训练线性回归模型 --- “闭式”解方法梯度下降(GD)
Posted 劳埃德·福杰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了训练线性回归模型 --- “闭式”解方法梯度下降(GD)相关的知识,希望对你有一定的参考价值。
1.训练前你需要了解
简单说,线性模型就是对输入特征加权求和,再加上一个我们称为偏置项(也称为截距项)的常数

向量化的形式:

训练模型就是设置模型参数直到模型最拟合训练集的过程。
常见的性能指标:性能指标是均方根误差(RMSE)
在实践中,将均方误差(MSE)最小化比最小化RMSE更为简单,二者效果相同
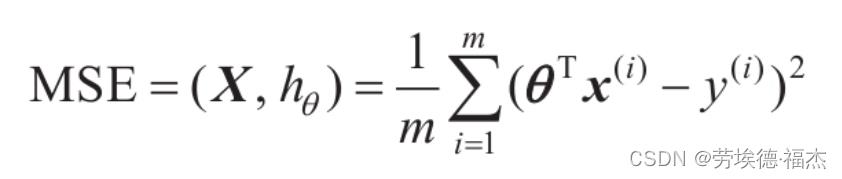
上面的MSE就是所谓的成本函数, 训练模型的目的就是使这个成本函数最小化
训练模型的方式有如下两种:“闭式”解方法、梯度下降(GD)
2.“闭式”解方法(直接求θ的方程)

我们针对 y=4+3x1+高斯噪声 这个模型来测试一下这个公式
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
X = 2 * np.random.rand(100, 1) # 生成100x1个随机数,随机数取值范围为[0,2)
y = 4 + 3 * X + np.random.randn(100, 1) # y=4+3x1+高斯噪声
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
X_b = np.c_[np.ones((100, 1)), X] # 特征向量增加一个x0,x0始终为1,和偏差项θ相对应
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) # np.linalg.inv用于对矩阵求逆
theta_best
# 输出:array([[3.74930688],[3.06809202]])
# 你也可以直接用Scikit-Learn中的线性回归模型,拿到模型的参数
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
lin_reg.intercept_, lin_reg.coef_
# 输出:(array([3.74930688]), array([[3.06809202]]))y=4+3x1+高斯噪声这个模型中的θ0=4,θ1=3
我们得到的是θ0=3.74930688,θ1=3.06809202
非常接近,噪声的存在使其不可能完全还原为原本的函数。
现在我们就可以利用theta_best,也就是 ,求预测值y=x
,求预测值y=x
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X_new] # 特征向量增加一个x0,x0始终为1,和偏差项θ相对应
y_predict = X_new_b.dot(theta_best) # 拿到预测值
# 绘制图形
plt.plot(X_new, y_predict, "r-", linewidth=2, label="Predictions")
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.legend(loc="upper left", fontsize=14)
plt.axis([0, 2, 0, 15])
plt.show()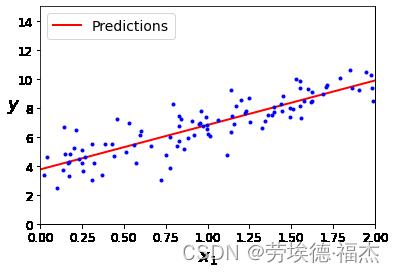
该方法的缺点:特征数量比较大时,该方程的计算将极其缓慢,因为计算 的逆时,是一个(n+1)×(n+1)的矩阵(n是特征数量)。
的逆时,是一个(n+1)×(n+1)的矩阵(n是特征数量)。
3.梯度下降(GD)
①简介
梯度下降的中心思想就是迭代地调整参数从而使成本函数最小化。
具体来说,首先使用一个随机的θ值(这被称为随机初始化),然后逐步改进,每次踏出一步,每一步都尝试降低一点成本函数(如MSE),直到算法收敛出一个最小值。

梯度下降中一个重要参数是每一步的步长,这取决于超参数学习率。
如果学习率太低,算法需要经过大量迭代才能收敛,这将耗费很长时间。
如果学习率太高,那你可能会越过山谷直接到达另一边,甚至有可能比之前的起点还要高。这会导致算法发散,值越来越大,最后无法找到好的解决方案。

下图展示了梯度下降的两个主要挑战:
如果随机初始化,算法从左侧起步,那么会收敛到一个局部最小值,而不是全局最小值。
如果算法从右侧起步,那么需要经过很长时间才能越过整片高原,如果你停下得太早,将永远达不到全局最小值。
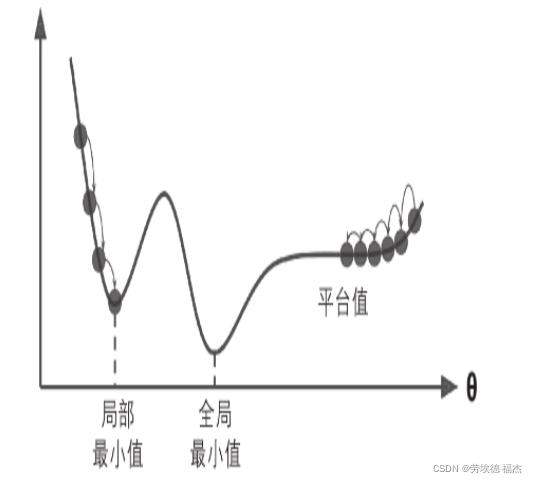
线性回归模型的MSE成本函数是个凸函数,也就是说,不存在局部最小值,只有一个全局最小值。它同时也是一个连续函数,所以斜率不会产生陡峭的变化。
这两点保证的结论是:即便是乱走,梯度下降都可以趋近到全局最小值。
应用梯度下降时,需要保证所有特征值的大小比例都差不多(比如使用Scikit-Learn的StandardScaler类),否则收敛的时间会长很多。
以下图的梯度下降为例,左边的训练集上特征1和特征2具有相同的数值规模,而右边的训练集上,特征1的值则比特征2要小得多(因为特征1的值较小,所以θ1需要更大的变化来影响成本函数,这就是为什么碗形会沿着θ1轴拉长)
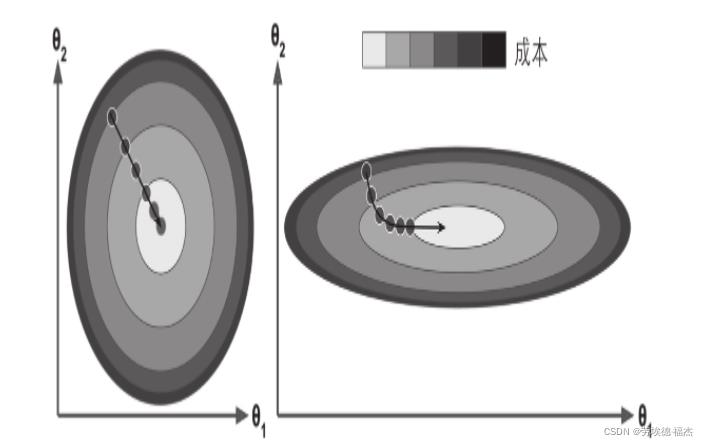
训练模型也就是搜寻使成本函数(在训练集上)最小化的参数组合。
这是模型参数空间层面上的搜索:模型的参数越多,这个空间的维度就越多,搜索就越难。
②批量梯度下降
要实现梯度下降,你需要计算每个模型关于参数θj的成本函数的梯度。
换言之,你需要计算的是如果改变θj,成本函数会改变多少。这被称为偏导数。
MSE成本函数的偏导数和梯度向量
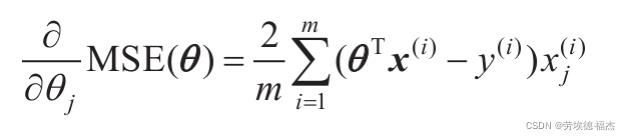
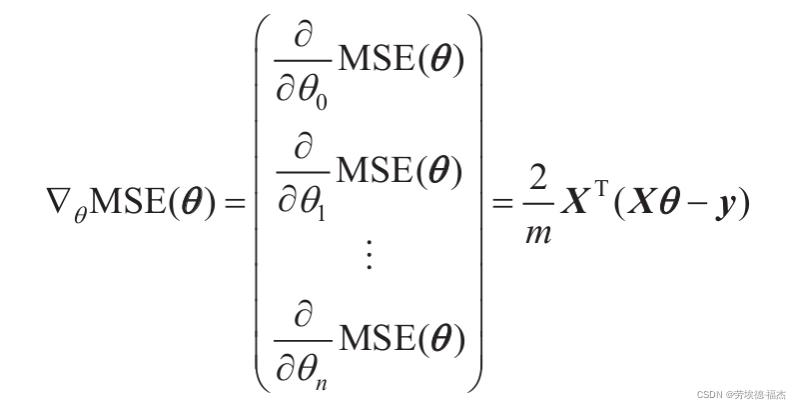
该算法会被称为批量梯度下降的原因:计算梯度下降的每一步都使用整批训练数据。
因此,面对非常庞大的训练集时,算法会变得极慢。
但是,该算法随特征数量扩展的表现比较好。如果要训练的线性模型拥有几十万个特征,使用梯度下降比标准方程或者SVD要快得多。
一旦有了梯度向量,哪个点向上,就朝反方向下坡。
也就是从θ中减去▽θMSE(θ),下坡步长的大小=梯度向量 x 学习率η
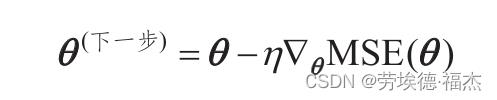
eta = 0.1 # 学习率(learning rate)
n_iterations = 1000
m = 100
theta = np.random.randn(2,1) # 随机初始化
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
theta # 输出:array([[4.01614681], [2.96463934]])下面我们看看三种不同学习率的效果
theta_path_bgd = []
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.plot(X, y, "b.")
n_iterations = 1000
for iteration in range(n_iterations):
if iteration < 10:
y_predict = X_new_b.dot(theta)
style = "b-" if iteration > 0 else "r--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
if theta_path is not None:
theta_path.append(theta)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 2, 0, 15])
plt.title(r"$\\eta = $".format(eta), fontsize=16)np.random.seed(42)
theta = np.random.randn(2,1) # 随机初始化
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(theta, eta=0.02)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd)
plt.subplot(133); plot_gradient_descent(theta, eta=0.5)
plt.show()
左图的学习率太低:算法最终还是能找到解决方法,就是需要太长时间。
中间图的学习率看起来非常棒:几次迭代就收敛出了最终解。
右图的学习率太高:算法发散,直接跳过了数据区域,并且每一步都离实际解决方案越来越远。
③随机梯度下降
批量梯度下降的主要问题是它要用整个训练集来计算每一步的梯度,所以训练集很大时,算法会特别慢。
与之相反的极端是随机梯度下降,每一步在训练集中随机选择一个实例,并且仅基于该单个实例来计算梯度。显然,这让算法变得快多了。
另一方面,由于算法的随机性质,它比批量梯度下降要不规则得多。成本函数将不再是缓缓降低直到抵达最小值,而是不断上上下下,但是从整体来看,还是在慢慢下降。随着时间的推移,最终会非常接近最小值,但是即使它到达了最小值,依旧还会持续反弹,永远不会停止。所以算法停下来的参数值肯定是足够好的,但不是最优的。

随机性的好处在于可以逃离局部最优,但缺点是永远定位不出最小值。
解决这个困境:降低学习率。
开始的步长比较大(这有助于快速进展和逃离局部最小值),然后越来越小,让算法尽量靠近全局最小值。这个过程叫作模拟退火,因为它类似于冶金时熔化的金属慢慢冷却的退火过程。确定每个迭代学习率的函数叫作学习率调度。如果学习率降得太快,可能会陷入局部最小值,甚至是停留在走向最小值的半途中。如果学习率降得太慢,你需要太长时间才能跳到差不多最小值附近,如果提早结束训练,可能只得到一个次优的解决方案。
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1, random_state=42)
sgd_reg.fit(X, y.ravel()) # ravel()函数将数组拉成一维数组
sgd_reg.intercept_, sgd_reg.coef_
# 输出:(array([4.07555235]), array([3.03967254]))④小批量梯度下降
小批量梯度下降在称为小型批量的随机实例集上计算梯度。
小批量梯度下降优于随机梯度下降的地方:你可以通过矩阵操作的硬件优化来提高性能,特别是在使用GPU时。
小批量梯度下降最终将比随机梯度下降走得更接近最小值,但它可能很难摆脱局部最小值。
以上是关于训练线性回归模型 --- “闭式”解方法梯度下降(GD)的主要内容,如果未能解决你的问题,请参考以下文章