论文阅读自然语言生成(NLG)——基于plan思想的Data2Text任务实现
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读自然语言生成(NLG)——基于plan思想的Data2Text任务实现相关的知识,希望对你有一定的参考价值。
NLG方向可以算是NLP的一个分支,即自然语言生成,理解上data2text,image2text,doc2text都在这个范畴内。相对来说data2text是较为容易的一个任务,可以作为很多复杂NLG任务中处于最终一步的任务,因此它的重要性不言而喻。本文摘自ACL 2019录取的30篇知识图谱论文之一1904.03396,笔者做了较为详细的阅读标注仅供参考。
最近间歇性脑壳疼,是真的脑壳疼,生理上的疼。
论文标题:Step-by-Step: Separating Planning from Realization in Neural Data-to-Text Generation
论文下载地址:https://arxiv.org/abs/1904.03396
项目地址:https://github.com/AmitMY/chimera
Step-by-Step: Separating Planning from Realization in Neural Data-to-Text Generation
论文下载地址:https://arxiv.org/abs/1904.03396
项目地址: https://github.com/AmitMY/chimera
目录
- Abstract 摘要
- 1. 引语 Introduction
- 2. 方法概述 Overview of the Approach
- 3. 文本计划 Text Planning
- 4. 计划实现 Plan Realization
- 5. 实验配置 Experimental Setup
- 6. 实验与结果 Experiments and Results
- 7. 相关工作 Related Work
- 8. 总结
Abstract 摘要
- data2text生成任务在概念上可以分为两部分:
- 排序(ordering)
- 信息结构化(structuring)
- 最终生成用于描述data的流畅text
- 先进的神经生成系统将这两部分合并在一个end2end的可区分的(differentiable)系统中
- 本文提出将生成过程分割到一个象征性的“文本计划”(text-planning)阶段(stage)中
- 该阶段对本阶段输入完全信任
- 之后再跟进一个神经生成阶段中, 主要用于实现对data的描述
- 为了训练plan2text的生成器, 本文提出一种筛选高质量“文本计划”(text plans)的方法
- 本文基于WebNLG语料数据集的benchmark进行实现与验证
- 本文实验结果具有可依赖性与适当性, 并保持了流畅的输出结果
- 模型在BLEU-score与手动验证上都取得了更好的结果
- 模型可以对同一输入做到不同输出
- 为文本生成架构的研究铺路
1. 引语 Introduction
- WebNLG语料数据集的结构:
- 输入: John, birthPlace, London; John, employer, IBM;
- 输出:
- John, who was born in London, works for IBM;
- John, who works for IBM, was born in London;
- London is the birthplace of John, who works for IBM;
- IBM employs John, who was born in London;
- 难点: 按照什么顺序描述所有data, 按照什么样的方式表示每条data
- 当然也可以分成两个句子: John works for IBM. John was born in London;
- 总体来说, 如何排序data, 排序entity, 以及句子分割可以引出12种不同的架构
- 另一个维度的变体是在给定架构下如何将信息动词化:
- John works for IBM and was born in London;
- John is employed by IBM. He was born in London;
- 对于这两个维度, 本文的解决方案:
- 如何信息结构化: 本文使用“文本计划”(text planning)
- 如何动词化一个plan: 本文使用“计划实现”(plan realization)
- planning与realization的区别是传统自然语言生成(NLG)是否生效的核心问题
- 不过目前的潮流倾向于忽视这个区别
- 而将问题转为end2end, 即将data作为输入映射成输出text, 使用encoder-decoder架构
- 神经方法在输出流畅性上表现卓越, 但是仍然应当考虑长句输出的内联性
- 这往往可能导致输出结果与输入并非一个意思, 如省略, 重复, 甚至改变原来的facts
- NLG社区将这种错误视为adequacy或correctness的问题
- 与模板方法相比:
- 神经方法的输出的置信度往往较低, 即不能完全表示原意, 且很难控制输出的结构
- 但是在语言细节的捕捉上做得好
- 我们提出一种直接的, 象征性的, text-planning阶段
- 该阶段的输出用于输入神经生成系统
- text planner决定信息结构并清楚表达出来, 本文将使用一个序列的的排好序的树来表示
- 该阶段是象征性的, 用于确保模型输出保持置信度并且完成输入fact的全部内容
- 一旦plan被决定, 神经生成系统就会将它输出为流畅的自然语言文本
- 我们的方法在WebNLG语料库上的表现与一般的神经系统一样流畅, 但是具有更高的置信度与完成度
- 模型可以控制输出的结构并且可以有多种不同的输出
- 项目地址在本markdown文件第二行
2. 方法概述 Overview of the Approach
- 任务描述 Task Description
- 我们的方法用于从RDF集合的输入生成文本
- 所有用于输入的RDF三元组可以视为图: entity为节点, RDF关系是有向且已标注的边
- 每一条RDF三元组与一条或多条参考text对应, 用于描述该RDF三元组的信息
- 参考text为单独的句子或句子序列
- 抽象化表示:
- 输入的图G有三元组(s_i,r_i,o_i)的集合构成, 分别表示subject, relation, object
- s_i与o_i属于DBPedia实体集合, r_i属于已标注的DBPedia关系集合
- (G,参考text)为输入输出对, 同样的G可能有多个reference
- 方法概述 Method Overview
- 生成过程分为两部分:
- 文本计划(text planning)
- 句子实现(sentence realization)
- 给定输入G, 生成一个计划plan(G)用于分割G中的所有fact得到若干句子, 该data2plan的步骤是非神经的, 可以使用数据驱动的打分函数来排序可能的建议, 然后选取打分高的结果
- 根据plan申城一个个句子, plan2sentence步骤使用NMT系统
- 基于plan的架构中, 对于(G,参考text)的输入输出对会额外添加一个对应的plan, 构成新的数据集, 用于训练plan2text与plan-selection方法
2.3 总体应用 General Applicability
3. 文本计划 Text Planning
- 计划架构 Plan structure
- plan捕捉fact2sentence的分割以及sentence的顺序
- sentence中不同fact的顺序
- fact中不同entity的顺序, 称relation的方向(direction)
- 如(A,location,B)可以视为A is located in B或者B is the location of A
- 不同fact共用同一entity时的语句架构, 有链式, 平行(sibling), 混合架构三种
- 链式架构: John lives in London, the capital of England
- 平行架构: John lives in London and works as a bartender
- 混合架构: John lives in London, the capital of England, and works as a bartender
- 文本计划使用一个序列的句子计划建模, 再按顺序实现
- 每个句子计划使用排序树建模, 确定信息实现的架构, 使用树的架构便于不同fact间共享entity的连贯性
- 文本计划假设每个entity仅在一句话中出现一次, 这也是WebNLG语料库的特点
- plan的示例在Figure 1.b
- (h,l_1,m),(m,l_2,x)代表一组连贯的facts共享中间的entity
- John lives in London, the capital of England
- (h,l_1,m1),(h,l_2,m_2)代表一组连贯的facts共享同样的entity
- John lives in London and works as a bartender
- (h,l_1,m),(m,l_2,x)代表一组连贯的facts共享中间的entity
- 穷举生成 Exhaustive generation
- 对于小的输入图G可以直接把所有可能的计划全部列举出来, 如在每个节点做一次DFS来得到各种不同顺序的子女节点排序方式
- 特别地如果图G存在环(WebNLG语料库中有0.4%的图存在环, 本文对这些进行忽略), 一定要确保是无环图
3.1 训练数据添加plan
- 训练集中只有references而没有plans, 因此需要设计一种方法以恢复潜在的plans, 得到新数据集(G,ref,T)三元组, 即原始数据, 参考文本以及文本计划
- 定义参考文本ref与文本计划T是一致的, 当且仅当
- ref中每一个句子的facts都是用T中的计划组合的
- 对应的句子与句子计划, entity的顺序是相同的
- 将ref与plan匹配基于如下结论:
- 确认参考文本中的entities以及输入中的entities相对于fact是独特的, 这件事是相对容易的
- 确认句子分割相对容易
- 参考文本与它的匹配计划一定共享相同的entities以相同的顺序和相同的句子分割
- 句子分割一致性 Sentence split consistency
- 定义三元组集合与句子是潜在一致(potentially consistent)的, 当且仅当每个三元组包含至少一个来自句子的entity(要么是主语要么是宾语), 且每个句子中的每个entity至少被一个三元组覆盖到
- 给定参考文本, 使用NLTK分词后, 寻找G的一个不交的划分, 使得每个划分的集合与一个对应的句子一致
- 对于G的一个不交的划分, 考虑穷举法
- 事实排序一致性 Facts order consistency
- 定义一个参考文本与一个来自对应RDF的句子计划是匹配的, 当且仅当句子中的entities集合与plan是相同的, 且所有的entity以相同顺序出现
- 事实上还需要指定G集合中中任意两个entity间只能有一个关系, 这在WebNLG6940的样本中仅15个不满足该条件, 因此可以忽略
- 基于此可以将每个句子和计划都视为entity的序列, 确认序列匹配即可
- 但是这种规则的问题在于映射text与plan中的entity并非平凡
- entity存在变体: A.F.C Fylde v.s. AFC Fylde
- entity同义但需要外部知识: UK conservative party v.s. the Tories
- entity存在代词指代相同情况: them, he, the former
- 因此需要放款匹配的规则, 本文考虑文本中可能的未知entity ???
- 具体地, 句子计划用一个entity序列(pe_1,…,pe_k)表示, 每个句子用(se_1,…,se_m)表示, m<=k
- 注意我们将plan中的entity与sentence中的entity匹配使用Levenshtein方法, 手动调整阈值来模糊匹配
- 特别地匹配日期型的entity时使用chrono-python包来将日期转为自然语言文本
- 然后定义句子与句子计划一致, 若以下两个条件成立:
- (se_1,…,se_m)是(pe_1,…,pe_k)的一个子序列
- plan中剩下的entity都已经在plan中之前出现过了
- 该条件考虑这样一个事实: 大部分未明确的entity都是代词或者相似的非词汇话的指代表达(如the former, the latter)
- 这种情况下就一定是指代前文中的某个词汇了
3.2 测试时间计划选择 Test-time Plan Selection
- 设计打分机制来选择最可能的那个plan来用于最终实现
- 打分机制是一种Product-of-Experts(PoE)模型
- 每个experts是一个针对plan中某个property的条件概率估计
- 条件概率是训练集上plan的MLE估计
- 本文使用了如下几个experts:
- 关系方向 Relation direction
- WebNLG中的manager有68%的表示为is managed by, 此外还可能表示为is the manager of
- 基于此表示为P_dir(d=<–)|manager)=0.68
- 全局方向 Global direction
- 虽然逆向的关系出现概率普遍低于50%, 但是长句中仍然有一两个的关系是逆向的
- 考虑条件概率p_gd(nr=n|G), 即观察n条逆向边在一个输入G中, 包含|G|个三元组
- 分割趋势 Splitting tendencies
- 对于每个输入size, 我们跟踪所有可能将facts集合分割成特定大小子集的方法
- 如统计p_s(s=[3,2,2]|7)的值, 即输入size为7, 后来分成了3+2+2
- 关系转移 Relation transitions
- 考虑每个句子计划作为一个关系类别的序列: (r_1,r_2,…,r_k,EOS), EOS用于标记序列末
- 计算这个序列的markov转移概率: p_trans(r_1,r_2,…,r_k,EOS) = 连乘k个转移概率
- 所有可能的plan都用上述转移公式计算概率
- 注意一个包含n个三元组的输入将会生成O(2^(2n)+n*n!)个可能的plan
- 但是对于WebNLG中大部分n<=7, 效率尚可, 当n很大时即图G很大, 仍需要更优的打分机制, 留作未来工作
- 打分机制用于抽取较优的plan
- 可能替代 Possible Alternatives
- 除了单一的plan选择, 也可以实现多个plan, 如多个高分plan
- 引入用户控制, 即用户决定需要多少个句子, 需要强调的entity以及顺序等, 这些留作未来工作
- 同一张图不同输出的示例, 各有不同的强调:
- The Dessert Bionico requires Granola as one of its ingredients and originates from the Jalisco region of Mexico
- Bionico is a food found in the Mexico region Jalisco. The Dessert Bionico requires Granola as an ingredient.
- Bionico contains Granola and is served as a Dessert. Bionico is a food found in the region of Jalisco, Mexico.
- 关系方向 Relation direction
4. 计划实现 Plan Realization
- 计划实现本文使用现成的vanilla-NMT系统来将plans翻译成文本
- 文本计划输入NMT系统, 需要将预先排序遍历树, 这边不是很明白, 总之这个现成的NMT系统的输入是有要求的
- 训练细节:
- NMT系统使用了复制注意力机制(copy-attention mechanism)与预训练的Glove.6B词向量
- 预训练的词向量是用于初始化plans中的关系节点, 以及参考文本中的节点
- 生成细节:
- 每个句子计划单独翻译
- 一旦文本生成, 在输入图G中用完整的entity字符串替换掉entity节点;
- 所有日期型字符串转化成July 4th, 1776的形式
- 所有带单位的数字型字符串删除引号和括号, “5”(minutes)转为5 minutes
5. 实验配置 Experimental Setup
- WebNLG挑战包含将RDF三元组集合映射成文本, 包括表达生成, 聚合, 非词汇化, 表面实现, 句子分割
- 每个样本输入不超过7个三元组
- 测试集分为AB两部分, 前者用于调优, 后者用于打榜
- WebNLG语料库包含18102个RDF文本三元组
- plan-enhenced语料库包含13828个plan2text对
- 对比系统 Compared Systems
- 本文在WebNLG挑战里最好的提交结果与Melbourne(一个end2end的系统取得了最高评分在所有类别的自动评价机制下以及UPF-FORGe, 一种传统的基于语法的NLG系统评分)比较
- 此外本文还构建了一个end2end的基线模型
- 该模型使用一个set编码器, LSTM解码器, 注意力机制, 复制注意机制, 一个神经checklist模型
- entity-dropout和checklist两大元素是与之前其他系统关键的不同之处
- 本文称之为强神经(StrongNeural)
6. 实验与结果 Experiments and Results
本文的模型称为BestPlan
6.1 自动化评价机制
- 主流的自动化评价机制:
- BLEU
- Meteor
- ROUGE_L
- CIDEr
- 实验结果表明本文的模型表现都是最好, 详见Table 1
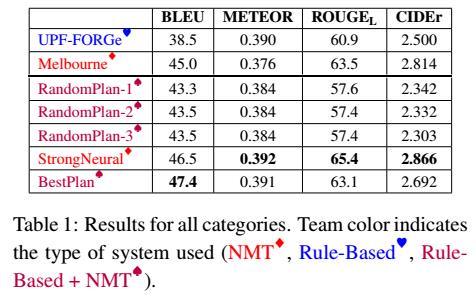
6.2 手工评价机制
- 置信度 Faithfulness
- 流畅度 Fluency
- 详见Figure 4

6.3 计划实现连贯性 Plan Realization Consistency
- 实现每个句子计划并用两个标准来检验
- 是否所有plan中的entity都出现在了realization中
- plan与realization中的entity是否以相同顺序出现
- 详见Table 4
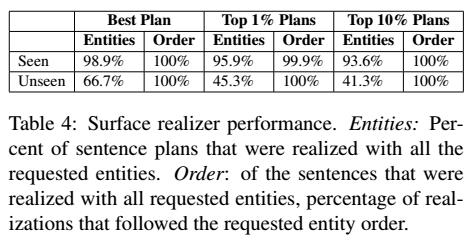
7. 相关工作 Related Work
- 文本计划是传统NLG中的一个主要成分
- Stent e al(2004)展示了一种穷举所有plan并使用RankBoost算法来排序的方法
- 本文的plan selection算法相较太平实, 可以改进
- 很多生成系统都基于"黑盒子"NMT系统
- 从结构化数据生成文本往往需要知识基础(如知识图谱), 我们的模型以后可以用checklist模型进一步改进
- 更复杂的任务: 文档级别的planning
8. 总结
- 一言以蔽之, 我们做得比别人好
以上是关于论文阅读自然语言生成(NLG)——基于plan思想的Data2Text任务实现的主要内容,如果未能解决你的问题,请参考以下文章