服务器产生大量 TIME_WAIT 状态的排查过程
Posted linux大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务器产生大量 TIME_WAIT 状态的排查过程相关的知识,希望对你有一定的参考价值。
一、概述
(一)现象
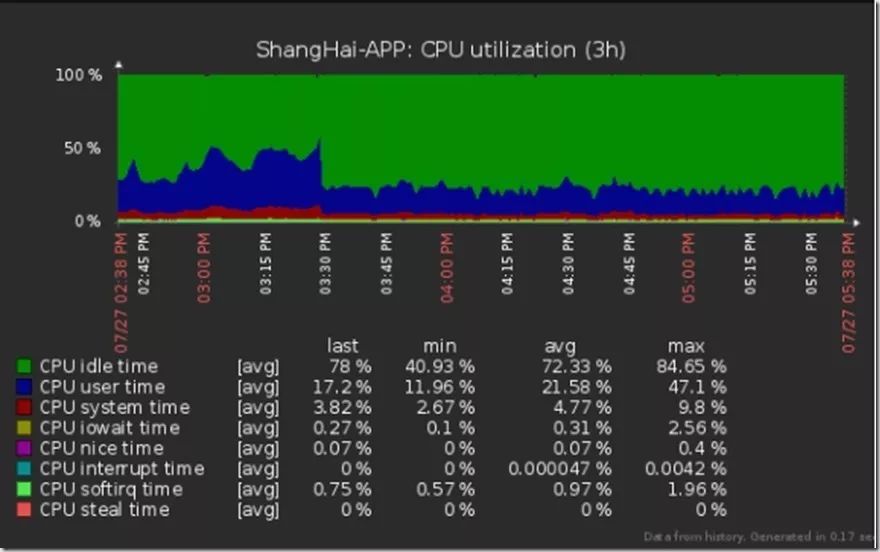
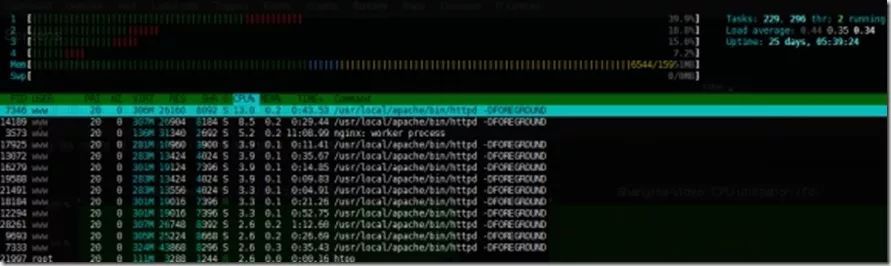
服务器有两个现象,第一是tcp连接数不多,不超过10个,但是time_wait状态的2000。第二个按照以往的性质,在很少用户访问的情况下,服务器的资源几乎没有使用,比如CPU,不超过5%。现在没有什么用户的的情况下,CPU损耗坚持在40%左右,夜间也不停歇。里面运行着好几个web项目,都用docker启动的容器分开。

(二)相关知识
tcp连接有3次握手,断开有四次挥手。
三次握手中第一次,是主动端发出SYN信号给正在listen的被动端,然后自己变成了SYN-SENT状态;第二次是被动端发送ACK确认收到信号和SYN信号;第三次是主动端发出ACK信号确认已经收到了被动端的SYN。然后双双进入了enblished状态,便是已经连接成功。
四次挥手中的第一次就是主动端断开,发送FIN信号,变成FIN-WAIT-1状态;第二次是被动方收到FIN信号,就变成CLOSE-WAIT状态,然后赶紧发送ACK信号给主动方确认,这是时候主动方变为FIN-WAIT-2状态;第三次还是被动方等自己的应用断开连接的时候,发送FIN信号给主动方,被动方的状态变成LAST-ACK;第四次是主动方收到被动方的FIN信号,然后发送的ACK信号,瞬间自己变成TIME-WAIT状态,然后等待回收。
就是说,谁有TIME-WAIT,谁就是主动方。这点可以排除用户频繁关闭网页的可能。意思就是说这都是服务器主动请求断开连接的,而TIME-WAIT状态的链接也没有回收。
二、问题推测
(一)网络
网络上面的就是网络不好,或者被攻击。
(二)应用
中间件的参数不对,导致有中间件断开的连接,或者应用程序错误造成的主动断开连接。或者也是应用方面导致消耗资源太多。
相关视频推荐
tcpip,accept,11个状态,细枝末节的秘密,还有哪些你不知道
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,nginx,ZeroMQ,mysql,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
三、排查
这个服务器有三个项目,每个项目的架构都是lanmp。问题复杂在于服务器里面好几个项目,每个项目用都一个反向代理。好的一点是后端是docker容器,分开的。
(一)TCP连接上的IP
1.下图是容器的IP
命令:
for i in $(docker ps|awk 'NR!=1 print $NF');do echo -e $i "\\c";docker inspect --format ' .NetworkSettings.IPAddress ' $i;done

2.下图是连接中本地的IP
命令:
netstat -tn|grep TIME_WAIT|awk 'print $4'|sort|uniq -c|sort -nr|head
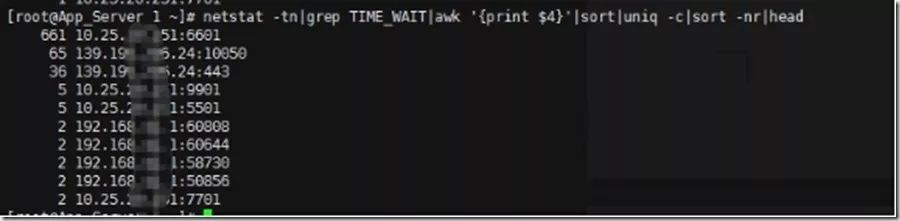
排名第一这个是我们本地IP,6601是api项目的监听端口,从这里可以看出在所欲的TIME_WAIT状态的TCP里面,API项目的后端是被请求最多的那个。估计反向代理服务器也被请求了很多。
3.下图是连接本地API项目的主动IP
命令:
netstat -ant|grep 10.25.20.251:6601
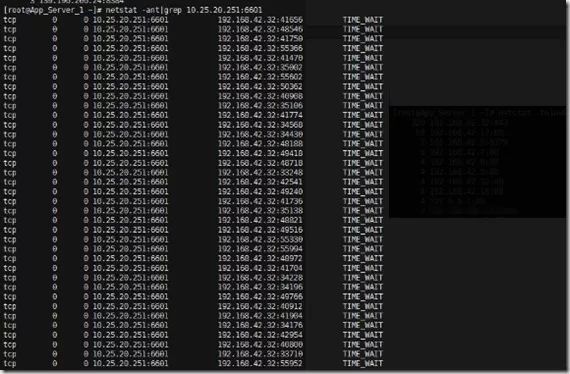
途中可以看出,请求连接API后端的全部都是nginx的IP,这也很容易理解,nginx反向代理是入口嘛。下面就看看到底是谁对nginx发出请求。
4.下图是连接中外地的IP
命令:
netstat -tn|awk 'print $5'|sort|uniq -c|sort -nr|head
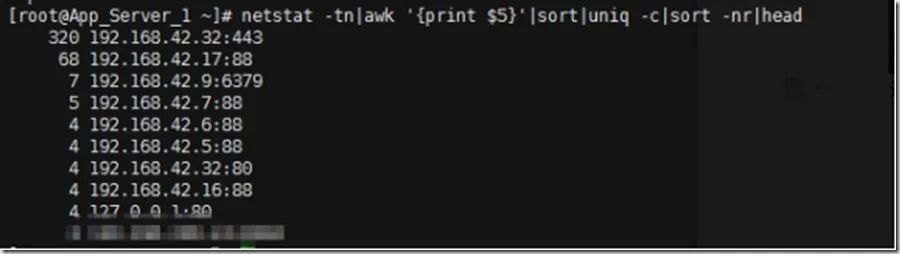
对API的请求是600,对nginx的请求是300,说明所有的TIME-WAIT,一部分是请求nginx的,一部分是nginx请求API的。
5.下图是展示到底是对请求了API的web前端nginx
命令:
netstat -ant|grep 192.168.42.32:443
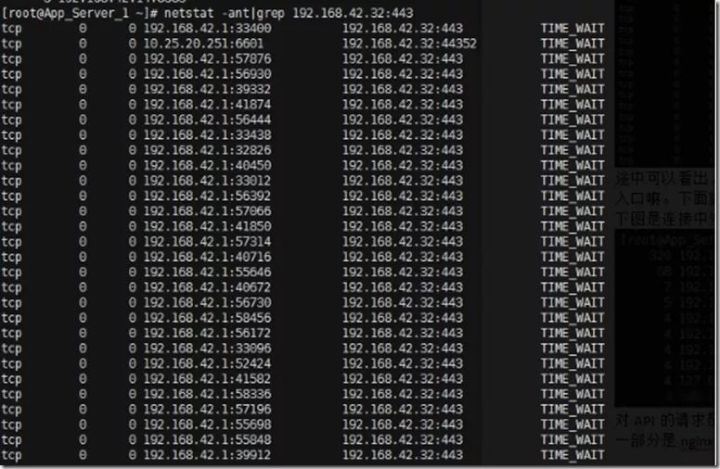
原来是192.168.42.1这个IP的请求。其实192.168.42.1这个IP是docker的虚拟网卡的IP,作为全部容器的网关,也就是说反正这就是这些容器发出的请求,但是不能确定是哪一个。
综上所述,可以排除网络问题,中间件apache的参数没有改,但是对web前端nginx的请求那么多,可以说明问题不是出现在apache的请求上面。那就往代码错误方面考虑。
(二)宿主机上的容器
1.应用和网络的关系
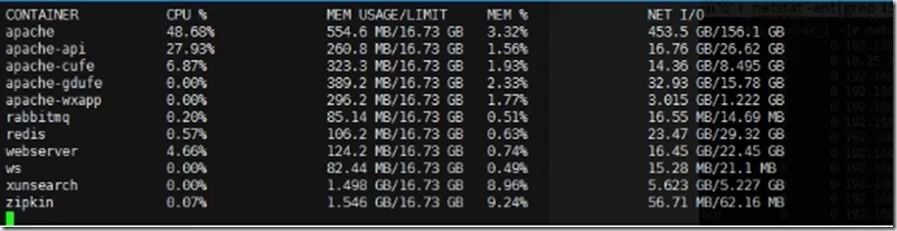
可能TIME-WAIT的问题就是后端程序乱发请求,apache是主项目的后端容器,apache-api就是api的后端程序。webserver占用的CPU上升,刚好就说明容器使用的系统资源就是由这种请求引起的。下面用tail看看api的access日志。
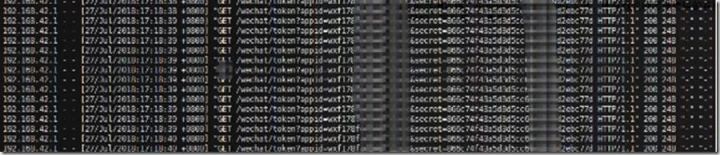
实时监测,发现API一秒钟被请求12次左右,根据业务性质和docker的状态显示,可以断定是主项目的循环请求造成的系统资源内耗。而每次请求API项目就返回了access_token,API返回数据之后就发出断开信号,逻辑和现象很符合,也可以断定TIME_WAIT的状态也是这请求引起。而TIME_WAIT不是不回收,而是回收了,但不断的生成。
以上是关于服务器产生大量 TIME_WAIT 状态的排查过程的主要内容,如果未能解决你的问题,请参考以下文章