带你整理面试过程中关于一致性Hash算法的相关知识点
Posted 南淮北安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你整理面试过程中关于一致性Hash算法的相关知识点相关的知识,希望对你有一定的参考价值。
文章目录
一、为什么要引入一致性哈希
比如我们有三个缓存服务器,用于缓存服务器编号为 0,1,2
现在有3万张图片需要缓存,为了分摊缓存的压力,我们肯定希望将这些图片均匀的分配到这三个服务器上
我们可以直接将这3万张图片均摊到三个服务器上,但是这样的话,因为是无规律,所以查找时就需要依次遍历所有的服务器,效率太低
所以可以利用 hash 算法或者取模算法,将图片的名称哈希计算,我们这里有3个服务器,然后将哈希后的结果对3取余,这样余数一定是0,1,2 ,对别对应三个服务器,此时我们查询时,就可以以图片名称当做 key 快速找到图片所在的服务器了

但是这种方式也存在问题,比如我们想要扩展服务器时,或者服务器某一台出现故障时,此时缓存服务器的数量发生了变化,也就是查找图片时计算得到的余数会发生变化(比如原来三台服务器,余数为0,1,2现在如果一台出现故障,那么余数就会变成0,1),导致大量图片的缓存位置失效,也就是出现缓存雪崩的现象
这就引入了一致性哈希
二、一致性哈希算法的基本概念
一致性哈希算法,也是取模的方法,只是普通的哈希算法是对服务器的数量取模,而哈希一致性算法是对 2 32 2^32 232 取模
这里可以把
2
32
2^32
232 想象成一个圆,也可以看作是一个由
2
32
2^32
232 个点组成的 hash 环
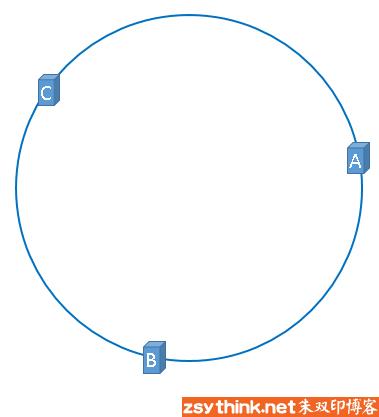
同样如果是上面的那个查找图片的例子,有三个服务器,每个服务器都有 IP 地址,对它们的IP地址进行哈希运算,然后再对 2 32 2^32 232 的取模,这样服务器就被映射到了 hash 环上了,也就是把服务器和hash环联系起来了
hash(服务器A的IP地址) % 2^32
hash(服务器B的IP地址) % 2^32
hash(服务器C的IP地址) % 2^32
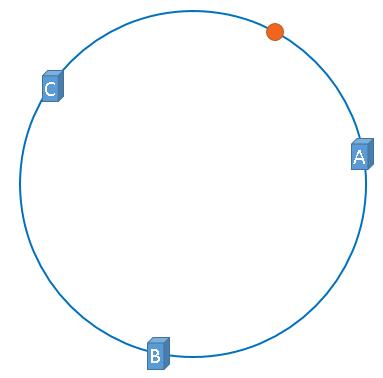
此时依然用图片的名称当做查找的 key ,对图片的名称哈希运算,然后对 2 32 2^32 232 取余,这样图片也会被映射到hash环上
具体存储的规则是,从图片映射的位置顺时针遇到的第一个服务器是哪个,就把图片缓存到哪个服务器上

所以,在服务器不变时,一张图片必定会被缓存到固定的服务器上,下次访问时,使用相同的方法进行计算即可算出图片在哪个服务器上
此时再发生服务器数量变化的情况,比如移除了一个第一个服务器,那么hash 环上还有两个服务器对应编号 1,2,那么对于第一个服务器存储的图片,缓存失效,但是对于另外两个服务器的图片并没有收到影响,也就是并不会出现缓存雪崩现象,唯一的变化就是原来存储在第一个图片再次缓存时会顺延缓存到下一个服务器上
所以一致性哈希算法具有很好的容错性和可扩展性
三、hash 环的偏斜
理想情况下,我们希望服务器均匀的映射到hash环上,但是当服务节点太少时,容易因为节点分布不均匀,造成hash环的偏斜
这就会造成大部分对象集中缓存在某一台服务器上,造成服务器没有被充分利用起来

可以利用虚拟节点解决这个问题,因为我们已经知道了hash环的偏斜是因为服务器节点太少,所以我们可以将现有的物理节点通过虚拟的方法复制出来,这些由实际节点复制而来的节点称为虚拟节点
比如原来的hash环上只有 a,b,c 三个服务器,每个节点虚拟一次就变成了 a,b,c,a,b,c这样的分配了,当然也可以虚拟更多次,这样便可以减小hash环偏斜带啦的影响

四、使用场景
在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求。然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的。
这种情况下就可以借助一致性Hash来处理。
详细学习可参考:白话解释 一致性 Hash 算法
参考文献:
【1】https://www.cnblogs.com/moonandstar08/p/5361453.html
【2】https://www.zsythink.net/archives/1182
以上是关于带你整理面试过程中关于一致性Hash算法的相关知识点的主要内容,如果未能解决你的问题,请参考以下文章