下图所示:

主要完成两件事情:
- 注册节点状态变更事件处理器,Kafka Controller会在zookeeper中创建节点/controller。
- 基于Zookeeper进行Kafka Controller选举。
接下来将详细探究其实现细节,将其运作机制掌握于心。
1.1 Kafka Controller选举机制
Kafka Controller的选举由具体由KafkaController的elect()方法实现,接下来将对该方法进行详细剖析。
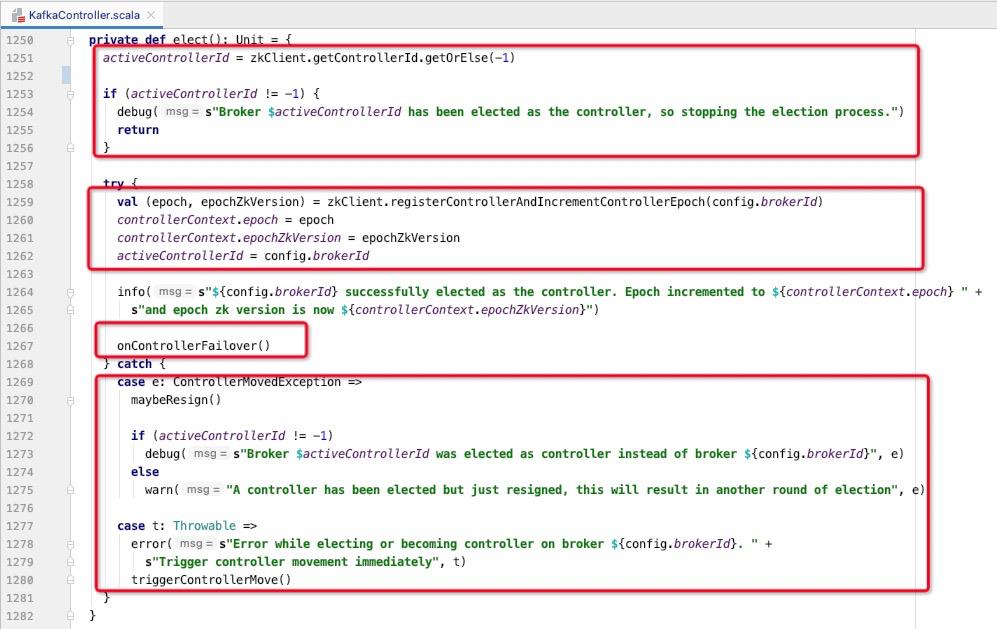
核心实现步骤如下:;
- 尝试从zookeeper中查看 /controller 节点中的内容,如果返回的值不等与-1,表示集群已经选举出KafkaController,则无需再次选举,直接返回。
- 发起KafkaController的选举,具体做法是尝试向zookeeper创建 /controller 节点,该行为会原子的返回如下两种结果:
- 节点已经存在
如果节点已经存在,则说明其他Broker提前创建了该节点,也就是获得Controller选举的胜利,如果节点存在,则出发异常处理(即当前节点没有成功选举后的善后操作,稍后会详细解读) - 节点成功创建
如果节点创建成功,则自己在本轮Controller选举中取得胜利,成功成为新的kafka Controller。
- 节点已经存在
- 如果节点成功被选举为新的Controller,则触发Controller故障转移的相关逻辑。
- 如果选举失败,则进行必要的善后工作,接下来探究。
1.1.1 Broker选举为Controller
当一个新节点被选举成Kafka Controller后,也就是“新的秩序”重新建立,需要做哪些事情呢?由KafkaController的onControllerFailover方法实现,该方法代码有点多,将分步骤介绍。
Step1:重新注册ChildChange事件,这类事件主要是关注其子节点的新增/删除/修改时间,代码如下图所示:

详情说明如下:
- /brokers/ids
每一个子节点代表一个Broker,监听broker的加入与下线并做出对应的响应 - /brokers/topics
记录所有主题的元信息,主要是分区信息(分区数量,各个分区的leader节点、ISR集合等)。 - /admin/delete_topics
待删除的topic。 - /log_dir_event_notification
如果当某一个Broker节点的日志读写出现异常,例如磁盘损坏,会向zookeeper,从而触发副本下线机制,触发相应的分区Leader选举 - /isr_change_notification
ISR变更通知
上述节点的事件监听,背后都蕴含了Kafka相关的机制,后续会一一揭晓。
Step2:重新注册Node节点改变事件,代码如下图所示:

具体订阅的节点如下:
- /admin/preferred_replica_election
副本倾向性选择 - /admin/reassign_partitions
分区在Broker直接重新分配机制
上述节点的事件监听,同样背后都蕴含了Kafka的相关机制,这些后续都会一一介绍,从而揭晓Kafka核心机制。
**Step3:**删除/log_dir_event_notification、/isr_change_notification相关的子节点,新的Controller节点选举成功后,分区故障转移,ISR变更都将忽略,这些事项后续会重新触发,代码如下图所示:

Step4:初始化控制器上下文,核心代码如下图所示:
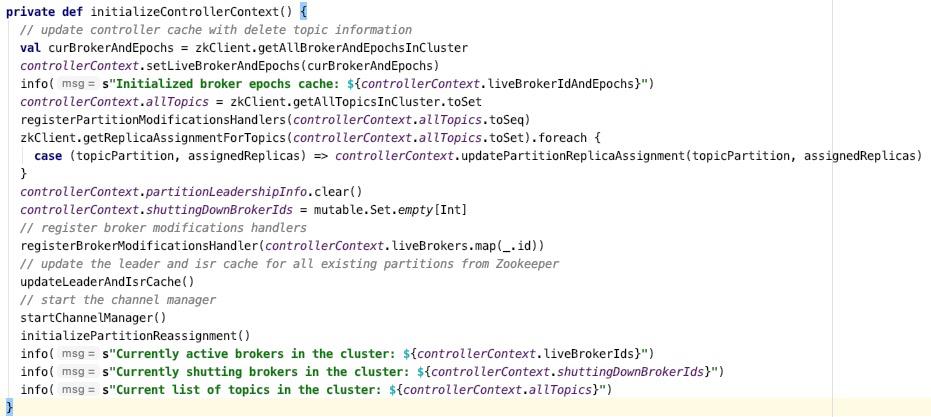
Kafka Controller的上下文主要包括如下信息:
-
获取当前所有活跃的Broker节点信息(获取 /brokers/ids 节点下的子节点)
-
获取集群中所有的Topic元数据,后续会将这些信息传播到各个Broker节点,也正是基于如此,生产者、消费者无需再连接Zookeeper。
-
为每一个主题创建Watch,监听主题的元信息变更事件。
-
获取每一个主题的分区分布情况,即每一个分区Leader所在的brokerId,副本在哪些Broker中,/broker/topics/topicName节点中存储的数据如下图所示:

-
为每一个/broker/ids/id broker注册节点内容变更事件,即可以监听broker元数据的变更,其实主要是监听endpoints的变化,如果发生变化,KafkaController会向所有注册(包括被认为正在关闭中的broker)发送UpdateMetadata命令。

-
从zk中加载所有分区的ISR与Leader Epoch,我们可以看看一个分区的状态:

-
启动控制器的通道管理器ControllerChannelManager,管理着控制器与集群内其他Broker中的控制通道,并且包含QueueSize、RequestRateAndQueueTimeMs等重要监控指标,这部分后续会深入展开。
-
读取/admin/reassign_partitions中的内容(Broker端分区重新分布计划),触发PartitionReassignmentIsrChangeHandler事件,关于分区重新分布的运维实战可以查阅笔者:https://mp.weixin.qq.com/s/X4zmnIg0zP3XFnogC45k4w
**Step5:**获取需要删除与不需要删除的topic,代码如下图所示:
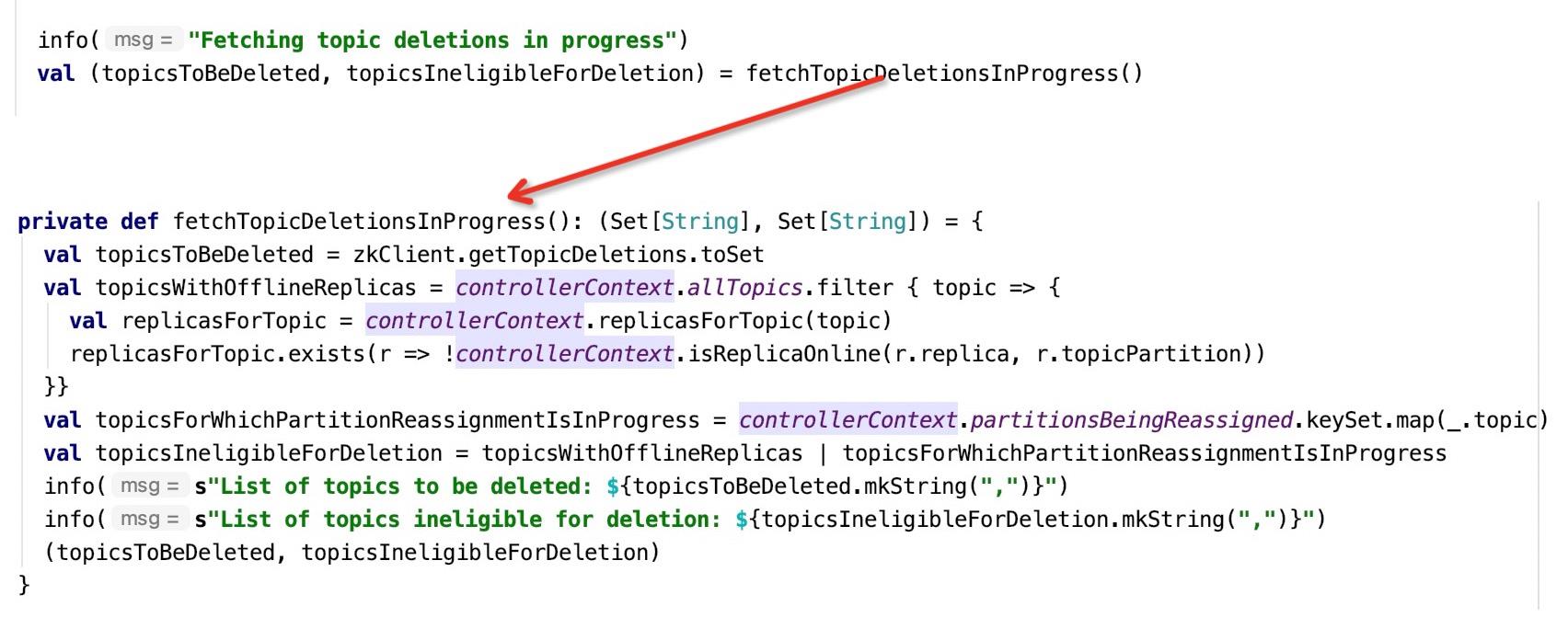
具体的处理逻辑:
- 首先从zookeeper中读取到 /kafka_cluster_01/admin/delete_topics节点下的所有topic,执行topic删除命令时首先会往该节点上添加一个节点。
- 这些节点中如果topic的分区的状态为online(在线)或者分区在执行分区移动,则这些topic将不会立即被删除,存入topicsIneligibleForDeletion集合中。
**Step6:**启动副本状态机与分区状态机,代码如下图所示:

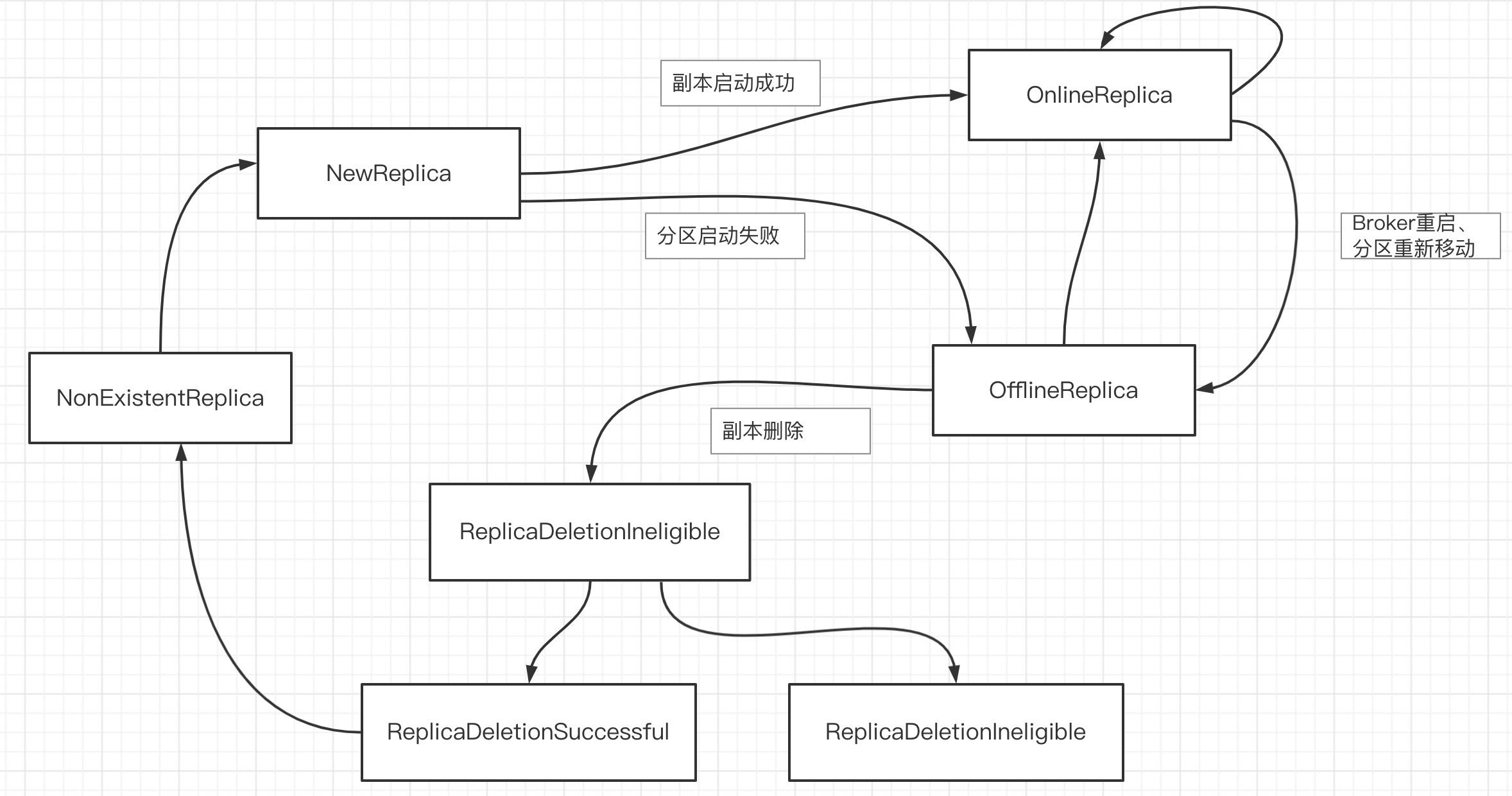
Kafka中分区、副本是存储的核心,分区、副本各自有多种状态,在Kafka内部实现中使用状态机来实现,其中副本的状态机状态驱动示意图如下所示:
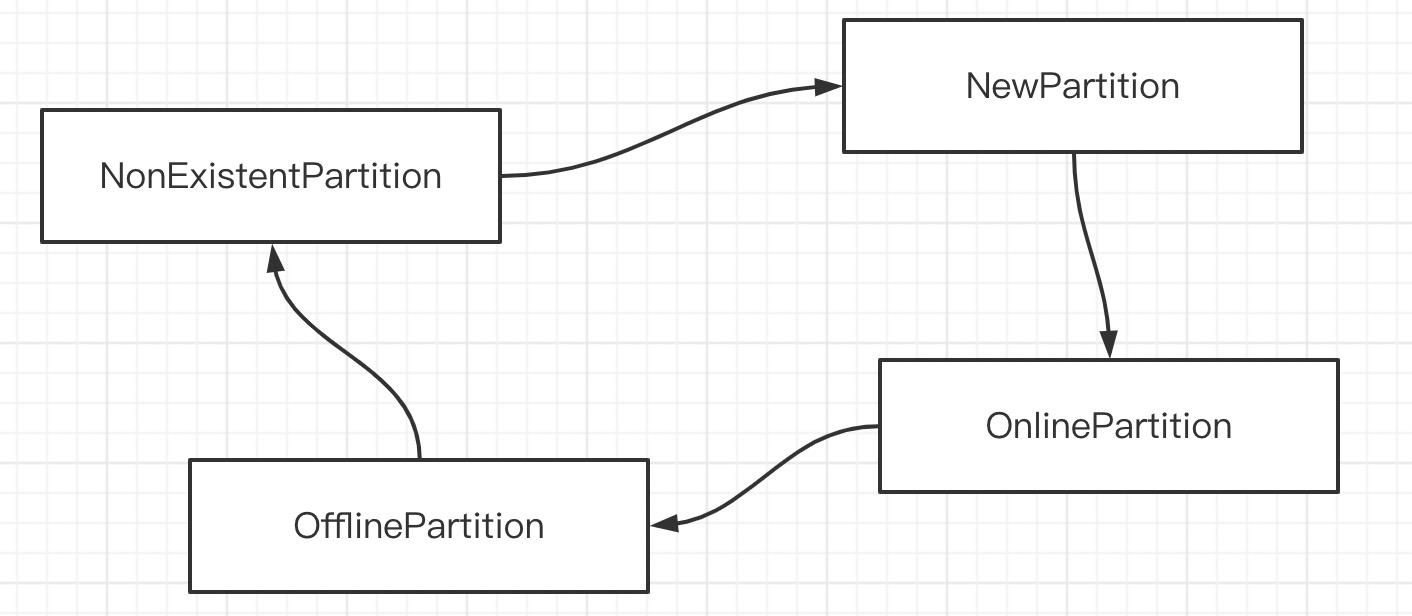
分区的状态比较简单,其状态驱动如下图所示:
Step7:处理分区重分配、topic删除、触发倾向性副本的选举,具体代码如下图所示:
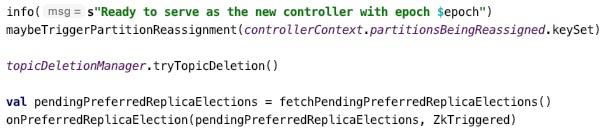
核心要点:
- 如果/admin/reassign_partitions中节点存储了topic的分区的重分配计划,则控制器选举成功后需要触发该部分逻辑的处理。
- 如果Broker端允许删除topic,配置项(delete.topic.enable),默认为true,如果/admin/delete_topics节点存在子节点,并且需要执行删除动作,则触发主题的删除动作。
- 如果/admin/preferred_replica_election节点存储了需要进行倾向性选举,则触发倾向性选举。
温馨提示:本文将不会深入探讨这些机制的详细实现,但这里送大家一个**“彩蛋”**,也是笔者的学习方法:大家可以去判断这些节点值是在什么情况下写入的、写入后是如何执行对应逻辑的,从而可以探知对应的实现机制。
1.1.2 Broker选举Controller失败
在Kafka集群中,只有一个Broker能成功选举成Controller,当Broker选举Controller失败后,执行的操作为KafkaController的maybeResign方法, 接下来我们看看其实现细节。
maybeResign方法的代码截图如下图所示:
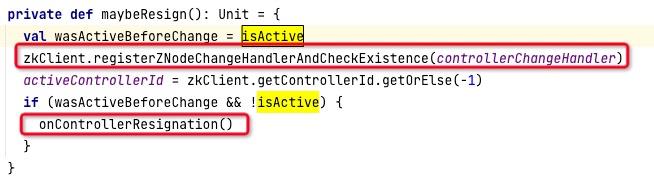
重点如图所示:
- 监听/controller节点,如果该节点被删除,则会触发KafkaController的选举。
- 如果当前节点从KafkaController角色变为非Controller角色,需要取消相关节点事件的注册,如下图所示:
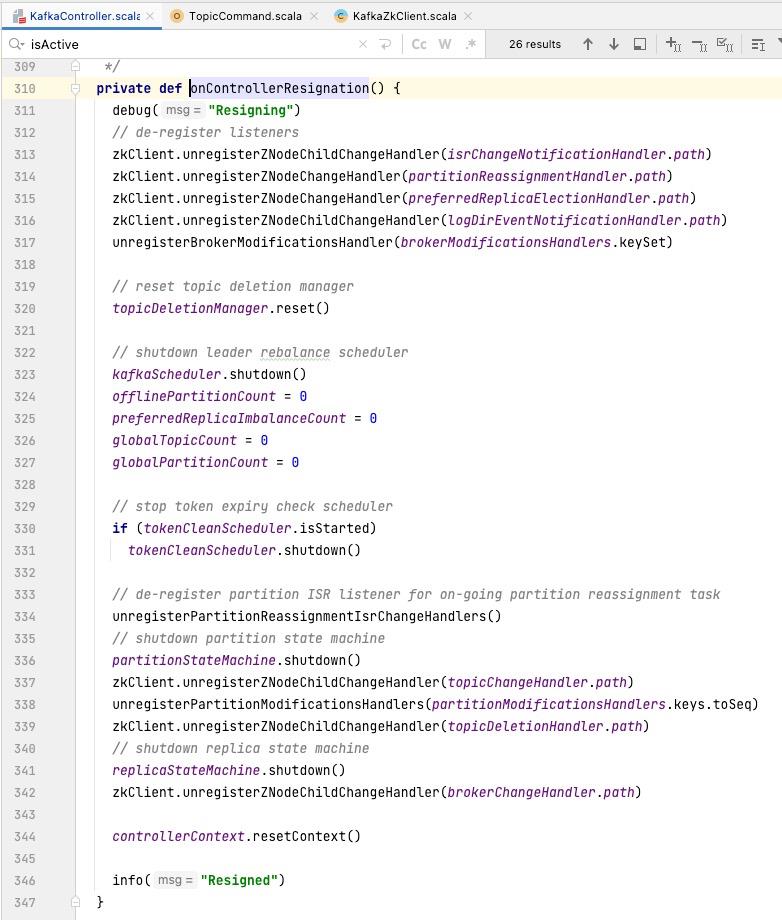
2、Kafka Conntroller职责总结
从Kafka Broker控制器的启动流程,我们也可以窥探出Kafka众多的机制都需要Kafka Controller主导,主要包含如下:
- 元信息同步(Topic路由信息)
- 删除主题
- 副本故障转移机制
- ISR变更机制
- 分区副本倾向性选举
- 分区重新分配(移动)机制
- 分区、副本状态管理
要想理解kafka内部的运作机制,Kafka Controller是一个非常不错的入口,从下文开始,将逐步研究Kafka内部运作机制,从而更好运维Kafka集群。
文章首发:https://www.codingw.net/posts/c3bb6e0e.html
一键三连(关注、点赞、留言)是对我最大的鼓励。
各位技术朋友们,我是《RocketMQ技术内幕》一书作者,CSDN2020博客之星TOP2,热衷于中间件领域的技术分享,维护「中间件兴趣圈」公众号,旨在成体系剖析Java主流中间件,构建完备的分布式架构体系,欢迎大家大家关注我,回复「专栏」可获取15个专栏;回复「PDF」可获取海量学习资料,回复「加群」可以拉你入技术交流群,零距离与BAT大厂的大神交流。
以上是关于学习方法|一把解开Kafka背后机制的“钥匙”的主要内容,如果未能解决你的问题,请参考以下文章