生产环境kafka日志集群400W/tps就扛不住了
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生产环境kafka日志集群400W/tps就扛不住了相关的知识,希望对你有一定的参考价值。
大家好,我是威哥,《RocketMQ技术内幕》作者、RocketMQ社区首席布道师、中通快递基础架构资深架构师,越努力越幸运,唯有坚持不懈,与大家共勉。
最近公司日志Kafka集群出现了性能瓶颈,单节点还没达到60W/tps时消息发送就出现了很大延迟,甚至最高超过了10s,截图说明如下:
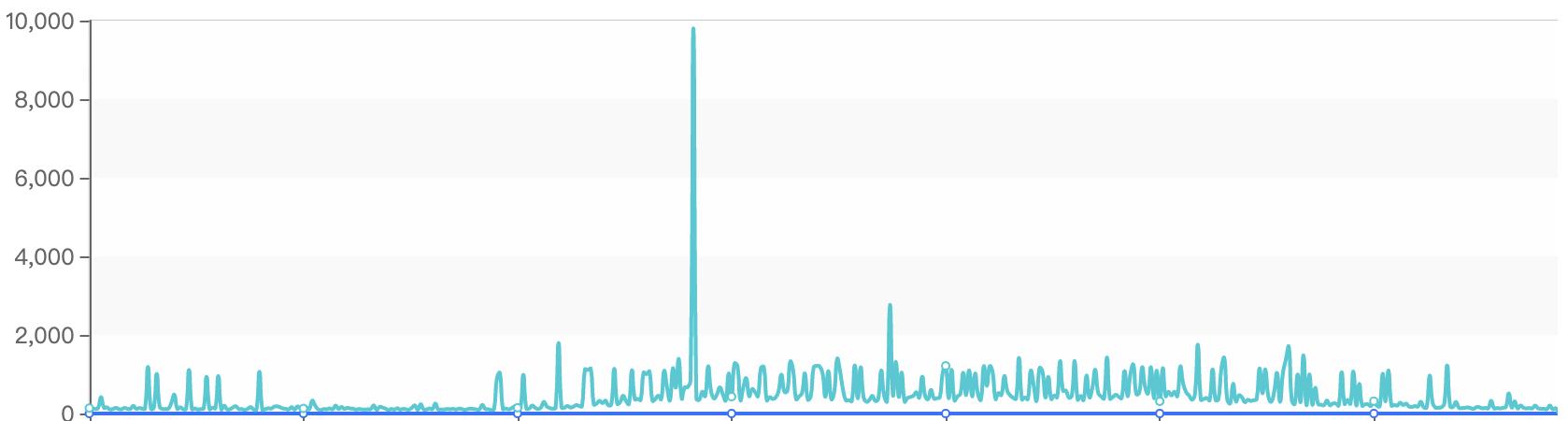
虽说使用的机械磁盘,但这点压力对Kafka来说应该是小菜一碟,这引起了我的警觉,需要对其进行一番诊断了。
通过监控平台观察Kafka集群中相关的监控节点,发现cpu使用率才接近20%左右,磁盘IO等待等指标都并未出现任何异常,那会是什么问题呢?
通常CPU耗时不大,但性能已经明显下降了,我们优先会去排查kafka节点的线程栈,获取线程栈的方法比较简单,命令为:
ps -ef | grep kafka // 获取pid
jstack pid > j1.log
通过上述命令我们就可以获取到kafka进程的堆栈信息,通过查看线程名称中包含kafka-request-handler字眼的线程(Kafka中处理请求),发现了大量的锁等待,具体截图如下所示:

并且在jstack文件中发现很多线程都在等待这把锁,截图如下:
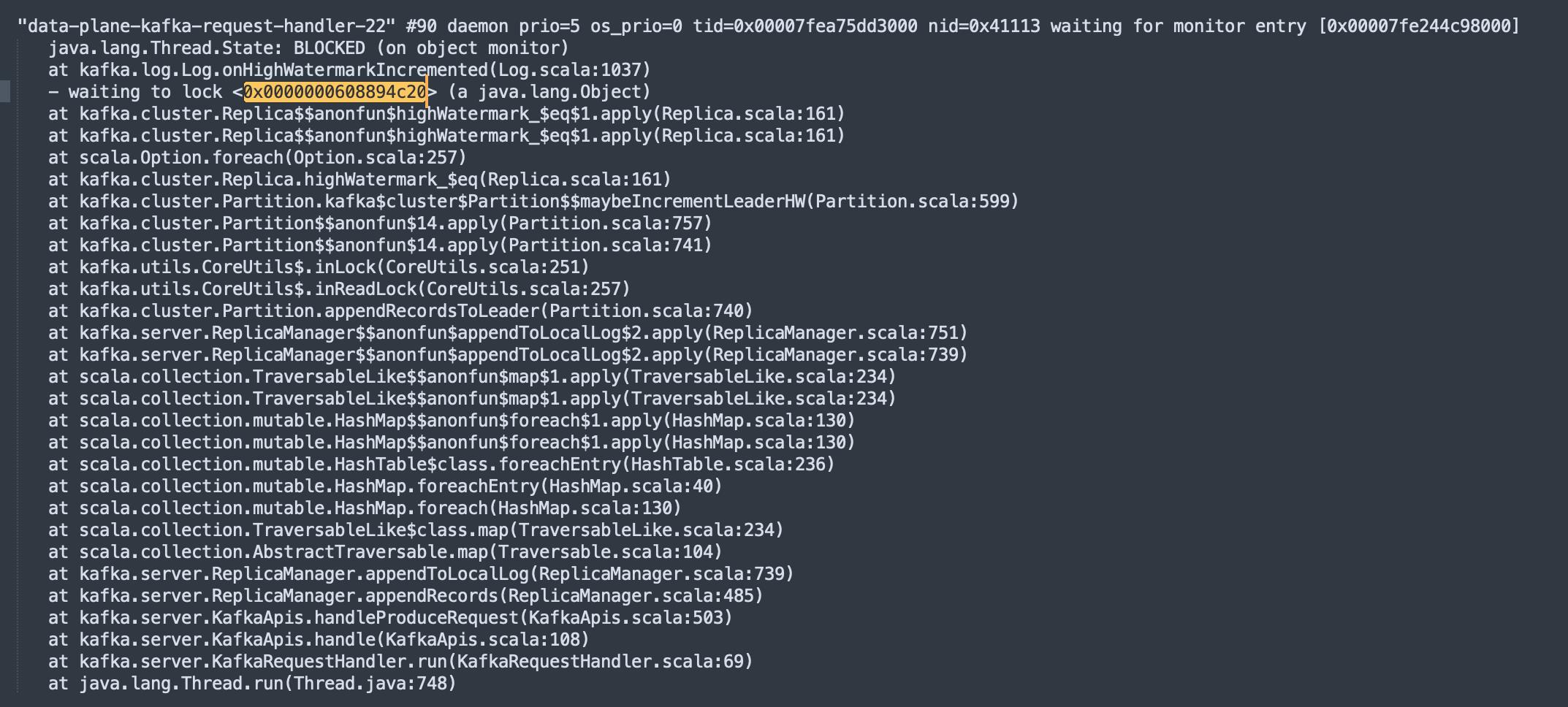
我们先根据线程堆栈查看代码,找到对应的源代码如下图所示:
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets: Boolean,
leaderEpoch: Int): LogAppendInfo =
maybeHandleIOException(s"Error while appending records to $topicPartition in dir $dir.getParent")
val appendInfo = analyzeAndValidateRecords(records, origin)
// return if we have no valid messages or if this is a duplicate of the last appended entry
if (appendInfo.shallowCount == 0)
return appendInfo
// trim any invalid bytes or partial messages before appending it to the on-disk log
var validRecords = trimInvalidBytes(records, appendInfo)
// they are valid, insert them in the log
lock synchronized
checkIfMemoryMappedBufferClosed()
if (assignOffsets)
// assign offsets to the message set
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(offset.value)
val now = time.milliseconds
val validateAndOffsetAssignResult = try
LogValidator.validateMessagesAndAssignOffsets(validRecords,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
origin,
interBrokerProtocolVersion)
catch
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
//省略部分代码
通过阅读源码,这段代码是分区Leader在追加数据时为了保证写入分区时数据的完整性,对分区进行的加锁,即如果对同一个分区收到多个写入请求,则这些请求将串行执行,这个锁时必须的,无法进行优化,但仔细观察线程的调用栈,发现在锁的代码块出现了GZIPInputstream,进行了zip压缩,一个压缩处在锁中,其执行性能注定低下,那在什么时候需要在服务端进行压缩呢?
故我们继续看一下LogValidator的validateMessagesAndAssignOffsets方法,最终调用validateMessagesAndAssignOffsetsCompressed方法,部分代码截图如下所示:
def validateMessagesAndAssignOffsetsCompressed(records: MemoryRecords,
offsetCounter: LongRef,
time: Time,
now: Long,
sourceCodec: CompressionCodec,
targetCodec: CompressionCodec,
compactedTopic: Boolean,
toMagic: Byte,
timestampType: TimestampType,
timestampDiffMaxMs: Long,
partitionLeaderEpoch: Int,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion): ValidationAndOffsetAssignResult =
// No in place assignment situation 1 and 2
var inPlaceAssignment = sourceCodec == targetCodec && toMagic > RecordBatch.MAGIC_VALUE_V0
var maxTimestamp = RecordBatch.NO_TIMESTAMP
val expectedInnerOffset = new LongRef(0)
val validatedRecords = new mutable.ArrayBuffer[Record]
var uncompressedSizeInBytes = 0
for (batch <- records.batches.asScala)
validateBatch(batch, origin, toMagic)
uncompressedSizeInBytes += AbstractRecords.recordBatchHeaderSizeInBytes(toMagic, batch.compressionType())
// Do not compress control records unless they are written compressed
if (sourceCodec == NoCompressionCodec && batch.isControlBatch)
inPlaceAssignment = true
for (record <- batch.asScala)
if (sourceCodec != NoCompressionCodec && record.isCompressed)
throw new InvalidRecordException("Compressed outer record should not have an inner record with a " +
s"compression attribute set: $record")
if (targetCodec == ZStdCompressionCodec && interBrokerProtocolVersion < KAFKA_2_1_IV0)
throw new UnsupportedCompressionTypeException("Produce requests to inter.broker.protocol.version < 2.1 broker " + "are not allowed to use ZStandard compression")
validateRecord(batch, record, now, timestampType, timestampDiffMaxMs, compactedTopic)
uncompressedSizeInBytes += record.sizeInBytes()
if (batch.magic > RecordBatch.MAGIC_VALUE_V0 && toMagic > RecordBatch.MAGIC_VALUE_V0)
// Check if we need to overwrite offset
// No in place assignment situation 3
if (record.offset != expectedInnerOffset.getAndIncrement())
inPlaceAssignment = false
if (record.timestamp > maxTimestamp)
maxTimestamp = record.timestamp
// No in place assignment situation 4
if (!record.hasMagic(toMagic))
inPlaceAssignment = false
validatedRecords += record
//省略部分代码
这段代码的注释部分详细介绍了kafka在服务端需要进行压缩的4种情况,对其进行翻译,其实就是两种情况:
1、客户端与服务端端压缩算法不一致
2、客户端与服务端端的消息版本格式不一样,包括offset的表示方法、压缩处理方法
关于客户端与服务端压缩算法不一致,这个基本不会出现,因为服务端通常可以支持多种压缩算法,会根据客户端的压缩算法进行自动匹配。
最有可能的就是服务端与客户端端消息协议版本不一致,如果版本不一致,则需要在服务端重新偏移量,如果使用了压缩机制,则需要重新进行解压缩,然后计算位点,再进行压缩存储,性能消耗极大。
后面排查日志使用端,确实是客户端版本与服务端版本不一致导致,最终需要对客户端进行统一升级。
关于Kafka的压缩、日志偏移量,消息存储的分析,请持续关注 Kafka专栏 ,后续会持续更新,敬请期待。
本文首发:https://www.codingw.net/article?id=778
见字如面,我是威哥,一个从普通二本院校毕业,从未曾接触分布式、微服务、高并发到通过技术分享实现职场蜕变,成长为RocketMQ社区优秀布道师、大厂资深架构师,出版《RocketMQ技术内幕》一书,在CSDN中记录了我的成长历程,欢迎大家关注,私信,一起交流进步。
以上是关于生产环境kafka日志集群400W/tps就扛不住了的主要内容,如果未能解决你的问题,请参考以下文章