带你整理面试可能会问到的 聚簇索引和非聚簇索引
Posted 南淮北安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你整理面试可能会问到的 聚簇索引和非聚簇索引相关的知识,希望对你有一定的参考价值。
文章目录
一、聚簇索引
聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同
一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。
如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
如下图,叶节点中直接包含了具体数据。
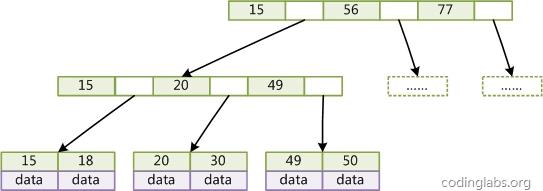
二、非聚簇索引
与聚集索引不同,非聚集索引的逻辑顺序与磁盘上行的物理存储顺序不同。磁盘上的数据可以随意分布,而通过非聚集索引,可以在逻辑上为数据排序。
如下图,叶节点没有包含具体的数据,而是包含了一个指向具体数据的指针
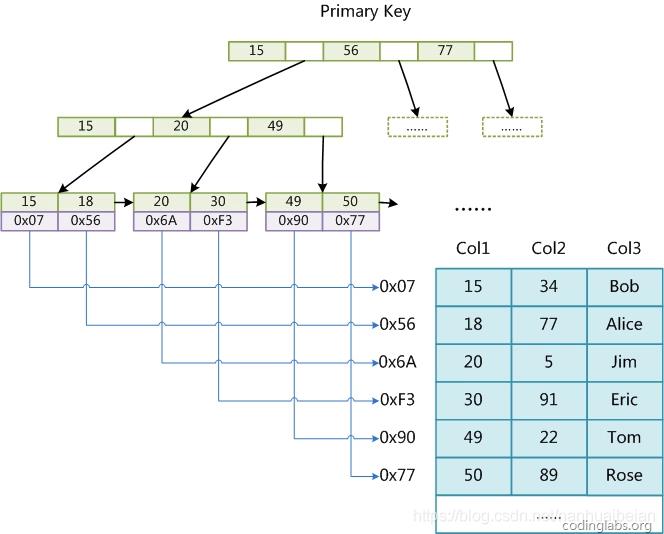
当索引通过二叉树的形式进行描述时,我们可以这样区分聚集与非聚集索引的区别:
聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针
三、InnoDB 的索引
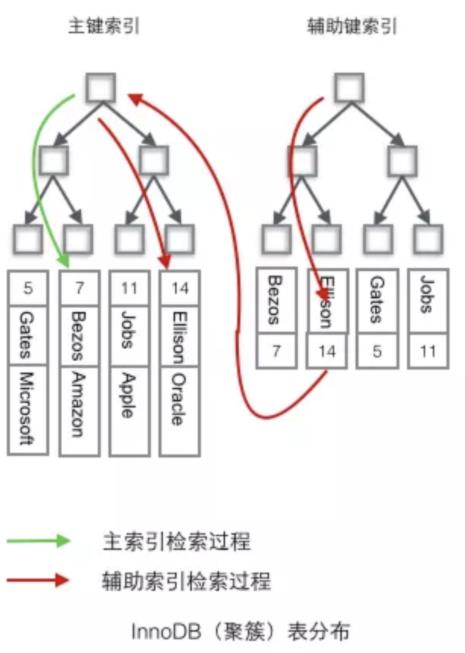
InnoDB 使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
若对 Name 列进行条件搜索,则需要两个步骤:
第一步在辅助索引B+树中检索 Name,到达其叶子节点获取对应的主键。
第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据(重点在于通过其他键需要建立辅助索引)
看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
1. 聚簇索引的优势
由于行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。
这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键 ID 来组织数据,获得数据更快。
辅助索引使用主键作为"指针"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"
也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响
2. 聚簇索引的劣势
(1)插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
(2)更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
(3)二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
(4)聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多
四、MyISM 的非聚簇索引
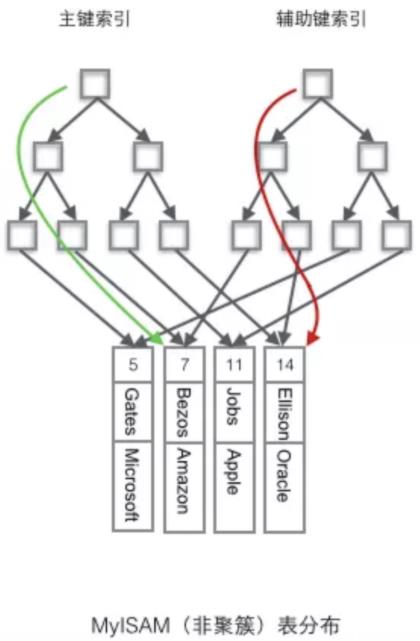
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。
表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
五、为什么主键通常建议使用自增 id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。
如果主键不是自增id,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。
但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停的寻道不停的旋转。
聚簇索引则只需一次I/O。(强烈的对比)
六、聚簇索引和非聚簇索引的使用场景
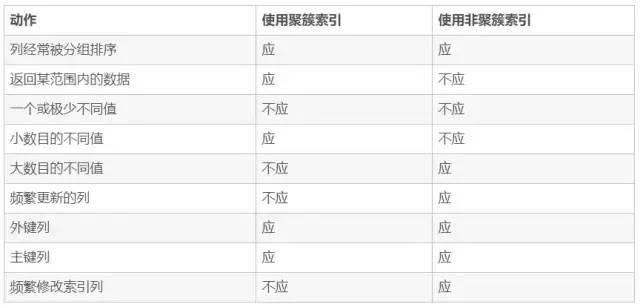
(1)聚簇索引适合排序
因为聚簇索引叶节点本身就是索引和数据按相同顺序放置在一起,索引序即是数据序,数据序即是索引序,所以很快。
非聚簇索引叶节点是保留了一个指向数据的指针,索引本身当然是排序的,但是数据并未排序,数据查询的时候需要消耗额外更多的I/O,所以较慢。
(2)聚簇索引适合取出一定范围的数据
因为聚簇索引的叶节点本身就是索引和数据按顺序存放的,索引的顺序就是数据的顺序,所以指定范围查询时,查找一次就可以得到一页紧挨着的数据
而非聚簇索引,逻辑有序,而物理空间上无序,所以,查询会消耗额外更多的I/O,更慢
(3)聚簇索引适合把相关的数据保存在一起
例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。
如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O
(4)非聚簇索引适合使用在频繁更新列时
非聚簇索引是物理上不连续,逻辑上连续,插入记录时不会引起数据顺序的重组
聚簇索引对表进行修改的速度较慢,因为为了保证表中记录的物理顺序和索引的顺序一致,会把记录插到数据页(叶子节点)的相应位置,所以会产生数据重排,而且插入新记录时为了维持B+树的特性,会频繁的分裂调整,影响了整体插入效率
七、mysql 聚簇索引的设定
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。
如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。
InnoDB 只聚集在同一个页面中的记录。包含相邻健值的页面可能相距甚远。
【参考】
https://www.huaweicloud.com/articles/317c9aab739c7f078d21d4eee51de3eb.html
https://blog.csdn.net/u014082714/article/details/106407206
以上是关于带你整理面试可能会问到的 聚簇索引和非聚簇索引的主要内容,如果未能解决你的问题,请参考以下文章