机器学习中常见的评价指标总结
Posted 非晚非晚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中常见的评价指标总结相关的知识,希望对你有一定的参考价值。
文章目录
1. 评价指标的种类
评价指标是建立在不同的机器学习任务上的,主要分为三大类:分类、回归和无监督。
学习中遇到的分类任务中的评价指标有准确率(Accuracy)、TPR、FPR、Recall、Precision、F-score、MAP、ROC曲线和AUC等,回归任务中的指标有MSE、MAE等。
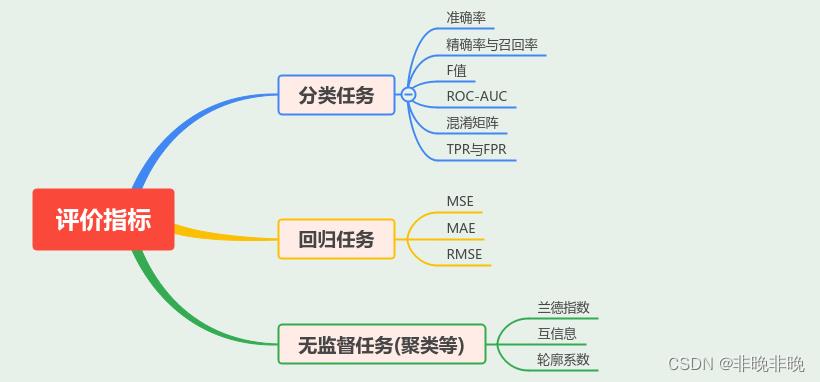
2. 分类任务的评价指标
2.1 分类任务的一些概念

如上图所示,绿颜色的为GT Box(ground truth box),红颜色的Predict Box。如果要正确检测出图中的猫和狗,那怎么才能算是正确的检测呢?下边的这三个标准都是需要看的:
- GT与预测框IoU是否大于阈值
- 预测的类别是否正确?
- 置信度是否大于阈值?
(1) 交并率(IoU, Intersection over Union)
IoU的作用是评价两个矩形框之间的相似性,在目标检测中是度量两个检测框的交叠程度,它的计算公式如下:
a
r
e
a
(
B
g
t
∩
B
p
)
a
r
e
a
(
B
g
t
∪
B
p
)
\\fracarea(B_gt\\cap B_p)area(B_gt\\cup B_p)
area(Bgt∪Bp)area(Bgt∩Bp)
其中 B g t B_gt Bgt表示GT Box, B p B_p Bp表示Predict Box。IOU的计算图示如下。
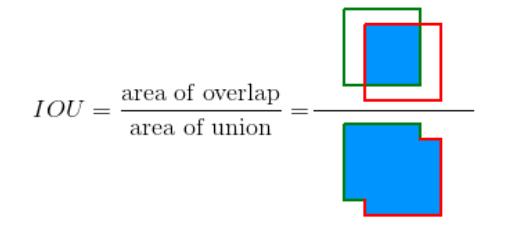
一般来说,这个IOU> 0.5 就可以被认为一个不错的结果了。
(2)NMS
NMS即non maximum suppression,也就是非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
所谓非极大值抑制:先假设有6个 预测矩形框 ,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A<B<C<D<E<F,NMS的流程如下:
- 从
最大概率矩形框F开始,分别判断A、B、C、D、E与F的重叠度IOU是否大于某个设定的阈值;- 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
- 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
- 重复这个过程,找到所有被保留下来的矩形框。
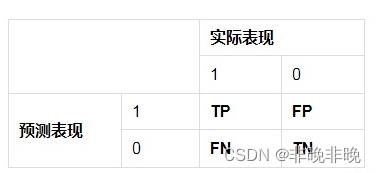
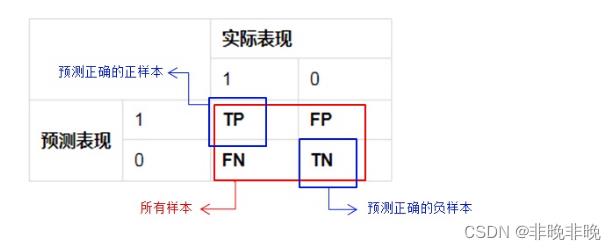
(3)TP、FP、FN、TN与混淆矩阵
- 混淆矩阵
混淆矩阵(Confusion Matrix)又被称为错误矩阵,通过它可以直观地观察到算法的效果。它的每一列是样本的预测分类,每一行是样本的真实分类(反过来也可以),顾名思义,它反映了分类结果的混淆程度。
混淆矩阵形式如下。
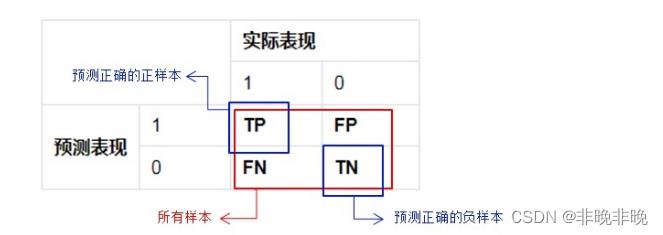
- P(Positive):代表1,表示
预测为正样本- N(Negative):代表0,表示
预测为负样本- T(True):代表
预测正确- F(False):代表
预测错误
下列Positive和Negative表示模型对样本预测的结果是正样本(正例)还是负样本(负例)。True和False表示预测的结果和真实结果是否相同。
| 概念 | 解释 | 备注 |
|---|---|---|
| True positives(TP) | 预测为 1,预测 正确,即 实际 1 | IoU>IOU,IOU一般取0.5 |
| False positives(FP) | 预测为 1,预测 错误,即 实际 0 | 误检 |
| False negatives(FN) | 预测为 0,预测 错误,即 实际 1 | 漏检 |
| True negatives(TN) | 预测为 0,预测 正确,即 实际 0 | 一般不会使用 |
2.2 准确率(Accuracy)
准确率(Accuracy)衡量的是分类正确的比例,它的计算公式简单直接,表示方法如下:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy = \\fracTP + TNTP + TN + FP + FN
Accuracy=TP+TN+FP+FNTP+TN
表示如下:
虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果,举个简单例子,比如正样本占90%,负样本占10%,如果我们全部预测为正样本,那么我们的准确率也能高达90%,但是这样的准确率是没有意义的。
2.3 精确率与召回率(Precision , Recall)
- 精确率(Precision)
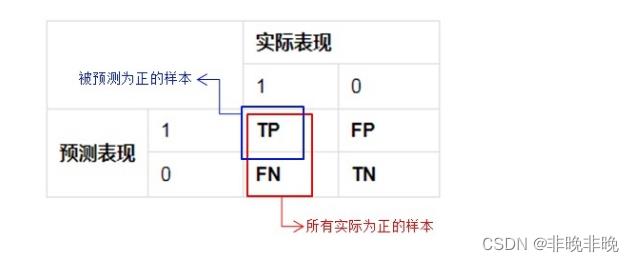
精准率(Precision)又叫查准率,它是指被 预测为正样本的检测框中预测正确的占比。
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \\fracTPTP + FP
Precision=TP+FPTP
精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
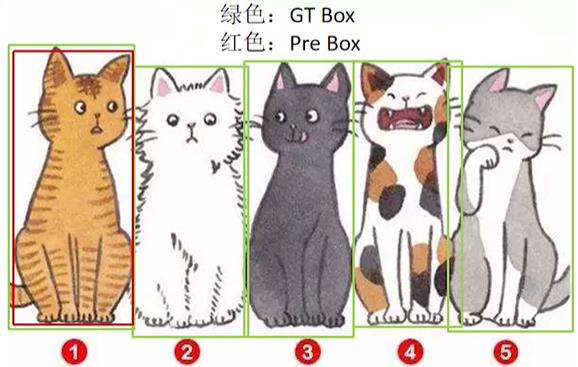
如上图所示,图中GT共有5只猫待检测,但实际上只检测出来了一只,而且这个检测是正确的。那这种情况下的查准率就是:
P
r
e
c
i
s
i
o
n
=
1
1
=
100
%
Precision = \\frac11= 100\\%
Precision=11=100%
- 召回率(Recall)
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,也就是 被正确检测出来的真实框占所有真实框(gt)的比例。
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \\fracTPTP + FN
Recall=TP+FNTP
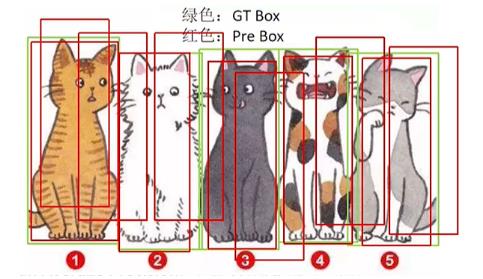
同样是上边有5个待检测的GT,这次得到了50个预测框,其中5个全部预测正确,这种情况下TP=5,漏检FN=0最终的查全率为:
R e c a l l = 5 5 + 0 = 100 % Recall = \\frac55+0=100\\% Recall=5+05=100%
2.4 F1分数
有时候我们需要在精确率与召回率间进行权衡,一种选择是画出精确率-召回率曲线(Precision-Recall Curve),曲线下的面积被称为AP分数(Average precision score);另外一种选择是计算
F
β
F_β
Fβ分数。
F
β
=
(
1
+
β
2
)
⋅
p
r
e
c
i
s
i
o
n
⋅
r
e
c
a
l
l
β
2
⋅
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
=
(
1
+
β
2
)
P
R
β
2
P
+
R
F_β=(1+β^2)⋅\\fracprecision⋅recallβ^2⋅precision+recall=\\frac(1+β^2)PRβ^2P+R
Fβ=(1+β2)⋅β2⋅precision+recallprecision⋅recall=β2P+R(1+β2)PR
当β=1称为F1分数,F1是精确率和召回率的调和均值。F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。
说明:当
β
>
1
β>1
β>1时,召回率的权重高于精确率,相反,当
β
<
1
β<1
β<1时精确率的权重高于召回率。
2.5 G分数
G分数是另一种统一精准率和召回率的系统性能评估标准。F分数是准确率和召回率的调和平均数,而G分数被定义为 准确率和召回率的几何平均数 。
G = p r e c i s i o n ∗ r e c a l l G = \\sqrtprecision*recall G=precision∗recall
2.6 AP和mAP
AP衡量的是学出来的模型在每个类别上的好坏,mAP(Mean Average Precision)衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
P-R曲线定义如下:根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测,每次计算出当前的P值和R值,如下图所示:
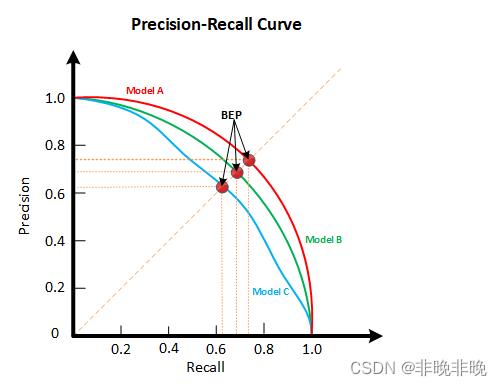
下面以3张图片为例,说明AP和mAP的计算过程:
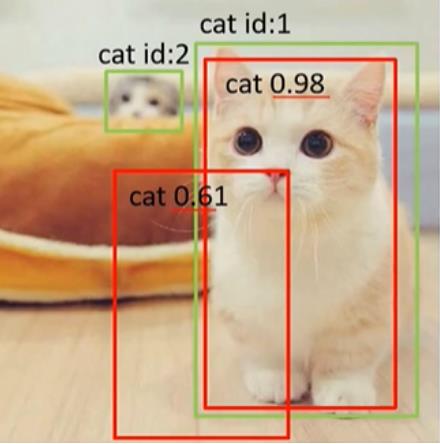
在所有的图片中(当前只有上图一张),待检测的目标的数量
n
u
m
o
b
=
2
num_ob=2
numob=2,上图中的检测情况如下表所示:
| GT id | Confidence | OB(IoU=0.5) |
|---|---|---|
| 1 | 0.98 | True |
| 1 | 0.61 | False |
该表中的顺序是按Confidence从高到低排序的,对于一个GT来说,只能有一个检测框为正确的检测。

加入第二张图片,此时待检测的目标数量
n
u
m
o
b
=
3
num_ob=3
numob=3,检测情况如下表所示。
| GT id | Confidence | OB(IoU=0.5) |
|---|---|---|
| 1 | 0.98 | True |
| 3 | 0.89 | True |
| 3 | 0.66 | False |
| 1 | 0.61 | False |
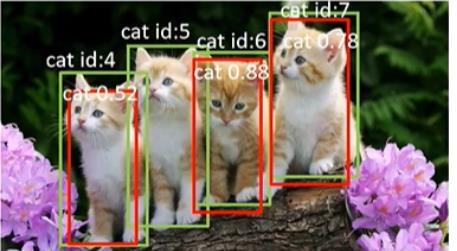
加入第三张图片后,再加上前两张中的待检测目标,共有 n u m o b = 7 num_ob=7 numob=7个目标需要检测,检测情况如下表所示:
| GT id | Confidence | OB(IoU=0.5) |
|---|---|---|
| 1 | 0.98 | True |
| 3 | 0.89 | True |
| 6 | 0.88 | True |
| 7 | 0.78 | True |
| 3 | 0.66 | False |
| 1 | 0.61 | False |
| 4 | 0.52 | True |
依次取Confidence的阈值为[0.98, 0.89, 0.88, 0.78, 0.66, 0.61, 0.52],计算对应的查准率和查全率如下表所示:
| Rank | Precision | Recall | Confidence thread |
|---|---|---|---|
| 1 | 1.0 | 0.14 | 0.98 |
| 2 | 1.0 | 0.28 | 0.89 |
| 3 | 1.0 | 0.42 | 0.88 |
| 4 | 1.0 | 0.57 | 0.78 |
| 5 | 0.80 | 0.57 | 0.66 |
| 6 | 0.66 | 0.57 | 0.61 |
| 7 | 0.71 | 0.71 | 0.52 |
以Confidence thread=0.52为例,此时的TP=5,误检FP=2,第一张和第三张两张图片共漏检FN=2,所以
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
=
5
5
+
2
=
0.71
Precision=\\fracTPTP+FP=\\frac55+2=0.71
Precision=TP+FPTP=5+25=0.71
R
e
c
a
l
l
=
T
P
T
P
+
F
N
=
5
5
+
2
=
0.71
Recall=\\fracTPTP+FN=\\frac55+2=0.71
Recal