Golang 基础:底层并发原语 Mutex RWMutex Cond WaitGroup Once等使用和基本实现
Posted 拭心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang 基础:底层并发原语 Mutex RWMutex Cond WaitGroup Once等使用和基本实现相关的知识,希望对你有一定的参考价值。
文章目录
上一篇 《原生并发 goroutine channel 和 select 常见使用场景》 介绍了基于 CSP 模型的并发方式。
除了 CSP,Go 通过 sync 包以及 atomic 包还提供了一些更底层的同步 API,一般用于性能要求比较高的场景。
sync.Mutex 实现的同步机制的性能要比 channel 实现的高出三倍多。
在 sync/mutex.go 中,有这么一段注释:
// Package sync provides basic synchronization primitives such as mutual
// exclusion locks. Other than the Once and WaitGroup types, most are intended
// for use by low-level library routines. Higher-level synchronization is
// better done via channels and communication.
//
// Values containing the types defined in this package should not be copied.
注释的大概意思是,sync 包提供的是底层并发原语,一般给底层库用的,如果是上层业务同步,最好还是使用 channel。
还有一点,在日常编码中,不要使用拷贝的并发包对象。首先拷贝的对象,和原本不是一个内容,状态不一致;其次如果被拷贝的锁对象已经是锁定状态,可能会导致副本也是锁定状态,超出预期。
如果需要多处使用,可以使用全局变量或者指针传递(& 创建,* 使用)。
只有拥有数据对象所有权(从 channel 接收到该数据)的 Goroutine 才可以对该数据对象进行状态变更。
互斥锁 Mutex
Mutex 和 RMMutex 的作用和 Java 里的类似,主要来看下 API 和基本实现。
使用:
mu := sync.Mutex
mu.Lock() //加互斥锁
mu.Unlock()
实现:
// A Mutex is a mutual exclusion lock.
// The zero value for a Mutex is an unlocked mutex.
//
// A Mutex must not be copied after first use.
type Mutex struct
state int32
sema uint32
实现很简单,一个是状态,另一个是信号量。
拷贝使用 Mutex 的问题
来通过代码看一下拷贝使用 sync.Mutex 的问题。
var num int = 1
func testCopyMutex()
mu := sync.Mutex
waitGroup := sync.WaitGroup
waitGroup.Add(1)
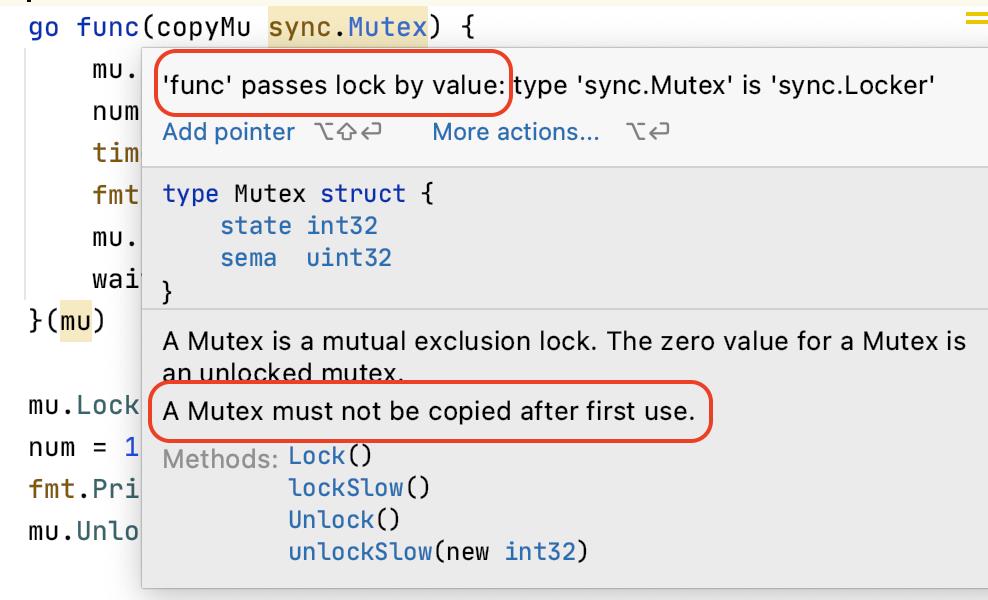
go func(copyMu sync.Mutex)
copyMu.Lock()
num = 100
fmt.Println("update num from sub-goroutine: ", num)
time.Sleep(5 * time.Second)
fmt.Println("read num from sub-goroutine: ", num)
copyMu.Unlock()
waitGroup.Done()
(mu)
time.Sleep(time.Second)
mu.Lock()
num = 1
fmt.Println("read num from main: ", num)
mu.Unlock()
waitGroup.Wait()
上面的代码中,我们子 goroutine 里先加锁,然后修改了 num,在等待 5s 后,输出了 num 的值,然后才释放锁;在这期间,主 goroutine 里会尝试获取锁,然后修改 num。
我们期望的是传递的同一个 Mutex,那子 goroutine 里在释放锁之前,num 都是它修改后的值,但允许的结果却让人意外:
update num from sub-goroutine: 100
read num from main: 1
read num from sub-goroutine: 1
可以看到,在真正运行时,子 goroutine 加锁的时间内,主 goroutine 居然也可以访问到 num。
问题的原因就在于传递的是 Mutex 的值。
如果改成传递指针,结果就会符合预期:
go func(copyMu *sync.Mutex) //参数类型加 *
copyMu.Lock()
num = 100
fmt.Println("update num from sub-goroutine: ", num)
time.Sleep(5 * time.Second)
fmt.Println("read num from sub-goroutine: ", num)
copyMu.Unlock()
waitGroup.Done()
(&mu) //传递指针
为什么传递值会有问题呢?
原因在于,Mutex 复制后,状态分离。子 goroutine 对副本加锁,主 goroutine 感知不到,因为它们使用的不是同一份数据了!
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock()
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked)
if race.Enabled
race.Acquire(unsafe.Pointer(m))
return
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
读写锁 RWMutex
使用:
rmu := sync.RWMutex
rmu.RLock() //读锁
rmu.RUnlock()
rmu.Lock() //写锁
rmu.Unlock()
rmu.RLocker().Lock() //通过 RLock 实现
rmu.RLocker().Unlock()
实现:
// A RWMutex is a reader/writer mutual exclusion lock.
// The lock can be held by an arbitrary number of readers or a single writer.
// The zero value for a RWMutex is an unlocked mutex.
//
// A RWMutex must not be copied after first use.
//
// If a goroutine holds a RWMutex for reading and another goroutine might
// call Lock, no goroutine should expect to be able to acquire a read lock
// until the initial read lock is released. In particular, this prohibits
// recursive read locking. This is to ensure that the lock eventually becomes
// available; a blocked Lock call excludes new readers from acquiring the
// lock.
type RWMutex struct
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
readerWait int32 // number of departing readers
可以看到,RWMutex 的成员有一个互斥锁(用于在写入时获取),读写者的信号量,读者数量等。
RWMutext 读不阻塞读,但会阻塞写。
// Lock locks rw for writing.
// If the lock is already locked for reading or writing,
// Lock blocks until the lock is available.
func (rw *RWMutex) Lock()
if race.Enabled
_ = rw.w.state
race.Disable()
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0
runtime_SemacquireMutex(&rw.writerSem, false, 0)
if race.Enabled
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
在调用写锁时,就是获取其中的互斥锁。
再多废话一句:读写锁适合并发量级比较大,且读的次数大于写的情况。
互斥锁和读写锁的注意点:
- 减少锁的范围
- 千千万万记得 unlock,可以早点写 defer unlock,避免忘记
条件变量 Cond
sync.Cond,在需要“等待某个条件成立”的场景下使用,使用的很少。
支持多个 goroutine 等待某个条件,等条件允许后,广播唤醒这些 goroutine 执行。
比起轮训互斥的状态,条件变量消耗资源更小,实现也更简单。
使用:
cond := sync.NewCond(&sync.Mutex) 参数为 sync.Locker 接口类型
go func()
// cond.L.Lock()
// for !condition()
cond.Wait() //等待,一般放在循环里,查询一次,不满足就阻塞(释放锁),等被唤醒后,再检查下条件
//
// ... make use of condition ...
// cond.L.Unlock()
()
cond.L.Lock() //获取构造传入的锁
cond.Broadcast() //通知所有等待的 goroutine,从 Wait 返回,重新获取锁
cond.Signal() //通知一个
cond.L.Unlock()
sync.Cond.Wait 一般结合 for 循环使用,反复检查条件是否满足。
实现:
// Cond implements a condition variable, a rendezvous point
// for goroutines waiting for or announcing the occurrence
// of an event.
//
// Each Cond has an associated Locker L (often a *Mutex or *RWMutex),
// which must be held when changing the condition and
// when calling the Wait method.
//
// A Cond must not be copied after first use.
type Cond struct
noCopy noCopy
// L is held while observing or changing the condition
L Locker
notify notifyList
checker copyChecker
// NewCond returns a new Cond with Locker l.
func NewCond(l Locker) *Cond
return &CondL: l
可以看到,条件主要由一个锁和一个等待唤醒的队列组成。
func (c *Cond) Wait()
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
在等待一个条件时,会先加入等待队列,然后释放这个条件的锁。
func (c *Cond) Broadcast()
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
广播时,会通知所有等待的 goroutine 恢复执行 Wait 里的逻辑,重新申请获取锁。
等待组 WaitGroup
在需要等待多个 goroutine 完成任务后继续执行的场景,可以使用 sync.WaitGroup,和 Java 的 CountDownLaunch 类似。
使用:
waitGroup := sync.WaitGroup
waitGroup.Add(1) //需要等待数为 1
go func()
waitGroup.Done() //减去需要等待数
()
waitGroup.Wait() //等待数为 0 才继续执行,循环检查
实现:
type WaitGroup struct
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers do not ensure it. So we allocate 12 bytes and then use
// the aligned 8 bytes in them as state, and the other 4 as storage
// for the sema.
state1 [3]uint32
可以看到,WaitGroup 核心就是一个计数的 state,高位 32 位为数量,低位 32 位为等待的数量。
// Wait blocks until the WaitGroup counter is zero.
func (wg *WaitGroup) Wait()
statep, semap := wg.state()
if race.Enabled
_ = *statep // trigger nil deref early
race.Disable()
for
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
if v == 0
// Counter is 0, no need to wait.
if race.Enabled
race.Enable()
race.Acquire(unsafe.Pointer(wg))
return
// Increment waiters count.
//...
当调用 waitGroup.Wait() 时,会去循环检查 state,只有当高 32 位为 0(即当前执行的任务为 0)时才会返回,否则就会增加低为然后继续循环。
可想而知,调用 Done 就是高位减 1,就暂不赘述了。
仅执行一次 Once
见字如面,sync.Once 用于保证传入的函数只执行一次。
在有些高并发的场景下,可能会有这种需求:多个 goroutine 同时执行任务 A,哪个先跑完就去执行任务 B,跑得慢的不需要执行。
使用:
once := sync.Once
once.Do(func()
fmt.Println("do the work that only need exec once")
)
实现也很简单:
type Once struct
// done indicates whether the action has been performed.
// It is first in the struct because it is used in the hot path.
// The hot path is inlined at every call site.
// Placing done first allows more compact instructions on some architectures (amd64/386),
// and fewer instructions (to calculate offset) on other architectures.
done uint32
m Mutex
Once 的实现就是一个状态值和一个互斥锁。
func (o *Once) Do(f func())
// Note: Here is an incorrect implementation of Do:
//
// if atomic.CompareAndSwapUint32(&o.done, 0, 1)
// f()
//
//
// Do guarantees that when it returns, f has finished.
// This implementation would not implement that guarantee:
// given two simultaneous calls, the winner of the cas would
// call f, and the second would return immediately, without
// waiting for the first's call to f to complete.
// This is why the slow path falls back to a mutex, and why
// the atomic.StoreUint32 must be delayed until after f returns.
if atomic.LoadUint32(&o.done) == 0
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
func (o *Once) doSlow(f func())
o.m.Lock()
defer o.m.Unlock()
if o.done == 0
defer atomic.StoreUint32(&o.done, 1)
f()
当首次执行时,会通过原子操作修改其中的 done 状态(这个过程需要获取互斥锁)。后面再执行 Do,发现状态不对,就不会执行了。
原子操作
在前面看并发包的一些实现时,发现多多少少都是使用 atomic 进行实现,比如 WaitGroup#Wait:
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
atomic 原子操作,只能同步一个整型变量或自定义类型变量,更适合一些对性能十分敏感、并发量较大且读多写少的场合。
原子操作由底层硬件直接提供支持,是一种硬件实现的指令级的“事务”
atomic 原子操作的特性:随着并发量提升,使用 atomic 实现的共享变量的并发读写性能表现更为稳定,尤其是原子读操作,和 sync 包中的读写锁原语比起来,atomic 表现出了更好的伸缩性和高性能
无论整型变量和自定义类型变量,atomic的操作实质上针对的都是字长长度的指针。在64位cpu上就是8个字节。因为CPU通过数据总线,一次从内存中最多只能获取一个字长的信息。所以atomic的限制也是一个字长。
其他
虽然都在 sync 包中,但 sync.WaitGroup,Map,Pool 层级更高一些,是基于 Mutex、RWMutex 和 Cond 这三个基本原语之上实现的机制。
Go 团队认为递归锁或可重入锁是一个不好的语法,所以不支持。
以上是关于Golang 基础:底层并发原语 Mutex RWMutex Cond WaitGroup Once等使用和基本实现的主要内容,如果未能解决你的问题,请参考以下文章